 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
Ad-Hoc Human-AI Coordination Challenge
Jun 26, 2025

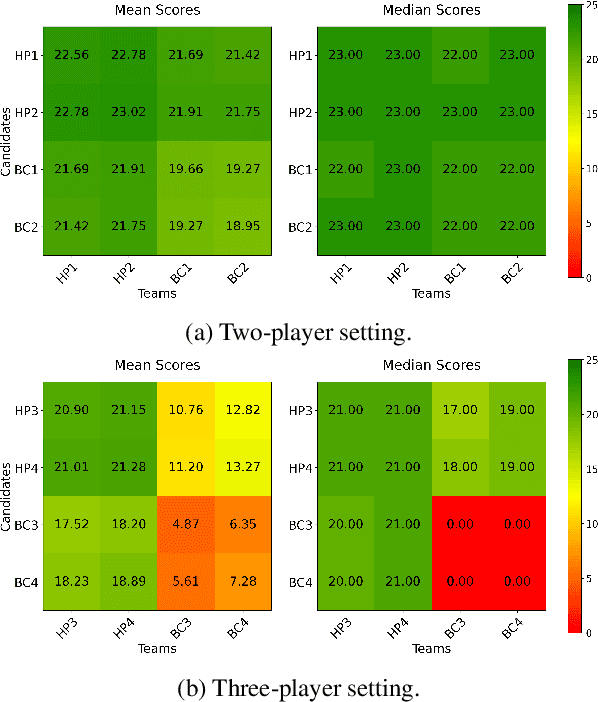

Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
Programming by Backprop: LLMs Acquire Reusable Algorithmic Abstractions During Code Training
Jun 23, 2025Training large language models (LLMs) on source code significantly enhances their general-purpose reasoning abilities, but the mechanisms underlying this generalisation are poorly understood. In this paper, we propose Programming by Backprop (PBB) as a potential driver of this effect - teaching a model to evaluate a program for inputs by training on its source code alone, without ever seeing I/O examples. To explore this idea, we finetune LLMs on two sets of programs representing simple maths problems and algorithms: one with source code and I/O examples (w/ IO), the other with source code only (w/o IO). We find evidence that LLMs have some ability to evaluate w/o IO programs for inputs in a range of experimental settings, and make several observations. Firstly, PBB works significantly better when programs are provided as code rather than semantically equivalent language descriptions. Secondly, LLMs can produce outputs for w/o IO programs directly, by implicitly evaluating the program within the forward pass, and more reliably when stepping through the program in-context via chain-of-thought. We further show that PBB leads to more robust evaluation of programs across inputs than training on I/O pairs drawn from a distribution that mirrors naturally occurring data. Our findings suggest a mechanism for enhanced reasoning through code training: it allows LLMs to internalise reusable algorithmic abstractions. Significant scope remains for future work to enable LLMs to more effectively learn from symbolic procedures, and progress in this direction opens other avenues like model alignment by training on formal constitutional principles.
TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation
Oct 04, 2024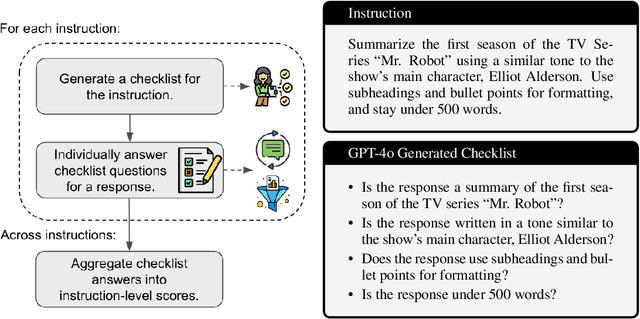



