 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAd-Hoc Human-AI Coordination Challenge
Jun 26, 2025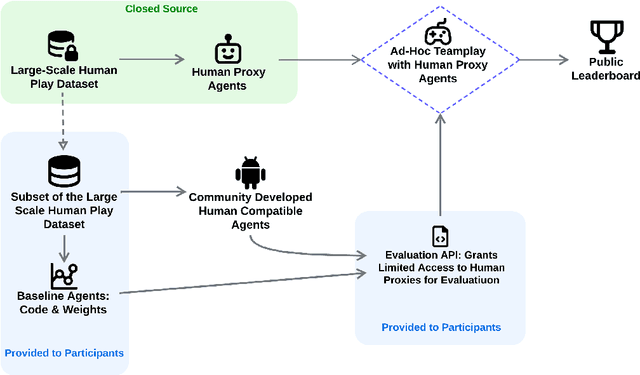

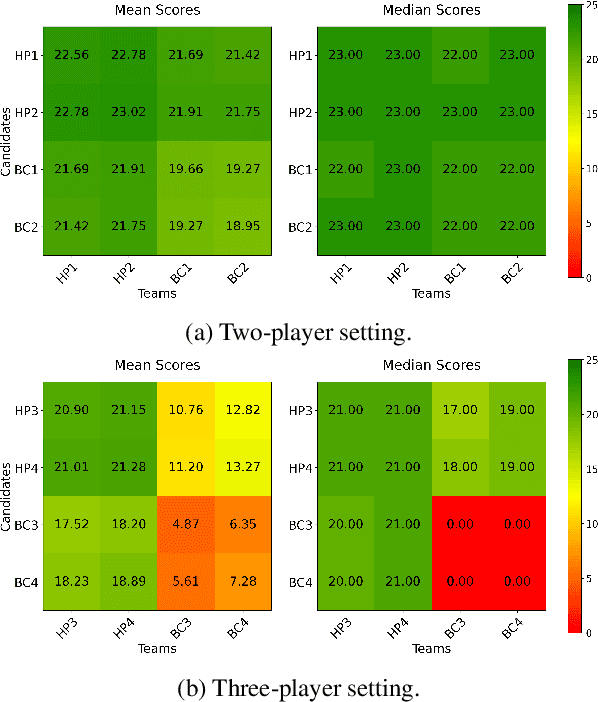

Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
Fine-Tuning Next-Scale Visual Autoregressive Models with Group Relative Policy Optimization
May 29, 2025Fine-tuning pre-trained generative models with Reinforcement Learning (RL) has emerged as an effective approach for aligning outputs more closely with nuanced human preferences. In this paper, we investigate the application of Group Relative Policy Optimization (GRPO) to fine-tune next-scale visual autoregressive (VAR) models. Our empirical results demonstrate that this approach enables alignment to intricate reward signals derived from aesthetic predictors and CLIP embeddings, significantly enhancing image quality and enabling precise control over the generation style. Interestingly, by leveraging CLIP, our method can help VAR models generalize beyond their initial ImageNet distribution: through RL-driven exploration, these models can generate images aligned with prompts referencing image styles that were absent during pre-training. In summary, we show that RL-based fine-tuning is both efficient and effective for VAR models, benefiting particularly from their fast inference speeds, which are advantageous for online sampling, an aspect that poses significant challenges for diffusion-based alternatives.
Simplifying Deep Temporal Difference Learning
Jul 05, 2024



Q-learning played a foundational role in the field reinforcement learning (RL). However, TD algorithms with off-policy data, such as Q-learning, or nonlinear function approximation like deep neural networks require several additional tricks to stabilise training, primarily a replay buffer and target networks. Unfortunately, the delayed updating of frozen network parameters in the target network harms the sample efficiency and, similarly, the replay buffer introduces memory and implementation overheads. In this paper, we investigate whether it is possible to accelerate and simplify TD training while maintaining its stability. Our key theoretical result demonstrates for the first time that regularisation techniques such as LayerNorm can yield provably convergent TD algorithms without the need for a target network, even with off-policy data. Empirically, we find that online, parallelised sampling enabled by vectorised environments stabilises training without the need of a replay buffer. Motivated by these findings, we propose PQN, our simplified deep online Q-Learning algorithm. Surprisingly, this simple algorithm is competitive with more complex methods like: Rainbow in Atari, R2D2 in Hanabi, QMix in Smax, PPO-RNN in Craftax, and can be up to 50x faster than traditional DQN without sacrificing sample efficiency. In an era where PPO has become the go-to RL algorithm, PQN reestablishes Q-learning as a viable alternative. We make our code available at: https://github.com/mttga/purejaxql.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023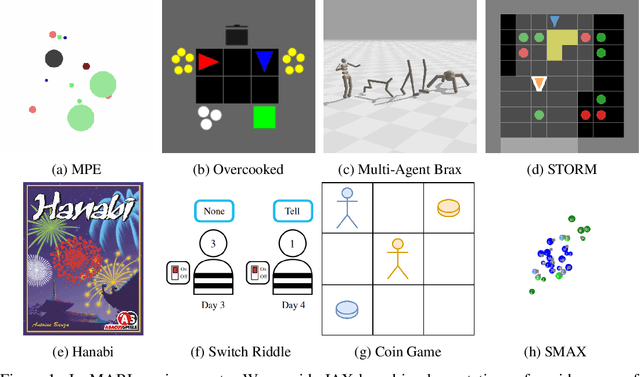

Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
TransfQMix: Transformers for Leveraging the Graph Structure of Multi-Agent Reinforcement Learning Problems
Jan 13, 2023Coordination is one of the most difficult aspects of multi-agent reinforcement learning (MARL). One reason is that agents normally choose their actions independently of one another. In order to see coordination strategies emerging from the combination of independent policies, the recent research has focused on the use of a centralized function (CF) that learns each agent's contribution to the team reward. However, the structure in which the environment is presented to the agents and to the CF is typically overlooked. We have observed that the features used to describe the coordination problem can be represented as vertex features of a latent graph structure. Here, we present TransfQMix, a new approach that uses transformers to leverage this latent structure and learn better coordination policies. Our transformer agents perform a graph reasoning over the state of the observable entities. Our transformer Q-mixer learns a monotonic mixing-function from a larger graph that includes the internal and external states of the agents. TransfQMix is designed to be entirely transferable, meaning that same parameters can be used to control and train larger or smaller teams of agents. This enables to deploy promising approaches to save training time and derive general policies in MARL, such as transfer learning, zero-shot transfer, and curriculum learning. We report TransfQMix's performances in the Spread and StarCraft II environments. In both settings, it outperforms state-of-the-art Q-Learning models, and it demonstrates effectiveness in solving problems that other methods can not solve.