 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Mixture of Low-Rank Experts for Sentiment Analysis and Emotion Recognition
May 20, 2025Multi-task learning (MTL) enables the efficient transfer of extra knowledge acquired from other tasks. The high correlation between multimodal sentiment analysis (MSA) and multimodal emotion recognition (MER) supports their joint training. However, existing methods primarily employ hard parameter sharing, ignoring parameter conflicts caused by complex task correlations. In this paper, we present a novel MTL method for MSA and MER, termed Multimodal Mixture of Low-Rank Experts (MMoLRE). MMoLRE utilizes shared and task-specific experts to distinctly model common and unique task characteristics, thereby avoiding parameter conflicts. Additionally, inspired by low-rank structures in the Mixture of Experts (MoE) framework, we design low-rank expert networks to reduce parameter and computational overhead as the number of experts increases. Extensive experiments on the CMU-MOSI and CMU-MOSEI benchmarks demonstrate that MMoLRE achieves state-of-the-art performance on the MSA task and competitive results on the MER task.
D3MES: Diffusion Transformer with multihead equivariant self-attention for 3D molecule generation
Jan 13, 2025



Understanding and predicting the diverse conformational states of molecules is crucial for advancing fields such as chemistry, material science, and drug development. Despite significant progress in generative models, accurately generating complex and biologically or material-relevant molecular structures remains a major challenge. In this work, we introduce a diffusion model for three-dimensional (3D) molecule generation that combines a classifiable diffusion model, Diffusion Transformer, with multihead equivariant self-attention. This method addresses two key challenges: correctly attaching hydrogen atoms in generated molecules through learning representations of molecules after hydrogen atoms are removed; and overcoming the limitations of existing models that cannot generate molecules across multiple classes simultaneously. The experimental results demonstrate that our model not only achieves state-of-the-art performance across several key metrics but also exhibits robustness and versatility, making it highly suitable for early-stage large-scale generation processes in molecular design, followed by validation and further screening to obtain molecules with specific properties.
Discovery of 2D Materials via Symmetry-Constrained Diffusion Model
Dec 24, 2024



Generative model for 2D materials has shown significant promise in accelerating the material discovery process. The stability and performance of these materials are strongly influenced by their underlying symmetry. However, existing generative models for 2D materials often neglect symmetry constraints, which limits both the diversity and quality of the generated structures. Here, we introduce a symmetry-constrained diffusion model (SCDM) that integrates space group symmetry into the generative process. By incorporating Wyckoff positions, the model ensures adherence to symmetry principles, leading to the generation of 2,000 candidate structures. DFT calculations were conducted to evaluate the convex hull energies of these structures after structural relaxation. From the generated samples, 843 materials that met the energy stability criteria (Ehull < 0.6 eV/atom) were identified. Among these, six candidates were selected for further stability analysis, including phonon band structure evaluations and electronic properties investigations, all of which exhibited phonon spectrum stability. To benchmark the performance of SCDM, a symmetry-unconstrained diffusion model was also evaluated via crystal structure prediction model. The results highlight that incorporating symmetry constraints enhances the effectiveness of generated 2D materials, making a contribution to the discovery of 2D materials through generative modeling.
Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
Dec 05, 2024



Traffic simulation aims to learn a policy for traffic agents that, when unrolled in closed-loop, faithfully recovers the joint distribution of trajectories observed in the real world. Inspired by large language models, tokenized multi-agent policies have recently become the state-of-the-art in traffic simulation. However, they are typically trained through open-loop behavior cloning, and thus suffer from covariate shift when executed in closed-loop during simulation. In this work, we present Closest Among Top-K (CAT-K) rollouts, a simple yet effective closed-loop fine-tuning strategy to mitigate covariate shift. CAT-K fine-tuning only requires existing trajectory data, without reinforcement learning or generative adversarial imitation. Concretely, CAT-K fine-tuning enables a small 7M-parameter tokenized traffic simulation policy to outperform a 102M-parameter model from the same model family, achieving the top spot on the Waymo Sim Agent Challenge leaderboard at the time of submission. The code is available at https://github.com/NVlabs/catk.
TrafficBots V1.5: Traffic Simulation via Conditional VAEs and Transformers with Relative Pose Encoding
Jun 16, 2024
In this technical report we present TrafficBots V1.5, a baseline method for the closed-loop simulation of traffic agents. TrafficBots V1.5 achieves baseline-level performance and a 3rd place ranking in the Waymo Open Sim Agents Challenge (WOSAC) 2024. It is a simple baseline that combines TrafficBots, a CVAE-based multi-agent policy conditioned on each agent's individual destination and personality, and HPTR, the heterogeneous polyline transformer with relative pose encoding. To improve the performance on the WOSAC leaderboard, we apply scheduled teacher-forcing at the training time and we filter the sampled scenarios at the inference time. The code is available at https://github.com/zhejz/TrafficBotsV1.5.
RESenv: A Realistic Earthquake Simulation Environment based on Unreal Engine
Nov 13, 2023

