 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoin_flipper at eHealth-KD Challenge 2019: Voting LSTMs for Key Phrases and Semantic Relation Identification Applied to Spanish eHealth Texts
Paper and Code
Sep 26, 2019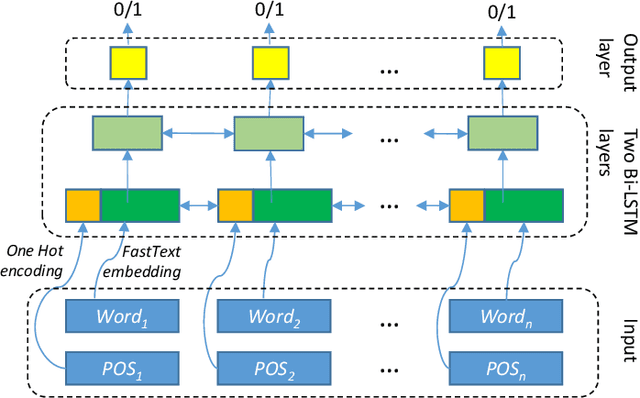

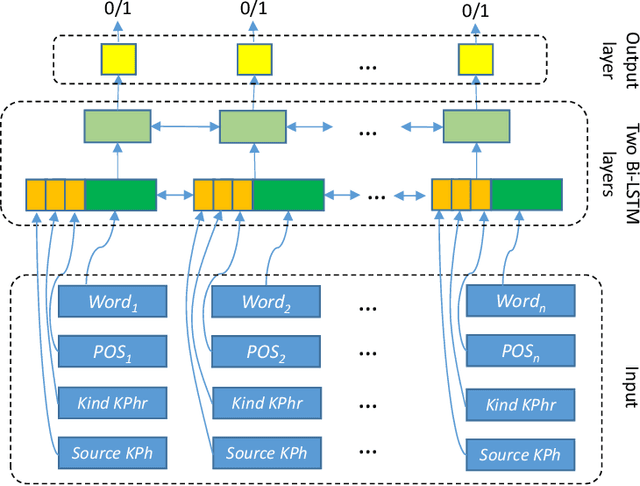
This paper describes our approach presented for the eHealth-KD 2019 challenge. Our participation was aimed at testing how far we could go using generic tools for Text-Processing but, at the same time, using common optimization techniques in the field of Data Mining. The architecture proposed for both tasks of the challenge is a standard stacked 2-layer bi-LSTM. The main particularities of our approach are: (a) The use of a surrogate function of F1 as loss function to close the gap between the minimization function and the evaluation metric, and (b) The generation of an ensemble of models for generating predictions by majority vote. Our system ranked second with an F1 score of 62.18% in the main task by a narrow margin with the winner that scored 63.94%.