 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded World Model for Semantically Generalizable Planning
Apr 13, 2026In Model Predictive Control (MPC), world models predict the future outcomes of various action proposals, which are then scored to guide the selection of the optimal action. For visuomotor MPC, the score function is a distance metric between a predicted image and a goal image, measured in the latent space of a pretrained vision encoder like DINO and JEPA. However, it is challenging to obtain the goal image in advance of the task execution, particularly in new environments. Additionally, conveying the goal through an image offers limited interactivity compared with natural language. In this work, we propose to learn a Grounded World Model (GWM) in a vision-language-aligned latent space. As a result, each proposed action is scored based on how close its future outcome is to the task instruction, reflected by the similarity of embeddings. This approach transforms the visuomotor MPC to a VLA that surpasses VLM-based VLAs in semantic generalization. On the proposed WISER benchmark, GWM-MPC achieves a 87% success rate on the test set comprising 288 tasks that feature unseen visual signals and referring expressions, yet remain solvable with motions demonstrated during training. In contrast, traditional VLAs achieve an average success rate of 22%, even though they overfit the training set with a 90% success rate.
LMGenDrive: Bridging Multimodal Understanding and Generative World Modeling for End-to-End Driving
Apr 09, 2026Recent years have seen remarkable progress in autonomous driving, yet generalization to long-tail and open-world scenarios remains a major bottleneck for large-scale deployment. To address this challenge, some works use LLMs and VLMs for vision-language understanding and reasoning, enabling vehicles to interpret rare and safety-critical situations when generating actions. Others study generative world models to capture the spatio-temporal evolution of driving scenes, allowing agents to imagine possible futures before acting. Inspired by human intelligence, which unifies understanding and imagination, we explore a unified model for autonomous driving. We present LMGenDrive, the first framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, LMGenDrive generates both future driving videos and control signals. This design provides complementary benefits: video prediction improves spatio-temporal scene modeling, while the LLM contributes strong semantic priors and instruction grounding from large-scale pretraining. We further propose a progressive three-stage training strategy, from vision pretraining to multi-step long-horizon driving, to improve stability and performance. LMGenDrive supports both low-latency online planning and autoregressive offline video generation. Experiments show that it significantly outperforms prior methods on challenging closed-loop benchmarks, with clear gains in instruction following, spatio-temporal understanding, and robustness to rare scenarios. These results suggest that unifying multimodal understanding and generation is a promising direction for more generalizable and robust embodied decision-making systems.
DriveDreamer-Policy: A Geometry-Grounded World-Action Model for Unified Generation and Planning
Apr 02, 2026Recently, world-action models (WAM) have emerged to bridge vision-language-action (VLA) models and world models, unifying their reasoning and instruction-following capabilities and spatio-temporal world modeling. However, existing WAM approaches often focus on modeling 2D appearance or latent representations, with limited geometric grounding-an essential element for embodied systems operating in the physical world. We present DriveDreamer-Policy, a unified driving world-action model that integrates depth generation, future video generation, and motion planning within a single modular architecture. The model employs a large language model to process language instructions, multi-view images, and actions, followed by three lightweight generators that produce depth, future video, and actions. By learning a geometry-aware world representation and using it to guide both future prediction and planning within a unified framework, the proposed model produces more coherent imagined futures and more informed driving actions, while maintaining modularity and controllable latency. Experiments on the Navsim v1 and v2 benchmarks demonstrate that DriveDreamer-Policy achieves strong performance on both closed-loop planning and world generation tasks. In particular, our model reaches 89.2 PDMS on Navsim v1 and 88.7 EPDMS on Navsim v2, outperforming existing world-model-based approaches while producing higher-quality future video and depth predictions. Ablation studies further show that explicit depth learning provides complementary benefits to video imagination and improves planning robustness.
