 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Coordinate with Experts
Feb 13, 2025When deployed in dynamic environments, AI agents will inevitably encounter challenges that exceed their individual capabilities. Leveraging assistance from expert agents-whether human or AI-can significantly enhance safety and performance in such situations. However, querying experts is often costly, necessitating the development of agents that can efficiently request and utilize expert guidance. In this paper, we introduce a fundamental coordination problem called Learning to Yield and Request Control (YRC), where the objective is to learn a strategy that determines when to act autonomously and when to seek expert assistance. We consider a challenging practical setting in which an agent does not interact with experts during training but must adapt to novel environmental changes and expert interventions at test time. To facilitate empirical research, we introduce YRC-Bench, an open-source benchmark featuring diverse domains. YRC-Bench provides a standardized Gym-like API, simulated experts, evaluation pipeline, and implementation of competitive baselines. Towards tackling the YRC problem, we propose a novel validation approach and investigate the performance of various learning methods across diverse environments, yielding insights that can guide future research.
Getting By Goal Misgeneralization With a Little Help From a Mentor
Oct 28, 2024While reinforcement learning (RL) agents often perform well during training, they can struggle with distribution shift in real-world deployments. One particularly severe risk of distribution shift is goal misgeneralization, where the agent learns a proxy goal that coincides with the true goal during training but not during deployment. In this paper, we explore whether allowing an agent to ask for help from a supervisor in unfamiliar situations can mitigate this issue. We focus on agents trained with PPO in the CoinRun environment, a setting known to exhibit goal misgeneralization. We evaluate multiple methods for determining when the agent should request help and find that asking for help consistently improves performance. However, we also find that methods based on the agent's internal state fail to proactively request help, instead waiting until mistakes have already occurred. Further investigation suggests that the agent's internal state does not represent the coin at all, highlighting the importance of learning nuanced representations, the risks of ignoring everything not immediately relevant to reward, and the necessity of developing ask-for-help strategies tailored to the agent's training algorithm.
Softmax Probabilities (Mostly) Predict Large Language Model Correctness on Multiple-Choice Q&A
Feb 20, 2024Although large language models (LLMs) perform impressively on many tasks, overconfidence remains a problem. We hypothesized that on multiple-choice Q&A tasks, wrong answers would be associated with smaller maximum softmax probabilities (MSPs) compared to correct answers. We comprehensively evaluate this hypothesis on ten open-source LLMs and five datasets, and find strong evidence for our hypothesis among models which perform well on the original Q&A task. For the six LLMs with the best Q&A performance, the AUROC derived from the MSP was better than random chance with p < 10^{-4} in 59/60 instances. Among those six LLMs, the average AUROC ranged from 60% to 69%. Leveraging these findings, we propose a multiple-choice Q&A task with an option to abstain and show that performance can be improved by selectively abstaining based on the MSP of the initial model response. We also run the same experiments with pre-softmax logits instead of softmax probabilities and find similar (but not identical) results.
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
Autonomous Assessment of Demonstration Sufficiency via Bayesian Inverse Reinforcement Learning
Nov 29, 2022In this paper we examine the problem of determining demonstration sufficiency for AI agents that learn from demonstrations: how can an AI agent self-assess whether it has received enough demonstrations from an expert to ensure a desired level of performance? To address this problem we propose a novel self-assessment approach based on Bayesian inverse reinforcement learning and value-at-risk to enable agents that learn from demonstrations to compute high-confidence bounds on their performance and use these bounds to determine when they have a sufficient number of demonstrations. We propose and evaluate two definitions of sufficiency: (1) normalized expected value difference, which measures regret with respect to the expert's unobserved reward function, and (2) improvement over a baseline policy. We demonstrate how to formulate high-confidence bounds on both of these metrics. We evaluate our approach in simulation and demonstrate the feasibility of developing an AI system that can accurately evaluate whether it has received sufficient training data to guarantee, with high confidence, that it can match an expert's performance or surpass the performance of a baseline policy within some desired safety threshold.
Efficient Game-Theoretic Planning with Prediction Heuristic for Socially-Compliant Autonomous Driving
Jul 08, 2022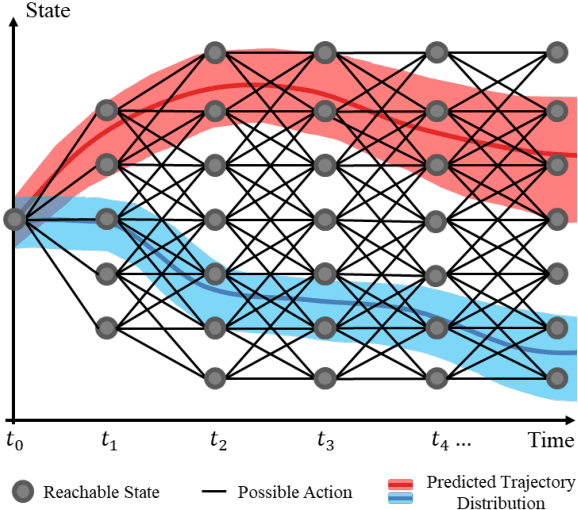
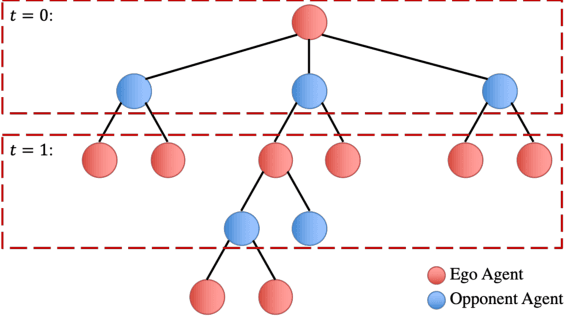

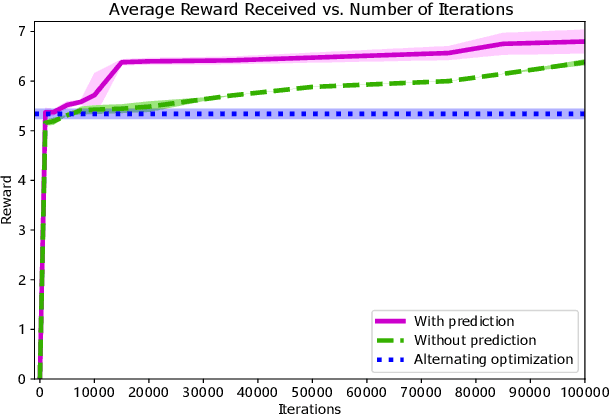
Planning under social interactions with other agents is an essential problem for autonomous driving. As the actions of the autonomous vehicle in the interactions affect and are also affected by other agents, autonomous vehicles need to efficiently infer the reaction of the other agents. Most existing approaches formulate the problem as a generalized Nash equilibrium problem solved by optimization-based methods. However, they demand too much computational resource and easily fall into the local minimum due to the non-convexity. Monte Carlo Tree Search (MCTS) successfully tackles such issues in game-theoretic problems. However, as the interaction game tree grows exponentially, the general MCTS still requires a huge amount of iterations to reach the optima. In this paper, we introduce an efficient game-theoretic trajectory planning algorithm based on general MCTS by incorporating a prediction algorithm as a heuristic. On top of it, a social-compliant reward and a Bayesian inference algorithm are designed to generate diverse driving behaviors and identify the other driver's driving preference. Results demonstrate the effectiveness of the proposed framework with datasets containing naturalistic driving behavior in highly interactive scenarios.