 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.
STORM: Spatio-Temporal Reconstruction Model for Large-Scale Outdoor Scenes
Dec 31, 2024



We present STORM, a spatio-temporal reconstruction model designed for reconstructing dynamic outdoor scenes from sparse observations. Existing dynamic reconstruction methods often rely on per-scene optimization, dense observations across space and time, and strong motion supervision, resulting in lengthy optimization times, limited generalization to novel views or scenes, and degenerated quality caused by noisy pseudo-labels for dynamics. To address these challenges, STORM leverages a data-driven Transformer architecture that directly infers dynamic 3D scene representations--parameterized by 3D Gaussians and their velocities--in a single forward pass. Our key design is to aggregate 3D Gaussians from all frames using self-supervised scene flows, transforming them to the target timestep to enable complete (i.e., "amodal") reconstructions from arbitrary viewpoints at any moment in time. As an emergent property, STORM automatically captures dynamic instances and generates high-quality masks using only reconstruction losses. Extensive experiments on public datasets show that STORM achieves precise dynamic scene reconstruction, surpassing state-of-the-art per-scene optimization methods (+4.3 to 6.6 PSNR) and existing feed-forward approaches (+2.1 to 4.7 PSNR) in dynamic regions. STORM reconstructs large-scale outdoor scenes in 200ms, supports real-time rendering, and outperforms competitors in scene flow estimation, improving 3D EPE by 0.422m and Acc5 by 28.02%. Beyond reconstruction, we showcase four additional applications of our model, illustrating the potential of self-supervised learning for broader dynamic scene understanding.
Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
Dec 05, 2024



Traffic simulation aims to learn a policy for traffic agents that, when unrolled in closed-loop, faithfully recovers the joint distribution of trajectories observed in the real world. Inspired by large language models, tokenized multi-agent policies have recently become the state-of-the-art in traffic simulation. However, they are typically trained through open-loop behavior cloning, and thus suffer from covariate shift when executed in closed-loop during simulation. In this work, we present Closest Among Top-K (CAT-K) rollouts, a simple yet effective closed-loop fine-tuning strategy to mitigate covariate shift. CAT-K fine-tuning only requires existing trajectory data, without reinforcement learning or generative adversarial imitation. Concretely, CAT-K fine-tuning enables a small 7M-parameter tokenized traffic simulation policy to outperform a 102M-parameter model from the same model family, achieving the top spot on the Waymo Sim Agent Challenge leaderboard at the time of submission. The code is available at https://github.com/NVlabs/catk.
Learning Multiple Initial Solutions to Optimization Problems
Nov 04, 2024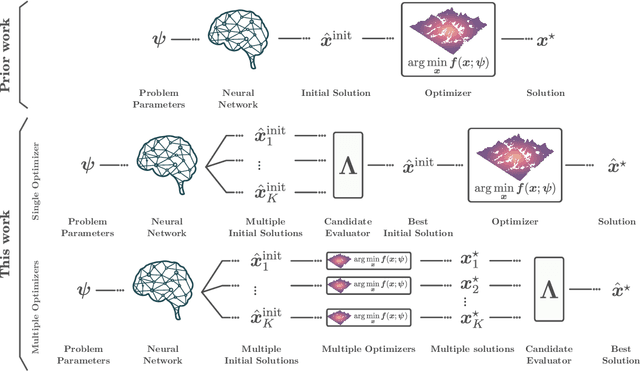
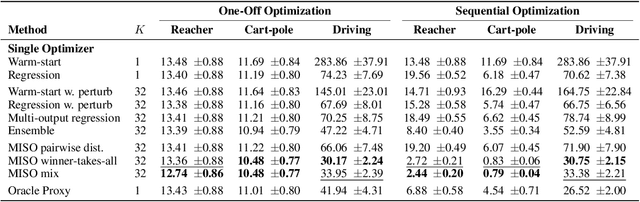
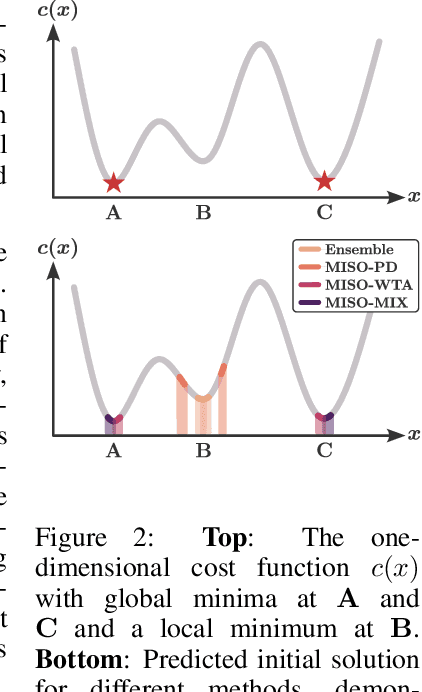

Sequentially solving similar optimization problems under strict runtime constraints is essential for many applications, such as robot control, autonomous driving, and portfolio management. The performance of local optimization methods in these settings is sensitive to the initial solution: poor initialization can lead to slow convergence or suboptimal solutions. To address this challenge, we propose learning to predict \emph{multiple} diverse initial solutions given parameters that define the problem instance. We introduce two strategies for utilizing multiple initial solutions: (i) a single-optimizer approach, where the most promising