 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Deep Temporal Difference Learning
Jul 05, 2024



Q-learning played a foundational role in the field reinforcement learning (RL). However, TD algorithms with off-policy data, such as Q-learning, or nonlinear function approximation like deep neural networks require several additional tricks to stabilise training, primarily a replay buffer and target networks. Unfortunately, the delayed updating of frozen network parameters in the target network harms the sample efficiency and, similarly, the replay buffer introduces memory and implementation overheads. In this paper, we investigate whether it is possible to accelerate and simplify TD training while maintaining its stability. Our key theoretical result demonstrates for the first time that regularisation techniques such as LayerNorm can yield provably convergent TD algorithms without the need for a target network, even with off-policy data. Empirically, we find that online, parallelised sampling enabled by vectorised environments stabilises training without the need of a replay buffer. Motivated by these findings, we propose PQN, our simplified deep online Q-Learning algorithm. Surprisingly, this simple algorithm is competitive with more complex methods like: Rainbow in Atari, R2D2 in Hanabi, QMix in Smax, PPO-RNN in Craftax, and can be up to 50x faster than traditional DQN without sacrificing sample efficiency. In an era where PPO has become the go-to RL algorithm, PQN reestablishes Q-learning as a viable alternative. We make our code available at: https://github.com/mttga/purejaxql.
Morphological Symmetries in Robotics
Feb 23, 2024We present a comprehensive framework for studying and leveraging morphological symmetries in robotic systems. These are intrinsic properties of the robot's morphology, frequently observed in animal biology and robotics, which stem from the replication of kinematic structures and the symmetrical distribution of mass. We illustrate how these symmetries extend to the robot's state space and both proprioceptive and exteroceptive sensor measurements, resulting in the equivariance of the robot's equations of motion and optimal control policies. Thus, we recognize morphological symmetries as a relevant and previously unexplored physics-informed geometric prior, with significant implications for both data-driven and analytical methods used in modeling, control, estimation and design in robotics. For data-driven methods, we demonstrate that morphological symmetries can enhance the sample efficiency and generalization of machine learning models through data augmentation, or by applying equivariant/invariant constraints on the model's architecture. In the context of analytical methods, we employ abstract harmonic analysis to decompose the robot's dynamics into a superposition of lower-dimensional, independent dynamics. We substantiate our claims with both synthetic and real-world experiments conducted on bipedal and quadrupedal robots. Lastly, we introduce the repository MorphoSymm to facilitate the practical use of the theory and applications outlined in this work.
On discrete symmetries of robotics systems: A group-theoretic and data-driven analysis
Feb 21, 2023In this work, we study discrete morphological symmetries of dynamical systems, a predominant feature in animal biology and robotic systems, expressed when the system's morphology has one or more planes of symmetry describing the duplication and balanced distribution of body parts. These morphological symmetries imply that the system's dynamics are symmetric (or approximately symmetric), which in turn imprints symmetries in optimal control policies and in all proprioceptive and exteroceptive measurements related to the evolution of the system's dynamics. For data-driven methods, symmetry represents an inductive bias that justifies data augmentation and the construction of symmetric function approximators. To this end, we use group theory to present a theoretical and practical framework allowing for (1) the identification of the system's morphological symmetry group $\G$, (2) data-augmentation of proprioceptive and exteroceptive measurements, and (3) the exploitation of data symmetries through the use of $\G$-equivariant/invariant neural networks, for which we present experimental results on synthetic and real-world applications, demonstrating how symmetry constraints lead to better sample efficiency and generalization while reducing the number of trainable parameters.
