 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOReL and TOReL: Two Methods for Fully Offline Reinforcement Learning
May 28, 2025Sample efficiency remains a major obstacle for real world adoption of reinforcement learning (RL): success has been limited to settings where simulators provide access to essentially unlimited environment interactions, which in reality are typically costly or dangerous to obtain. Offline RL in principle offers a solution by exploiting offline data to learn a near-optimal policy before deployment. In practice, however, current offline RL methods rely on extensive online interactions for hyperparameter tuning, and have no reliable bound on their initial online performance. To address these two issues, we introduce two algorithms. Firstly, SOReL: an algorithm for safe offline reinforcement learning. Using only offline data, our Bayesian approach infers a posterior over environment dynamics to obtain a reliable estimate of the online performance via the posterior predictive uncertainty. Crucially, all hyperparameters are also tuned fully offline. Secondly, we introduce TOReL: a tuning for offline reinforcement learning algorithm that extends our information rate based offline hyperparameter tuning methods to general offline RL approaches. Our empirical evaluation confirms SOReL's ability to accurately estimate regret in the Bayesian setting whilst TOReL's offline hyperparameter tuning achieves competitive performance with the best online hyperparameter tuning methods using only offline data. Thus, SOReL and TOReL make a significant step towards safe and reliable offline RL, unlocking the potential for RL in the real world. Our implementations are publicly available: https://github.com/CWibault/sorel\_torel.
Adam on Local Time: Addressing Nonstationarity in RL with Relative Adam Timesteps
Dec 22, 2024In reinforcement learning (RL), it is common to apply techniques used broadly in machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL. In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser. We first analyse the impact of nonstationary gradient magnitude -- such as that caused by a change in target network -- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance. To address this, we introduce Adam-Rel. Rather than using the global timestep in the Adam update, Adam-Rel uses the local timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes. We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax. We then show that increases in gradient norm occur in RL in practice, and examine the differences between our theoretical model and the observed data.
Simplifying Deep Temporal Difference Learning
Jul 05, 2024



Q-learning played a foundational role in the field reinforcement learning (RL). However, TD algorithms with off-policy data, such as Q-learning, or nonlinear function approximation like deep neural networks require several additional tricks to stabilise training, primarily a replay buffer and target networks. Unfortunately, the delayed updating of frozen network parameters in the target network harms the sample efficiency and, similarly, the replay buffer introduces memory and implementation overheads. In this paper, we investigate whether it is possible to accelerate and simplify TD training while maintaining its stability. Our key theoretical result demonstrates for the first time that regularisation techniques such as LayerNorm can yield provably convergent TD algorithms without the need for a target network, even with off-policy data. Empirically, we find that online, parallelised sampling enabled by vectorised environments stabilises training without the need of a replay buffer. Motivated by these findings, we propose PQN, our simplified deep online Q-Learning algorithm. Surprisingly, this simple algorithm is competitive with more complex methods like: Rainbow in Atari, R2D2 in Hanabi, QMix in Smax, PPO-RNN in Craftax, and can be up to 50x faster than traditional DQN without sacrificing sample efficiency. In an era where PPO has become the go-to RL algorithm, PQN reestablishes Q-learning as a viable alternative. We make our code available at: https://github.com/mttga/purejaxql.
A Bayesian Solution To The Imitation Gap
Jun 29, 2024



In many real-world settings, an agent must learn to act in environments where no reward signal can be specified, but a set of expert demonstrations is available. Imitation learning (IL) is a popular framework for learning policies from such demonstrations. However, in some cases, differences in observability between the expert and the agent can give rise to an imitation gap such that the expert's policy is not optimal for the agent and a naive application of IL can fail catastrophically. In particular, if the expert observes the Markov state and the agent does not, then the expert will not demonstrate the information-gathering behavior needed by the agent but not the expert. In this paper, we propose a Bayesian solution to the Imitation Gap (BIG), first using the expert demonstrations, together with a prior specifying the cost of exploratory behavior that is not demonstrated, to infer a posterior over rewards with Bayesian inverse reinforcement learning (IRL). BIG then uses the reward posterior to learn a Bayes-optimal policy. Our experiments show that BIG, unlike IL, allows the agent to explore at test time when presented with an imitation gap, whilst still learning to behave optimally using expert demonstrations when no such gap exists.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
Bayesian Exploration Networks
Aug 24, 2023