initial solution is chosen using a selection function, and (ii) a multiple-optimizers approach, where several optimizers, potentially run in parallel, are each initialized with a different solution, with the best solution chosen afterward. We validate our method on three optimal control benchmark tasks: cart-pole, reacher, and autonomous driving, using different optimizers: DDP, MPPI, and iLQR. We find significant and consistent improvement with our method across all evaluation settings and demonstrate that it efficiently scales with the number of initial solutions required. The code is available at $\href{https://github.com/EladSharony/miso}{\tt{https://github.com/EladSharony/miso}}$.
LoRD: Adapting Differentiable Driving Policies to Distribution Shifts
Oct 15, 2024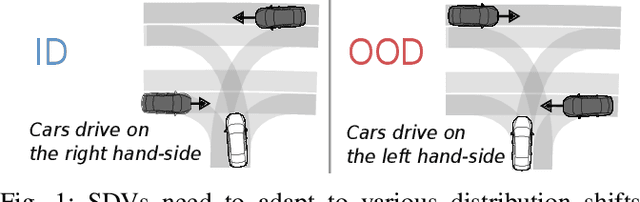
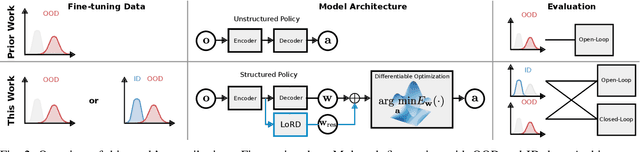

Distribution shifts between operational domains can severely affect the performance of learned models in self-driving vehicles (SDVs). While this is a well-established problem, prior work has mostly explored naive solutions such as fine-tuning, focusing on the motion prediction task. In this work, we explore novel adaptation strategies for differentiable autonomy stacks consisting of prediction, planning, and control, perform evaluation in closed-loop, and investigate the often-overlooked issue of catastrophic forgetting. Specifically, we introduce two simple yet effective techniques: a low-rank residual decoder (LoRD) and multi-task fine-tuning. Through experiments across three models conducted on two real-world autonomous driving datasets (nuPlan, exiD), we demonstrate the effectiveness of our methods and highlight a significant performance gap between open-loop and closed-loop evaluation in prior approaches. Our approach improves forgetting by up to 23.33% and the closed-loop OOD driving score by 8.83% in comparison to standard fine-tuning.
DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Jun 17, 2024



We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
Interactive Motion Planning for Autonomous Vehicles with Joint Optimization
Nov 02, 2023In highly interactive driving scenarios, the actions of one agent greatly influences those of its neighbors. Planning safe motions for autonomous vehicles in such interactive environments, therefore, requires reasoning about the impact of the ego's intended motion plan on nearby agents' behavior. Deep-learning-based models have recently achieved great success in trajectory prediction and many models in the literature allow for ego-conditioned prediction. However, leveraging ego-conditioned prediction remains challenging in downstream planning due to the complex nature of neural networks, limiting the planner structure to simple ones, e.g., sampling-based planner. Despite their ability to generate fine-grained high-quality motion plans, it is difficult for gradient-based planning algorithms, such as model predictive control (MPC), to leverage ego-conditioned prediction due to their iterative nature and need for gradient. We present Interactive Joint Planning (IJP) that bridges MPC with learned prediction models in a computationally scalable manner to provide us the best of both the worlds. In particular, IJP jointly optimizes over the behavior of the ego and the surrounding agents and leverages deep-learned prediction models as prediction priors that the join trajectory optimization tries to stay close to. Furthermore, by leveraging homotopy classes, our joint optimizer searches over diverse motion plans to avoid getting stuck at local minima. Closed-loop simulation result shows that IJP significantly outperforms the baselines that are either without joint optimization or running sampling-based planning.