THFM: A Unified Video Foundation Model for 4D Human Perception and Beyond
Mar 26, 2026We present THFM, a unified video foundation model for human-centric perception that jointly addresses dense tasks (depth, normals, segmentation, dense pose) and sparse tasks (2d/3d keypoint estimation) within a single architecture. THFM is derived from a pretrained text-to-video diffusion model, repurposed as a single-forward-pass perception model and augmented with learnable tokens for sparse predictions. Modulated by the text prompt, our single unified model is capable of performing various perception tasks. Crucially, our model is on-par or surpassing state-of-the-art specialized models on a variety of benchmarks despite being trained exclusively on synthetic data (i.e.~without training on real-world or benchmark specific data). We further highlight intriguing emergent properties of our model, which we attribute to the underlying diffusion-based video representation. For example, our model trained on videos with a single human in the scene generalizes to multiple humans and other object classes such as anthropomorphic characters and animals -- a capability that hasn't been demonstrated in the past.
SCATR: Mitigating New Instance Suppression in LiDAR-based Tracking-by-Attention via Second Chance Assignment and Track Query Dropout
Mar 02, 2026LiDAR-based tracking-by-attention (TBA) frameworks inherently suffer from high false negative errors, leading to a significant performance gap compared to traditional LiDAR-based tracking-by-detection (TBD) methods. This paper introduces SCATR, a novel LiDAR-based TBA model designed to address this fundamental challenge systematically. SCATR leverages recent progress in vision-based tracking and incorporates targeted training strategies specifically adapted for LiDAR. Our work's core innovations are two architecture-agnostic training strategies for TBA methods: Second Chance Assignment and Track Query Dropout. Second Chance Assignment is a novel ground truth assignment that concatenates unassigned track queries to the proposal queries before bipartite matching, giving these track queries a second chance to be assigned to a ground truth object and effectively mitigating the conflict between detection and tracking tasks inherent in tracking-by-attention. Track Query Dropout is a training method that diversifies supervised object query configurations to efficiently train the decoder to handle different track query sets, enhancing robustness to missing or newborn tracks. Experiments on the nuScenes tracking benchmark demonstrate that SCATR achieves state-of-the-art performance among LiDAR-based TBA methods, outperforming previous works by 7.6\% AMOTA and successfully bridging the long-standing performance gap between LiDAR-based TBA and TBD methods. Ablation studies further validate the effectiveness and generalization of Second Chance Assignment and Track Query Dropout. Code can be found at the following link: \href{https://github.com/TRAILab/SCATR}{https://github.com/TRAILab/SCATR}
DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
Jan 04, 2026Video generation models, as one form of world models, have emerged as one of the most exciting frontiers in AI, promising agents the ability to imagine the future by modeling the temporal evolution of complex scenes. In autonomous driving, this vision gives rise to driving world models: generative simulators that imagine ego and agent futures, enabling scalable simulation, safe testing of corner cases, and rich synthetic data generation. Yet, despite fast-growing research activity, the field lacks a rigorous benchmark to measure progress and guide priorities. Existing evaluations remain limited: generic video metrics overlook safety-critical imaging factors; trajectory plausibility is rarely quantified; temporal and agent-level consistency is neglected; and controllability with respect to ego conditioning is ignored. Moreover, current datasets fail to cover the diversity of conditions required for real-world deployment. To address these gaps, we present DrivingGen, the first comprehensive benchmark for generative driving world models. DrivingGen combines a diverse evaluation dataset curated from both driving datasets and internet-scale video sources, spanning varied weather, time of day, geographic regions, and complex maneuvers, with a suite of new metrics that jointly assess visual realism, trajectory plausibility, temporal coherence, and controllability. Benchmarking 14 state-of-the-art models reveals clear trade-offs: general models look better but break physics, while driving-specific ones capture motion realistically but lag in visual quality. DrivingGen offers a unified evaluation framework to foster reliable, controllable, and deployable driving world models, enabling scalable simulation, planning, and data-driven decision-making.