A reinforcement learning path planning approach for range-only underwater target localization with autonomous vehicles
Jan 17, 2023



Underwater target localization using range-only and single-beacon (ROSB) techniques with autonomous vehicles has been used recently to improve the limitations of more complex methods, such as long baseline and ultra-short baseline systems. Nonetheless, in ROSB target localization methods, the trajectory of the tracking vehicle near the localized target plays an important role in obtaining the best accuracy of the predicted target position. Here, we investigate a Reinforcement Learning (RL) approach to find the optimal path that an autonomous vehicle should follow in order to increase and optimize the overall accuracy of the predicted target localization, while reducing time and power consumption. To accomplish this objective, different experimental tests have been designed using state-of-the-art deep RL algorithms. Our study also compares the results obtained with the analytical Fisher information matrix approach used in previous studies. The results revealed that the policy learned by the RL agent outperforms trajectories based on these analytical solutions, e.g. the median predicted error at the beginning of the target's localisation is 17% less. These findings suggest that using deep RL for localizing acoustic targets could be successfully applied to in-water applications that include tracking of acoustically tagged marine animals by autonomous underwater vehicles. This is envisioned as a first necessary step to validate the use of RL to tackle such problems, which could be used later on in a more complex scenarios
* Accepted at CASE2022. Code at this Github repository https://github.com/imasmitja/RLforUTracking
TransfQMix: Transformers for Leveraging the Graph Structure of Multi-Agent Reinforcement Learning Problems
Jan 13, 2023Coordination is one of the most difficult aspects of multi-agent reinforcement learning (MARL). One reason is that agents normally choose their actions independently of one another. In order to see coordination strategies emerging from the combination of independent policies, the recent research has focused on the use of a centralized function (CF) that learns each agent's contribution to the team reward. However, the structure in which the environment is presented to the agents and to the CF is typically overlooked. We have observed that the features used to describe the coordination problem can be represented as vertex features of a latent graph structure. Here, we present TransfQMix, a new approach that uses transformers to leverage this latent structure and learn better coordination policies. Our transformer agents perform a graph reasoning over the state of the observable entities. Our transformer Q-mixer learns a monotonic mixing-function from a larger graph that includes the internal and external states of the agents. TransfQMix is designed to be entirely transferable, meaning that same parameters can be used to control and train larger or smaller teams of agents. This enables to deploy promising approaches to save training time and derive general policies in MARL, such as transfer learning, zero-shot transfer, and curriculum learning. We report TransfQMix's performances in the Spread and StarCraft II environments. In both settings, it outperforms state-of-the-art Q-Learning models, and it demonstrates effectiveness in solving problems that other methods can not solve.
