 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-rank Aware Sequential Reward Learning for Inverse Reinforcement Learning with Sub-optimal Demonstrations
Oct 13, 2023

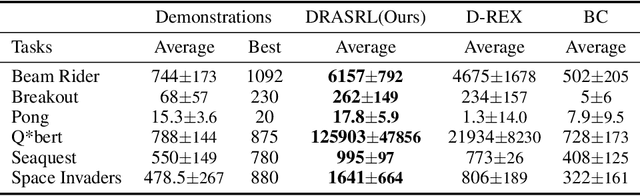

Inverse reinforcement learning (IRL) aims to explicitly infer an underlying reward function based on collected expert demonstrations. Considering that obtaining expert demonstrations can be costly, the focus of current IRL techniques is on learning a better-than-demonstrator policy using a reward function derived from sub-optimal demonstrations. However, existing IRL algorithms primarily tackle the challenge of trajectory ranking ambiguity when learning the reward function. They overlook the crucial role of considering the degree of difference between trajectories in terms of their returns, which is essential for further removing reward ambiguity. Additionally, it is important to note that the reward of a single transition is heavily influenced by the context information within the trajectory. To address these issues, we introduce the Distance-rank Aware Sequential Reward Learning (DRASRL) framework. Unlike existing approaches, DRASRL takes into account both the ranking of trajectories and the degrees of dissimilarity between them to collaboratively eliminate reward ambiguity when learning a sequence of contextually informed reward signals. Specifically, we leverage the distance between policies, from which the trajectories are generated, as a measure to quantify the degree of differences between traces. This distance-aware information is then used to infer embeddings in the representation space for reward learning, employing the contrastive learning technique. Meanwhile, we integrate the pairwise ranking loss function to incorporate ranking information into the latent features. Moreover, we resort to the Transformer architecture to capture the contextual dependencies within the trajectories in the latent space, leading to more accurate reward estimation. Through extensive experimentation, our DRASRL framework demonstrates significant performance improvements over previous SOTA methods.
ReasonNet: End-to-End Driving with Temporal and Global Reasoning
May 17, 2023


The large-scale deployment of autonomous vehicles is yet to come, and one of the major remaining challenges lies in urban dense traffic scenarios. In such cases, it remains challenging to predict the future evolution of the scene and future behaviors of objects, and to deal with rare adverse events such as the sudden appearance of occluded objects. In this paper, we present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. By reasoning on the temporal behavior of objects, our method can effectively process the interactions and relationships among features in different frames. Reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events, especially the anticipation of potential danger from occluded objects. For comprehensive evaluation on occlusion events, we also release publicly a driving simulation benchmark DriveOcclusionSim consisting of diverse occlusion events. We conduct extensive experiments on multiple CARLA benchmarks, where our model outperforms all prior methods, ranking first on the sensor track of the public CARLA Leaderboard.
Efficient Reinforcement Learning for Autonomous Driving with Parameterized Skills and Priors
May 08, 2023When autonomous vehicles are deployed on public roads, they will encounter countless and diverse driving situations. Many manually designed driving policies are difficult to scale to the real world. Fortunately, reinforcement learning has shown great success in many tasks by automatic trial and error. However, when it comes to autonomous driving in interactive dense traffic, RL agents either fail to learn reasonable performance or necessitate a large amount of data. Our insight is that when humans learn to drive, they will 1) make decisions over the high-level skill space instead of the low-level control space and 2) leverage expert prior knowledge rather than learning from scratch. Inspired by this, we propose ASAP-RL, an efficient reinforcement learning algorithm for autonomous driving that simultaneously leverages motion skills and expert priors. We first parameterized motion skills, which are diverse enough to cover various complex driving scenarios and situations. A skill parameter inverse recovery method is proposed to convert expert demonstrations from control space to skill space. A simple but effective double initialization technique is proposed to leverage expert priors while bypassing the issue of expert suboptimality and early performance degradation. We validate our proposed method on interactive dense-traffic driving tasks given simple and sparse rewards. Experimental results show that our method can lead to higher learning efficiency and better driving performance relative to previous methods that exploit skills and priors differently. Code is open-sourced to facilitate further research.
Accelerating Reinforcement Learning for Autonomous Driving using Task-Agnostic and Ego-Centric Motion Skills
Sep 24, 2022
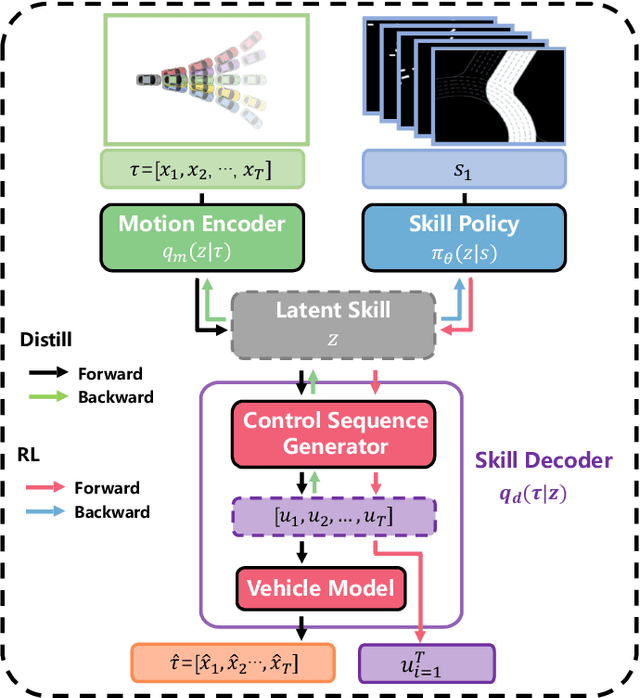

Efficient and effective exploration in continuous space is a central problem in applying reinforcement learning (RL) to autonomous driving. Skills learned from expert demonstrations or designed for specific tasks can benefit the exploration, but they are usually costly-collected, unbalanced/sub-optimal, or failing to transfer to diverse tasks. However, human drivers can adapt to varied driving tasks without demonstrations by taking efficient and structural explorations in the entire skill space rather than a limited space with task-specific skills. Inspired by the above fact, we propose an RL algorithm exploring all feasible motion skills instead of a limited set of task-specific and object-centric skills. Without demonstrations, our method can still perform well in diverse tasks. First, we build a task-agnostic and ego-centric (TaEc) motion skill library in a pure motion perspective, which is diverse enough to be reusable in different complex tasks. The motion skills are then encoded into a low-dimension latent skill space, in which RL can do exploration efficiently. Validations in various challenging driving scenarios demonstrate that our proposed method, TaEc-RL, outperforms its counterparts significantly in learning efficiency and task performance.