Bayesian reinforcement learning (RL) offers a principled and elegant approach for sequential decision making under uncertainty. Most notably, Bayesian agents do not face an exploration/exploitation dilemma, a major pathology of frequentist methods. A key challenge for Bayesian RL is the computational complexity of learning Bayes-optimal policies, which is only tractable in toy domains. In this paper we propose a novel model-free approach to address this challenge. Rather than modelling uncertainty in high-dimensional state transition distributions as model-based approaches do, we model uncertainty in a one-dimensional Bellman operator. Our theoretical analysis reveals that existing model-free approaches either do not propagate epistemic uncertainty through the MDP or optimise over a set of contextual policies instead of all history-conditioned policies. Both approximations yield policies that can be arbitrarily Bayes-suboptimal. To overcome these issues, we introduce the Bayesian exploration network (BEN) which uses normalising flows to model both the aleatoric uncertainty (via density estimation) and epistemic uncertainty (via variational inference) in the Bellman operator. In the limit of complete optimisation, BEN learns true Bayes-optimal policies, but like in variational expectation-maximisation, partial optimisation renders our approach tractable. Empirical results demonstrate that BEN can learn true Bayes-optimal policies in tasks where existing model-free approaches fail.
Why Target Networks Stabilise Temporal Difference Methods
Feb 24, 2023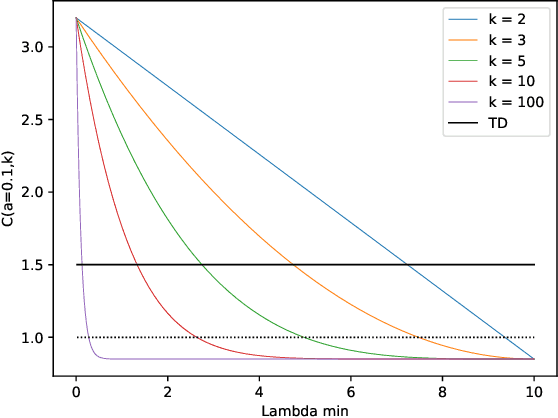
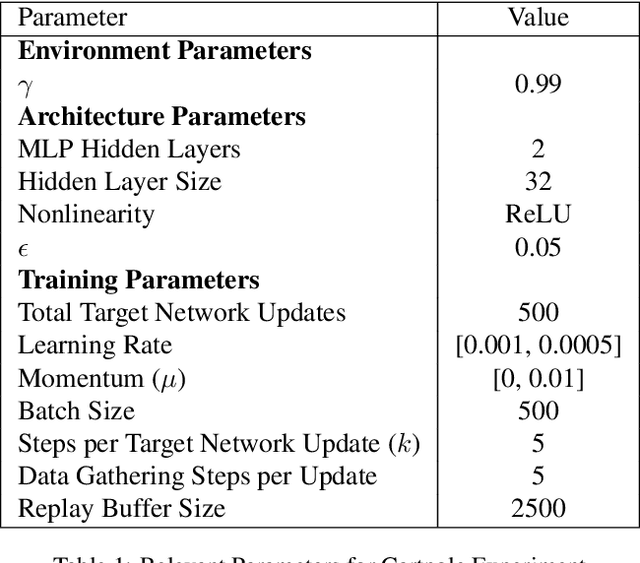
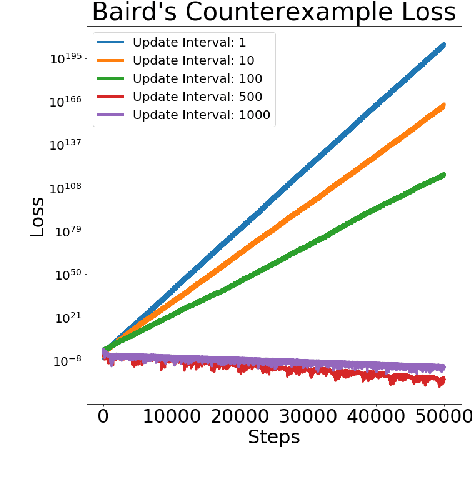
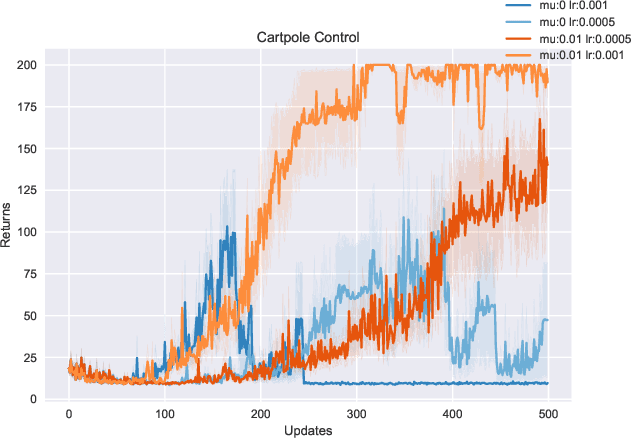
Integral to recent successes in deep reinforcement learning has been a class of temporal difference methods that use infrequently updated target values for policy evaluation in a Markov Decision Process. Yet a complete theoretical explanation for the effectiveness of target networks remains elusive. In this work, we provide an analysis of this popular class of algorithms, to finally answer the question: `why do target networks stabilise TD learning'? To do so, we formalise the notion of a partially fitted policy evaluation method, which describes the use of target networks and bridges the gap between fitted methods and semigradient temporal difference algorithms. Using this framework we are able to uniquely characterise the so-called deadly triad - the use of TD updates with (nonlinear) function approximation and off-policy data - which often leads to nonconvergent algorithms. This insight leads us to conclude that the use of target networks can mitigate the effects of poor conditioning in the Jacobian of the TD update. Instead, we show that under mild regularity conditions and a well tuned target network update frequency, convergence can be guaranteed even in the extremely challenging off-policy sampling and nonlinear function approximation setting.