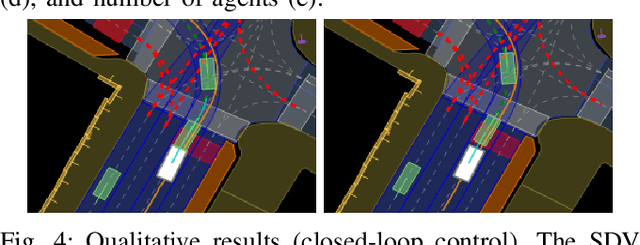
DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving
Oct 09, 2023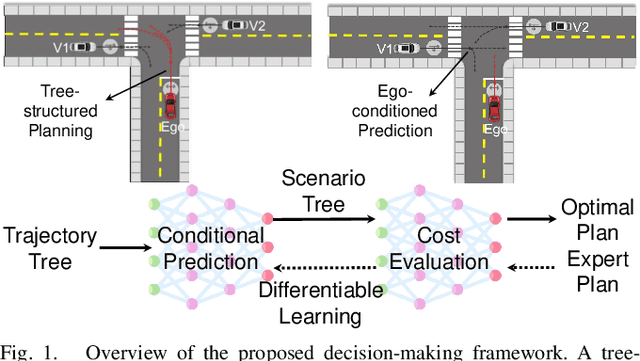
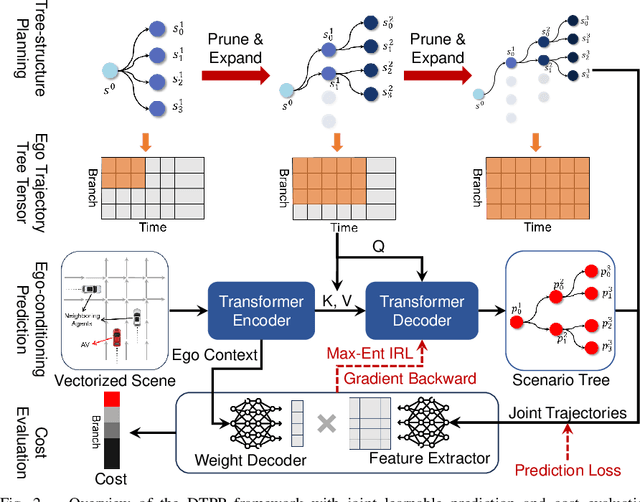
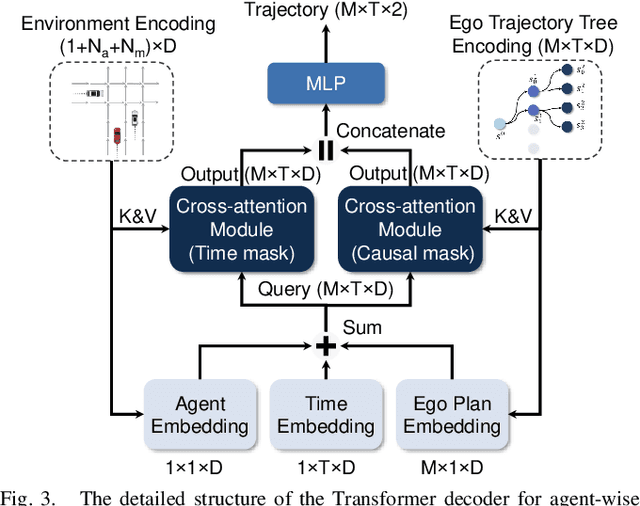

Motion prediction and cost evaluation are vital components in the decision-making system of autonomous vehicles. However, existing methods often ignore the importance of cost learning and treat them as separate modules. In this study, we employ a tree-structured policy planner and propose a differentiable joint training framework for both ego-conditioned prediction and cost models, resulting in a direct improvement of the final planning performance. For conditional prediction, we introduce a query-centric Transformer model that performs efficient ego-conditioned motion prediction. For planning cost, we propose a learnable context-aware cost function with latent interaction features, facilitating differentiable joint learning. We validate our proposed approach using the real-world nuPlan dataset and its associated planning test platform. Our framework not only matches state-of-the-art planning methods but outperforms other learning-based methods in planning quality, while operating more efficiently in terms of runtime. We show that joint training delivers significantly better performance than separate training of the two modules. Additionally, we find that tree-structured policy planning outperforms the conventional single-stage planning approach.
