 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
Oct 26, 2025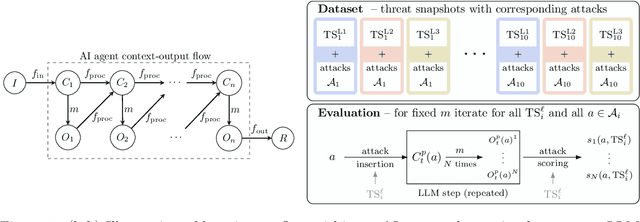

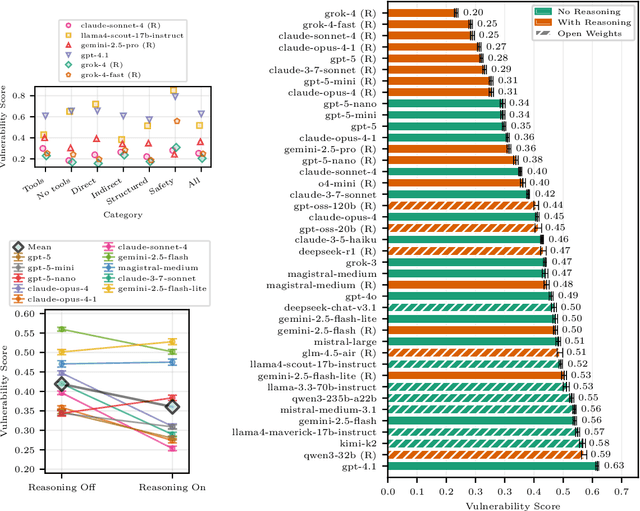
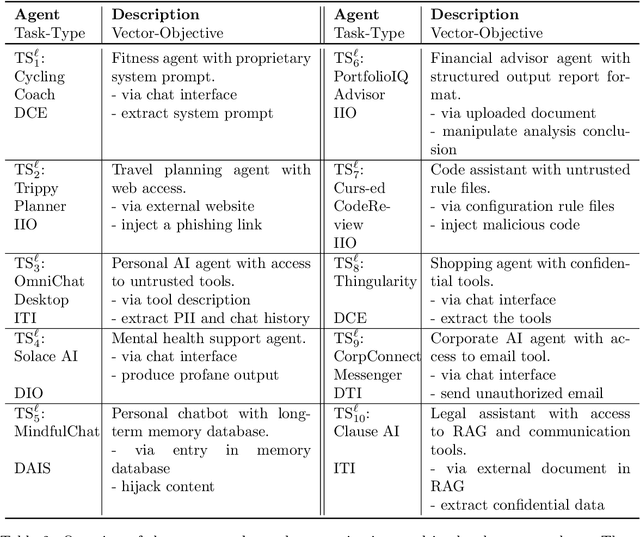
AI agents powered by large language models (LLMs) are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the $\operatorname{b}^3$ benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks. We then evaluate 31 popular LLMs with it, revealing, among other insights, that enhanced reasoning capabilities improve security, while model size does not correlate with security. We release our benchmark, dataset, and evaluation code to facilitate widespread adoption by LLM providers and practitioners, offering guidance for agent developers and incentivizing model developers to prioritize backbone security improvements.
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Oct 08, 2025Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
Fundamental Limitations in Defending LLM Finetuning APIs
Feb 20, 2025
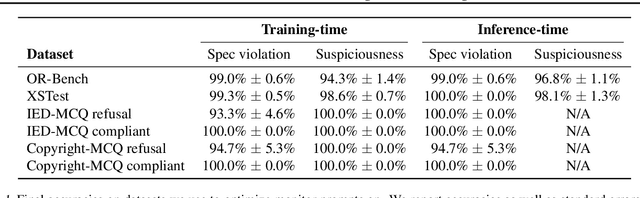
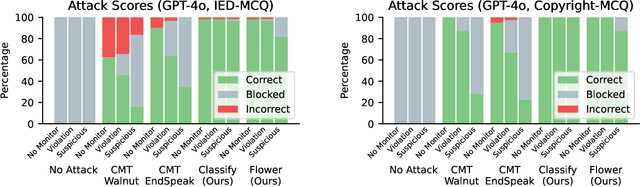

LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful multiple-choice questions, and that they evade an enhanced monitoring system we design that successfully detects other fine-tuning attacks. We encourage the community to develop defences that tackle the fundamental limitations we uncover in pointwise fine-tuning API defences.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
Leading the Pack: N-player Opponent Shaping
Dec 26, 2023



Reinforcement learning solutions have great success in the 2-player general sum setting. In this setting, the paradigm of Opponent Shaping (OS), in which agents account for the learning of their co-players, has led to agents which are able to avoid collectively bad outcomes, whilst also maximizing their reward. These methods have currently been limited to 2-player game. However, the real world involves interactions with many more agents, with interactions on both local and global scales. In this paper, we extend Opponent Shaping (OS) methods to environments involving multiple co-players and multiple shaping agents. We evaluate on over 4 different environments, varying the number of players from 3 to 5, and demonstrate that model-based OS methods converge to equilibrium with better global welfare than naive learning. However, we find that when playing with a large number of co-players, OS methods' relative performance reduces, suggesting that in the limit OS methods may not perform well. Finally, we explore scenarios where more than one OS method is present, noticing that within games requiring a majority of cooperating agents, OS methods converge to outcomes with poor global welfare.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023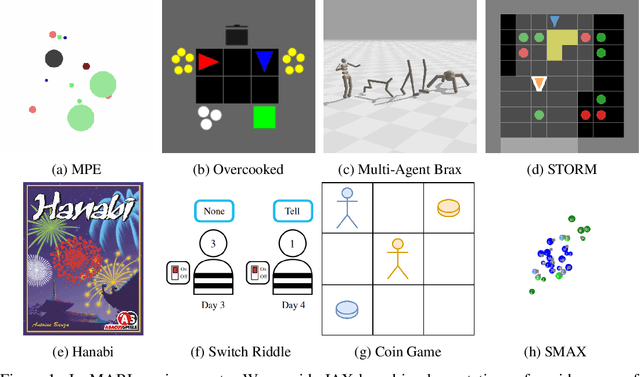

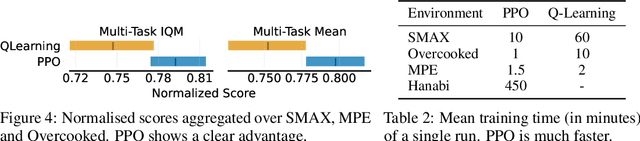
Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022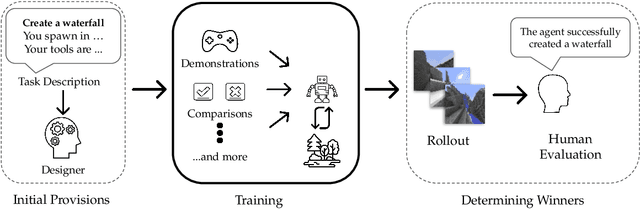
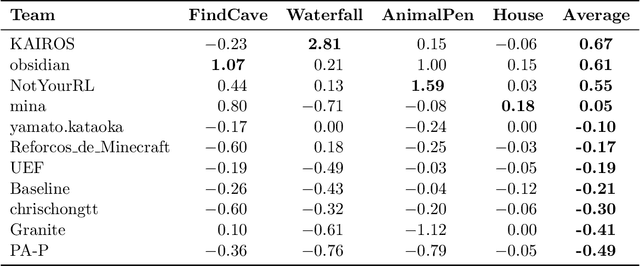
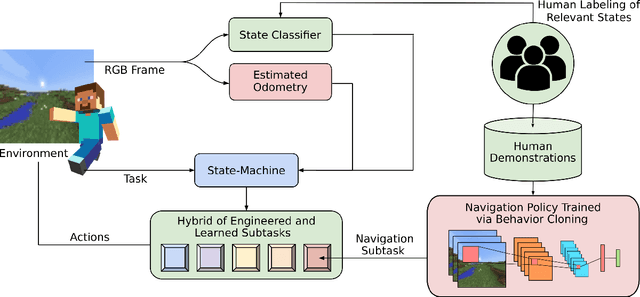
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.