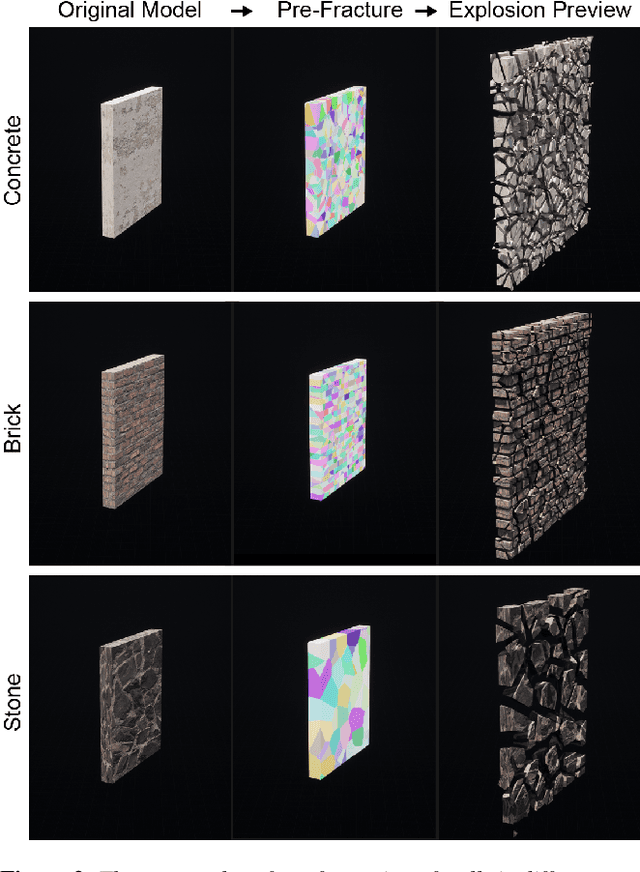

Earthquakes have a significant impact on societies and economies, driving the need for effective search and rescue strategies. With the growing role of AI and robotics in these operations, high-quality synthetic visual data becomes crucial. Current simulation methods, mostly focusing on single building damages, often fail to provide realistic visuals for complex urban settings. To bridge this gap, we introduce an innovative earthquake simulation system using the Chaos Physics System in Unreal Engine. Our approach aims to offer detailed and realistic visual simulations essential for AI and robotic training in rescue missions. By integrating real seismic waveform data, we enhance the authenticity and relevance of our simulations, ensuring they closely mirror real-world earthquake scenarios. Leveraging the advanced capabilities of Unreal Engine, our system delivers not only high-quality visualisations but also real-time dynamic interactions, making the simulated environments more immersive and responsive. By providing advanced renderings, accurate physical interactions, and comprehensive geological movements, our solution outperforms traditional methods in efficiency and user experience. Our simulation environment stands out in its detail and realism, making it a valuable tool for AI tasks such as path planning and image recognition related to earthquake responses. We validate our approach through three AI-based tasks: similarity detection, path planning, and image segmentation.
Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose Encoding
Oct 19, 2023



The real-world deployment of an autonomous driving system requires its components to run on-board and in real-time, including the motion prediction module that predicts the future trajectories of surrounding traffic participants. Existing agent-centric methods have demonstrated outstanding performance on public benchmarks. However, they suffer from high computational overhead and poor scalability as the number of agents to be predicted increases. To address this problem, we introduce the K-nearest neighbor attention with relative pose encoding (KNARPE), a novel attention mechanism allowing the pairwise-relative representation to be used by Transformers. Then, based on KNARPE we present the Heterogeneous Polyline Transformer with Relative pose encoding (HPTR), a hierarchical framework enabling asynchronous token update during the online inference. By sharing contexts among agents and reusing the unchanged contexts, our approach is as efficient as scene-centric methods, while performing on par with state-of-the-art agent-centric methods. Experiments on Waymo and Argoverse-2 datasets show that HPTR achieves superior performance among end-to-end methods that do not apply expensive post-processing or model ensembling. The code is available at https://github.com/zhejz/HPTR.
A Multiplicative Value Function for Safe and Efficient Reinforcement Learning
Mar 07, 2023An emerging field of sequential decision problems is safe Reinforcement Learning (RL), where the objective is to maximize the reward while obeying safety constraints. Being able to handle constraints is essential for deploying RL agents in real-world environments, where constraint violations can harm the agent and the environment. To this end, we propose a safe model-free RL algorithm with a novel multiplicative value function consisting of a safety critic and a reward critic. The safety critic predicts the probability of constraint violation and discounts the reward critic that only estimates constraint-free returns. By splitting responsibilities, we facilitate the learning task leading to increased sample efficiency. We integrate our approach into two popular RL algorithms, Proximal Policy Optimization and Soft Actor-Critic, and evaluate our method in four safety-focused environments, including classical RL benchmarks augmented with safety constraints and robot navigation tasks with images and raw Lidar scans as observations. Finally, we make the zero-shot sim-to-real transfer where a differential drive robot has to navigate through a cluttered room. Our code can be found at https://github.com/nikeke19/Safe-Mult-RL.
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
Mar 07, 2023



Data-driven simulation has become a favorable way to train and test autonomous driving algorithms. The idea of replacing the actual environment with a learned simulator has also been explored in model-based reinforcement learning in the context of world models. In this work, we show data-driven traffic simulation can be formulated as a world model. We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving, and based on TrafficBots we obtain a world model tailored for the planning module of autonomous vehicles. Existing data-driven traffic simulators are lacking configurability and scalability. To generate configurable behaviors, for each agent we introduce a destination as navigational information, and a time-invariant latent personality that specifies the behavioral style. To improve the scalability, we present a new scheme of positional encoding for angles, allowing all agents to share the same vectorized context and the use of an architecture based on dot-product attention. As a result, we can simulate all traffic participants seen in dense urban scenarios. Experiments on the Waymo open motion dataset show TrafficBots can simulate realistic multi-agent behaviors and achieve good performance on the motion prediction task.
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
Aug 26, 2021End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird's-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the more challenging CARLA LeaderBoard.