 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving
Dec 23, 2025Simulators can generate virtually unlimited driving data, yet imitation learning policies in simulation still struggle to achieve robust closed-loop performance. Motivated by this gap, we empirically study how misalignment between privileged expert demonstrations and sensor-based student observations can limit the effectiveness of imitation learning. More precisely, experts have significantly higher visibility (e.g., ignoring occlusions) and far lower uncertainty (e.g., knowing other vehicles' actions), making them difficult to imitate reliably. Furthermore, navigational intent (i.e., the route to follow) is under-specified in student models at test time via only a single target point. We demonstrate that these asymmetries can measurably limit driving performance in CARLA and offer practical interventions to address them. After careful modifications to narrow the gaps between expert and student, our TransFuser v6 (TFv6) student policy achieves a new state of the art on all major publicly available CARLA closed-loop benchmarks, reaching 95 DS on Bench2Drive and more than doubling prior performances on Longest6~v2 and Town13. Additionally, by integrating perception supervision from our dataset into a shared sim-to-real pipeline, we show consistent gains on the NAVSIM and Waymo Vision-Based End-to-End driving benchmarks. Our code, data, and models are publicly available at https://github.com/autonomousvision/lead.
STORM: Spatio-Temporal Reconstruction Model for Large-Scale Outdoor Scenes
Dec 31, 2024



We present STORM, a spatio-temporal reconstruction model designed for reconstructing dynamic outdoor scenes from sparse observations. Existing dynamic reconstruction methods often rely on per-scene optimization, dense observations across space and time, and strong motion supervision, resulting in lengthy optimization times, limited generalization to novel views or scenes, and degenerated quality caused by noisy pseudo-labels for dynamics. To address these challenges, STORM leverages a data-driven Transformer architecture that directly infers dynamic 3D scene representations--parameterized by 3D Gaussians and their velocities--in a single forward pass. Our key design is to aggregate 3D Gaussians from all frames using self-supervised scene flows, transforming them to the target timestep to enable complete (i.e., "amodal") reconstructions from arbitrary viewpoints at any moment in time. As an emergent property, STORM automatically captures dynamic instances and generates high-quality masks using only reconstruction losses. Extensive experiments on public datasets show that STORM achieves precise dynamic scene reconstruction, surpassing state-of-the-art per-scene optimization methods (+4.3 to 6.6 PSNR) and existing feed-forward approaches (+2.1 to 4.7 PSNR) in dynamic regions. STORM reconstructs large-scale outdoor scenes in 200ms, supports real-time rendering, and outperforms competitors in scene flow estimation, improving 3D EPE by 0.422m and Acc5 by 28.02%. Beyond reconstruction, we showcase four additional applications of our model, illustrating the potential of self-supervised learning for broader dynamic scene understanding.
Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
Dec 05, 2024



Traffic simulation aims to learn a policy for traffic agents that, when unrolled in closed-loop, faithfully recovers the joint distribution of trajectories observed in the real world. Inspired by large language models, tokenized multi-agent policies have recently become the state-of-the-art in traffic simulation. However, they are typically trained through open-loop behavior cloning, and thus suffer from covariate shift when executed in closed-loop during simulation. In this work, we present Closest Among Top-K (CAT-K) rollouts, a simple yet effective closed-loop fine-tuning strategy to mitigate covariate shift. CAT-K fine-tuning only requires existing trajectory data, without reinforcement learning or generative adversarial imitation. Concretely, CAT-K fine-tuning enables a small 7M-parameter tokenized traffic simulation policy to outperform a 102M-parameter model from the same model family, achieving the top spot on the Waymo Sim Agent Challenge leaderboard at the time of submission. The code is available at https://github.com/NVlabs/catk.
Gen-Drive: Enhancing Diffusion Generative Driving Policies with Reward Modeling and Reinforcement Learning Fine-tuning
Oct 08, 2024Autonomous driving necessitates the ability to reason about future interactions between traffic agents and to make informed evaluations for planning. This paper introduces the \textit{Gen-Drive} framework, which shifts from the traditional prediction and deterministic planning framework to a generation-then-evaluation planning paradigm. The framework employs a behavior diffusion model as a scene generator to produce diverse possible future scenarios, thereby enhancing the capability for joint interaction reasoning. To facilitate decision-making, we propose a scene evaluator (reward) model, trained with pairwise preference data collected through VLM assistance, thereby reducing human workload and enhancing scalability. Furthermore, we utilize an RL fine-tuning framework to improve the generation quality of the diffusion model, rendering it more effective for planning tasks. We conduct training and closed-loop planning tests on the nuPlan dataset, and the results demonstrate that employing such a generation-then-evaluation strategy outperforms other learning-based approaches. Additionally, the fine-tuned generative driving policy shows significant enhancements in planning performance. We further demonstrate that utilizing our learned reward model for evaluation or RL fine-tuning leads to better planning performance compared to relying on human-designed rewards. Project website: https://mczhi.github.io/GenDrive.