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
ForeSight: Multi-View Streaming Joint Object Detection and Trajectory Forecasting
Aug 09, 2025
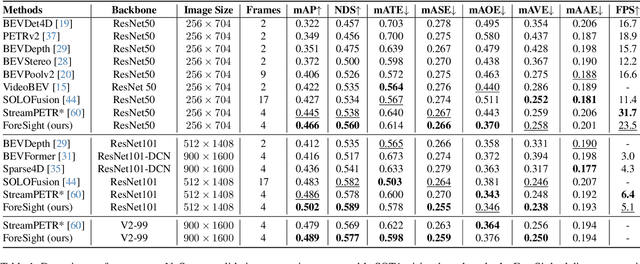

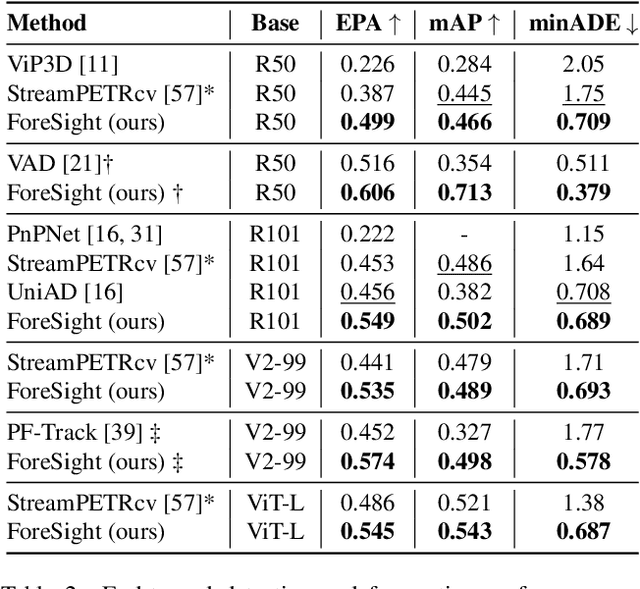
We introduce ForeSight, a novel joint detection and forecasting framework for vision-based 3D perception in autonomous vehicles. Traditional approaches treat detection and forecasting as separate sequential tasks, limiting their ability to leverage temporal cues. ForeSight addresses this limitation with a multi-task streaming and bidirectional learning approach, allowing detection and forecasting to share query memory and propagate information seamlessly. The forecast-aware detection transformer enhances spatial reasoning by integrating trajectory predictions from a multiple hypothesis forecast memory queue, while the streaming forecast transformer improves temporal consistency using past forecasts and refined detections. Unlike tracking-based methods, ForeSight eliminates the need for explicit object association, reducing error propagation with a tracking-free model that efficiently scales across multi-frame sequences. Experiments on the nuScenes dataset show that ForeSight achieves state-of-the-art performance, achieving an EPA of 54.9%, surpassing previous methods by 9.3%, while also attaining the best mAP and minADE among multi-view detection and forecasting models.
OpenNav: Open-World Navigation with Multimodal Large Language Models
Jul 24, 2025



Pre-trained large language models (LLMs) have demonstrated strong common-sense reasoning abilities, making them promising for robotic navigation and planning tasks. However, despite recent progress, bridging the gap between language descriptions and actual robot actions in the open-world, beyond merely invoking limited predefined motion primitives, remains an open challenge. In this work, we aim to enable robots to interpret and decompose complex language instructions, ultimately synthesizing a sequence of trajectory points to complete diverse navigation tasks given open-set instructions and open-set objects. We observe that multi-modal large language models (MLLMs) exhibit strong cross-modal understanding when processing free-form language instructions, demonstrating robust scene comprehension. More importantly, leveraging their code-generation capability, MLLMs can interact with vision-language perception models to generate compositional 2D bird-eye-view value maps, effectively integrating semantic knowledge from MLLMs with spatial information from maps to reinforce the robot's spatial understanding. To further validate our approach, we effectively leverage large-scale autonomous vehicle datasets (AVDs) to validate our proposed zero-shot vision-language navigation framework in outdoor navigation tasks, demonstrating its capability to execute a diverse range of free-form natural language navigation instructions while maintaining robustness against object detection errors and linguistic ambiguities. Furthermore, we validate our system on a Husky robot in both indoor and outdoor scenes, demonstrating its real-world robustness and applicability. Supplementary videos are available at https://trailab.github.io/OpenNav-website/