Partial-View Object View Synthesis via Filtered Inversion
Apr 03, 2023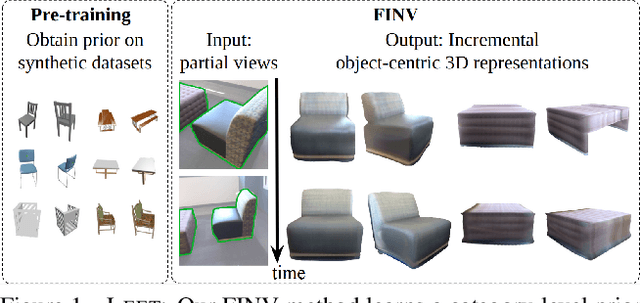
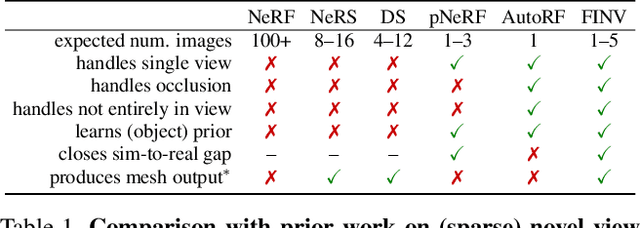
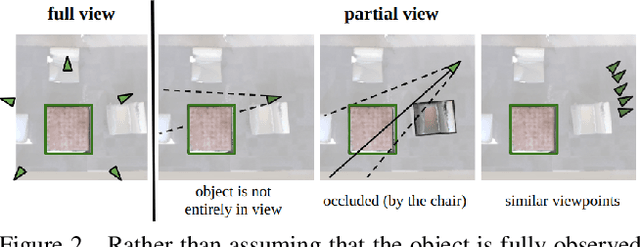
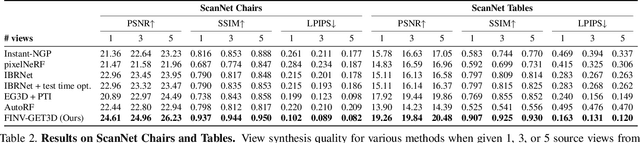
We propose Filtering Inversion (FINV), a learning framework and optimization process that predicts a renderable 3D object representation from one or few partial views. FINV addresses the challenge of synthesizing novel views of objects from partial observations, spanning cases where the object is not entirely in view, is partially occluded, or is only observed from similar views. To achieve this, FINV learns shape priors by training a 3D generative model. At inference, given one or more views of a novel real-world object, FINV first finds a set of latent codes for the object by inverting the generative model from multiple initial seeds. Maintaining the set of latent codes, FINV filters and resamples them after receiving each new observation, akin to particle filtering. The generator is then finetuned for each latent code on the available views in order to adapt to novel objects. We show that FINV successfully synthesizes novel views of real-world objects (e.g., chairs, tables, and cars), even if the generative prior is trained only on synthetic objects. The ability to address the sim-to-real problem allows FINV to be used for object categories without real-world datasets. FINV achieves state-of-the-art performance on multiple real-world datasets, recovers object shape and texture from partial and sparse views, is robust to occlusion, and is able to incrementally improve its representation with more observations.
Tree-structured Policy Planning with Learned Behavior Models
Jan 27, 2023Autonomous vehicles (AVs) need to reason about the multimodal behavior of neighboring agents while planning their own motion. Many existing trajectory planners seek a single trajectory that performs well under \emph{all} plausible futures simultaneously, ignoring bi-directional interactions and thus leading to overly conservative plans. Policy planning, whereby the ego agent plans a policy that reacts to the environment's multimodal behavior, is a promising direction as it can account for the action-reaction interactions between the AV and the environment. However, most existing policy planners do not scale to the complexity of real autonomous vehicle applications: they are either not compatible with modern deep learning prediction models, not interpretable, or not able to generate high quality trajectories. To fill this gap, we propose Tree Policy Planning (TPP), a policy planner that is compatible with state-of-the-art deep learning prediction models, generates multistage motion plans, and accounts for the influence of ego agent on the environment behavior. The key idea of TPP is to reduce the continuous optimization problem into a tractable discrete MDP through the construction of two tree structures: an ego trajectory tree for ego trajectory options, and a scenario tree for multi-modal ego-conditioned environment predictions. We demonstrate the efficacy of TPP in closed-loop simulations based on real-world nuScenes dataset and results show that TPP scales to realistic AV scenarios and significantly outperforms non-policy baselines.