Hierarchical Imitation Learning for Stochastic Environments
Sep 25, 2023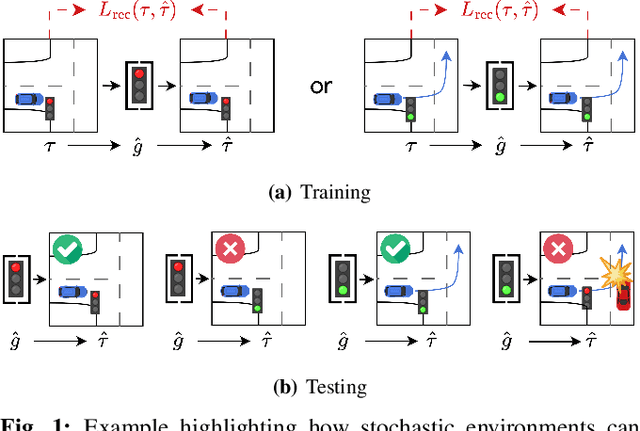
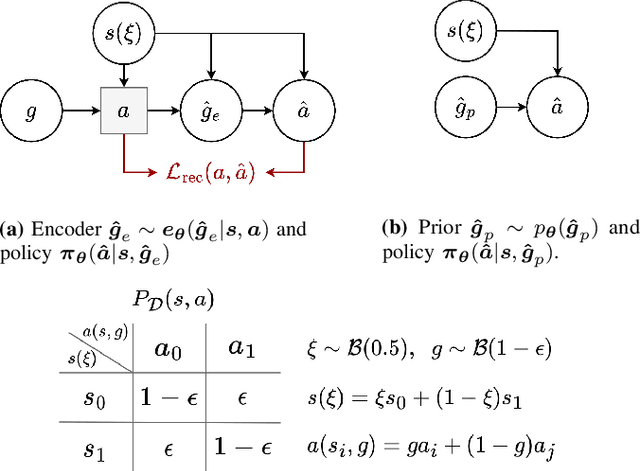
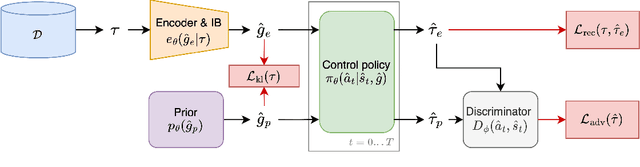
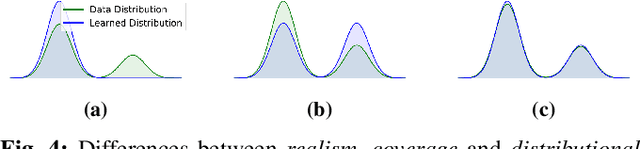
Many applications of imitation learning require the agent to generate the full distribution of behaviour observed in the training data. For example, to evaluate the safety of autonomous vehicles in simulation, accurate and diverse behaviour models of other road users are paramount. Existing methods that improve this distributional realism typically rely on hierarchical policies. These condition the policy on types such as goals or personas that give rise to multi-modal behaviour. However, such methods are often inappropriate for stochastic environments where the agent must also react to external factors: because agent types are inferred from the observed future trajectory during training, these environments require that the contributions of internal and external factors to the agent behaviour are disentangled and only internal factors, i.e., those under the agent's control, are encoded in the type. Encoding future information about external factors leads to inappropriate agent reactions during testing, when the future is unknown and types must be drawn independently from the actual future. We formalize this challenge as distribution shift in the conditional distribution of agent types under environmental stochasticity. We propose Robust Type Conditioning (RTC), which eliminates this shift with adversarial training under randomly sampled types. Experiments on two domains, including the large-scale Waymo Open Motion Dataset, show improved distributional realism while maintaining or improving task performance compared to state-of-the-art baselines.
Particle-Based Score Estimation for State Space Model Learning in Autonomous Driving
Dec 14, 2022Multi-object state estimation is a fundamental problem for robotic applications where a robot must interact with other moving objects. Typically, other objects' relevant state features are not directly observable, and must instead be inferred from observations. Particle filtering can perform such inference given approximate transition and observation models. However, these models are often unknown a priori, yielding a difficult parameter estimation problem since observations jointly carry transition and observation noise. In this work, we consider learning maximum-likelihood parameters using particle methods. Recent methods addressing this problem typically differentiate through time in a particle filter, which requires workarounds to the non-differentiable resampling step, that yield biased or high variance gradient estimates. By contrast, we exploit Fisher's identity to obtain a particle-based approximation of the score function (the gradient of the log likelihood) that yields a low variance estimate while only requiring stepwise differentiation through the transition and observation models. We apply our method to real data collected from autonomous vehicles (AVs) and show that it learns better models than existing techniques and is more stable in training, yielding an effective smoother for tracking the trajectories of vehicles around an AV.