An Adaptable Approach to Learn Realistic Legged Locomotion without Examples
Oct 28, 2021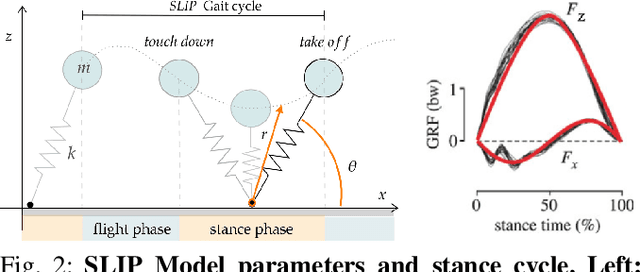
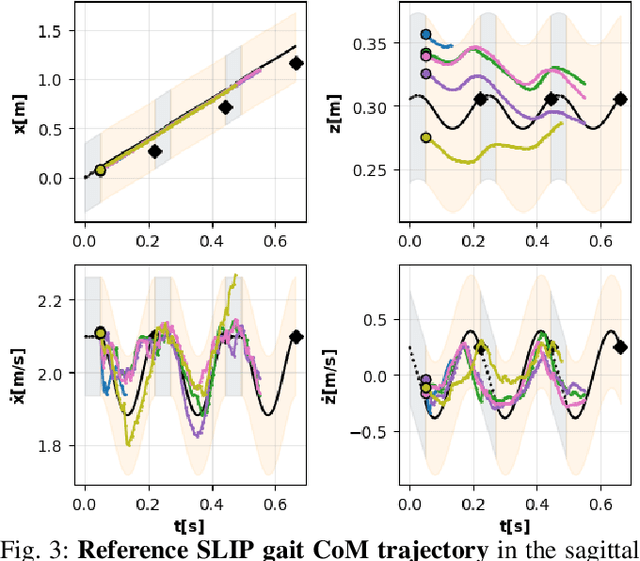
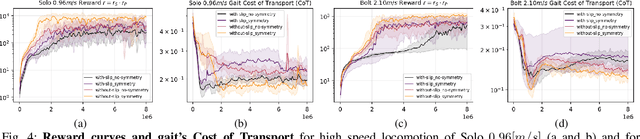
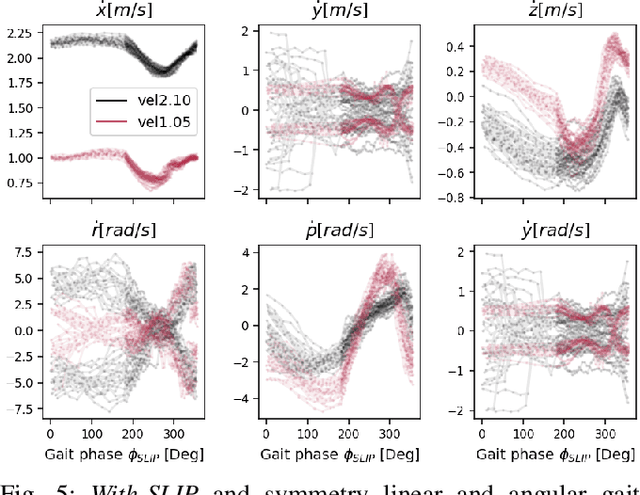
Learning controllers that reproduce legged locomotion in nature have been a long-time goal in robotics and computer graphics. While yielding promising results, recent approaches are not yet flexible enough to be applicable to legged systems of different morphologies. This is partly because they often rely on precise motion capture references or elaborate learning environments that ensure the naturality of the emergent locomotion gaits but prevent generalization. This work proposes a generic approach for ensuring realism in locomotion by guiding the learning process with the spring-loaded inverted pendulum model as a reference. Leveraging on the exploration capacities of Reinforcement Learning (RL), we learn a control policy that fills in the information gap between the template model and full-body dynamics required to maintain stable and periodic locomotion. The proposed approach can be applied to robots of different sizes and morphologies and adapted to any RL technique and control architecture. We present experimental results showing that even in a model-free setup and with a simple reactive control architecture, the learned policies can generate realistic and energy-efficient locomotion gaits for a bipedal and a quadrupedal robot. And most importantly, this is achieved without using motion capture, strong constraints in the dynamics or kinematics of the robot, nor prescribing limb coordination. We provide supplemental videos for qualitative analysis of the naturality of the learned gaits.
Coin_flipper at eHealth-KD Challenge 2019: Voting LSTMs for Key Phrases and Semantic Relation Identification Applied to Spanish eHealth Texts
Sep 26, 2019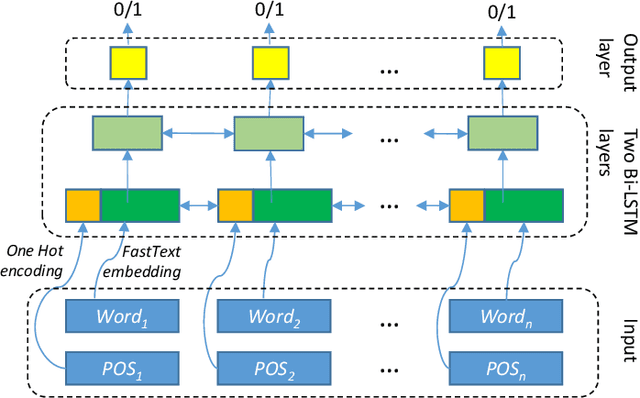

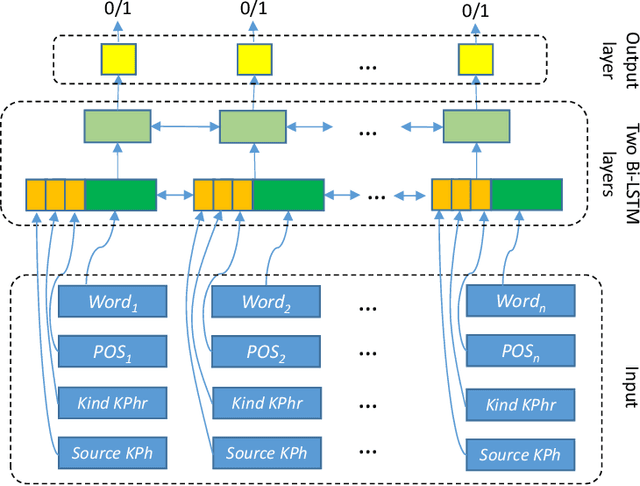
This paper describes our approach presented for the eHealth-KD 2019 challenge. Our participation was aimed at testing how far we could go using generic tools for Text-Processing but, at the same time, using common optimization techniques in the field of Data Mining. The architecture proposed for both tasks of the challenge is a standard stacked 2-layer bi-LSTM. The main particularities of our approach are: (a) The use of a surrogate function of F1 as loss function to close the gap between the minimization function and the evaluation metric, and (b) The generation of an ensemble of models for generating predictions by majority vote. Our system ranked second with an F1 score of 62.18% in the main task by a narrow margin with the winner that scored 63.94%.
* 9 pages, 2 figures, 1 table