Given the widespread adoption and usage of Large Language Models (LLMs), it is crucial to have flexible and interpretable evaluations of their instruction-following ability. Preference judgments between model outputs have become the de facto evaluation standard, despite distilling complex, multi-faceted preferences into a single ranking. Furthermore, as human annotation is slow and costly, LLMs are increasingly used to make these judgments, at the expense of reliability and interpretability. In this work, we propose TICK (Targeted Instruct-evaluation with ChecKlists), a fully automated, interpretable evaluation protocol that structures evaluations with LLM-generated, instruction-specific checklists. We first show that, given an instruction, LLMs can reliably produce high-quality, tailored evaluation checklists that decompose the instruction into a series of YES/NO questions. Each question asks whether a candidate response meets a specific requirement of the instruction. We demonstrate that using TICK leads to a significant increase (46.4% $\to$ 52.2%) in the frequency of exact agreements between LLM judgements and human preferences, as compared to having an LLM directly score an output. We then show that STICK (Self-TICK) can be used to improve generation quality across multiple benchmarks via self-refinement and Best-of-N selection. STICK self-refinement on LiveBench reasoning tasks leads to an absolute gain of $+$7.8%, whilst Best-of-N selection with STICK attains $+$6.3% absolute improvement on the real-world instruction dataset, WildBench. In light of this, structured, multi-faceted self-improvement is shown to be a promising way to further advance LLM capabilities. Finally, by providing LLM-generated checklists to human evaluators tasked with directly scoring LLM responses to WildBench instructions, we notably increase inter-annotator agreement (0.194 $\to$ 0.256).
Artificial Generational Intelligence: Cultural Accumulation in Reinforcement Learning
Jun 01, 2024



Cultural accumulation drives the open-ended and diverse progress in capabilities spanning human history. It builds an expanding body of knowledge and skills by combining individual exploration with inter-generational information transmission. Despite its widespread success among humans, the capacity for artificial learning agents to accumulate culture remains under-explored. In particular, approaches to reinforcement learning typically strive for improvements over only a single lifetime. Generational algorithms that do exist fail to capture the open-ended, emergent nature of cultural accumulation, which allows individuals to trade-off innovation and imitation. Building on the previously demonstrated ability for reinforcement learning agents to perform social learning, we find that training setups which balance this with independent learning give rise to cultural accumulation. These accumulating agents outperform those trained for a single lifetime with the same cumulative experience. We explore this accumulation by constructing two models under two distinct notions of a generation: episodic generations, in which accumulation occurs via in-context learning and train-time generations, in which accumulation occurs via in-weights learning. In-context and in-weights cultural accumulation can be interpreted as analogous to knowledge and skill accumulation, respectively. To the best of our knowledge, this work is the first to present general models that achieve emergent cultural accumulation in reinforcement learning, opening up new avenues towards more open-ended learning systems, as well as presenting new opportunities for modelling human culture.
Cryptanalysis of the SIMON Cypher Using Neo4j
May 08, 2024The exponential growth in the number of Internet of Things (IoT) devices has seen the introduction of several Lightweight Encryption Algorithms (LEA). While LEAs are designed to enhance the integrity, privacy and security of data collected and transmitted by IoT devices, it is hazardous to assume that all LEAs are secure and exhibit similar levels of protection. To improve encryption strength, cryptanalysts and algorithm designers routinely probe LEAs using various cryptanalysis techniques to identify vulnerabilities and limitations of LEAs. Despite recent improvements in the efficiency of cryptanalysis utilising heuristic methods and a Partial Difference Distribution Table (PDDT), the process remains inefficient, with the random nature of the heuristic inhibiting reproducible results. However, the use of a PDDT presents opportunities to identify relationships between differentials utilising knowledge graphs, leading to the identification of efficient paths throughout the PDDT. This paper introduces the novel use of knowledge graphs to identify intricate relationships between differentials in the SIMON LEA, allowing for the identification of optimal paths throughout the differentials, and increasing the effectiveness of the differential security analyses of SIMON.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023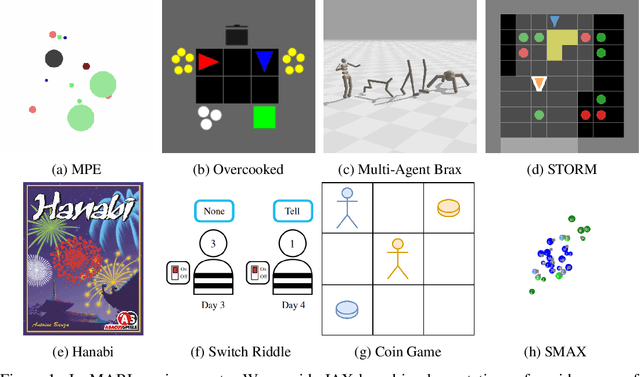

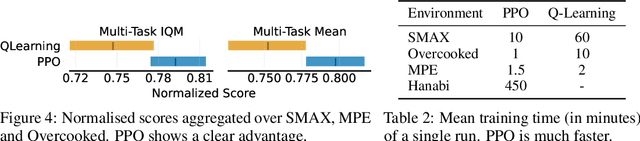
Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.