Symphony: Learning Realistic and Diverse Agents for Autonomous Driving Simulation
May 06, 2022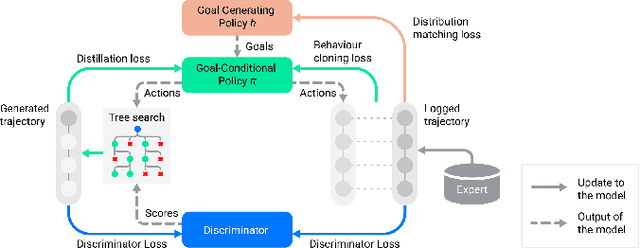
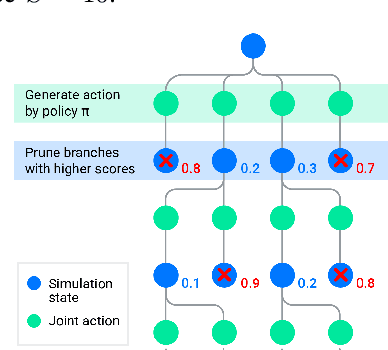
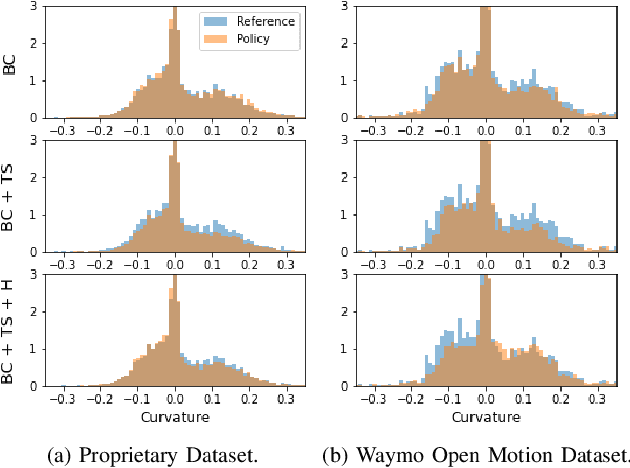
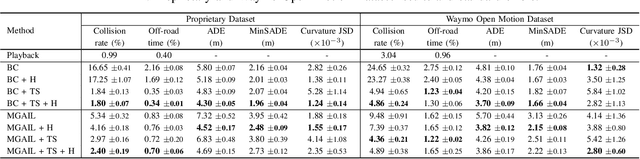
Simulation is a crucial tool for accelerating the development of autonomous vehicles. Making simulation realistic requires models of the human road users who interact with such cars. Such models can be obtained by applying learning from demonstration (LfD) to trajectories observed by cars already on the road. However, existing LfD methods are typically insufficient, yielding policies that frequently collide or drive off the road. To address this problem, we propose Symphony, which greatly improves realism by combining conventional policies with a parallel beam search. The beam search refines these policies on the fly by pruning branches that are unfavourably evaluated by a discriminator. However, it can also harm diversity, i.e., how well the agents cover the entire distribution of realistic behaviour, as pruning can encourage mode collapse. Symphony addresses this issue with a hierarchical approach, factoring agent behaviour into goal generation and goal conditioning. The use of such goals ensures that agent diversity neither disappears during adversarial training nor is pruned away by the beam search. Experiments on both proprietary and open Waymo datasets confirm that Symphony agents learn more realistic and diverse behaviour than several baselines.
Implicit Communication as Minimum Entropy Coupling
Jul 17, 2021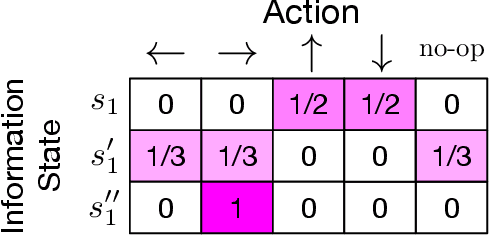
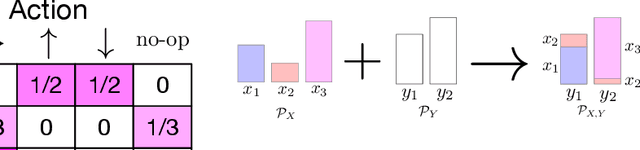

In many common-payoff games, achieving good performance requires players to develop protocols for communicating their private information implicitly -- i.e., using actions that have non-communicative effects on the environment. Multi-agent reinforcement learning practitioners typically approach this problem using independent learning methods in the hope that agents will learn implicit communication as a byproduct of expected return maximization. Unfortunately, independent learning methods are incapable of doing this in many settings. In this work, we isolate the implicit communication problem by identifying a class of partially observable common-payoff games, which we call implicit referential games, whose difficulty can be attributed to implicit communication. Next, we introduce a principled method based on minimum entropy coupling that leverages the structure of implicit referential games, yielding a new perspective on implicit communication. Lastly, we show that this method can discover performant implicit communication protocols in settings with very large spaces of messages.
Snowflake: Scaling GNNs to High-Dimensional Continuous Control via Parameter Freezing
Mar 01, 2021
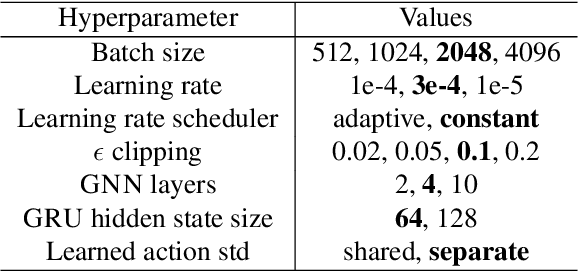
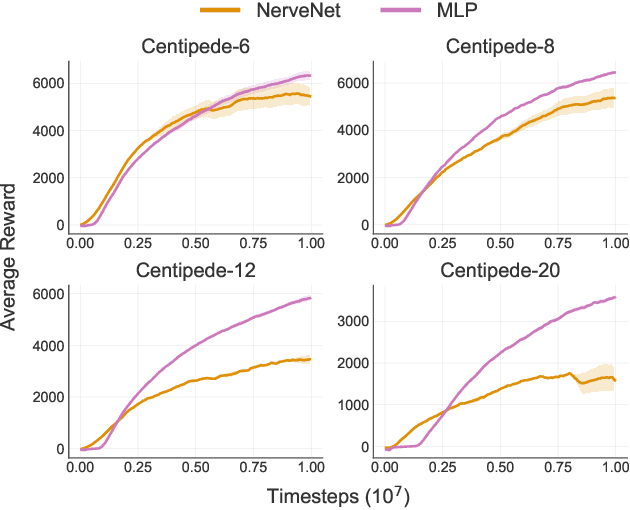
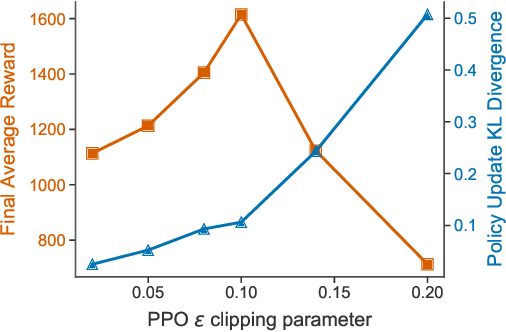
Recent research has shown that Graph Neural Networks (GNNs) can learn policies for locomotion control that are as effective as a typical multi-layer perceptron (MLP), with superior transfer and multi-task performance (Wang et al., 2018; Huang et al., 2020). Results have so far been limited to training on small agents, with the performance of GNNs deteriorating rapidly as the number of sensors and actuators grows. A key motivation for the use of GNNs in the supervised learning setting is their applicability to large graphs, but this benefit has not yet been realised for locomotion control. We identify the weakness with a common GNN architecture that causes this poor scaling: overfitting in the MLPs within the network that encode, decode, and propagate messages. To combat this, we introduce Snowflake, a GNN training method for high-dimensional continuous control that freezes parameters in parts of the network that suffer from overfitting. Snowflake significantly boosts the performance of GNNs for locomotion control on large agents, now matching the performance of MLPs, and with superior transfer properties.
My Body is a Cage: the Role of Morphology in Graph-Based Incompatible Control
Oct 05, 2020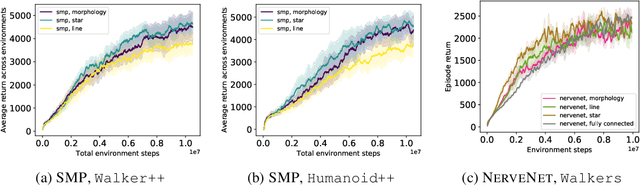

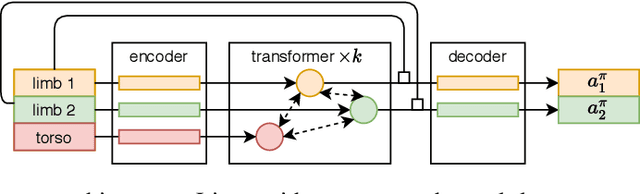
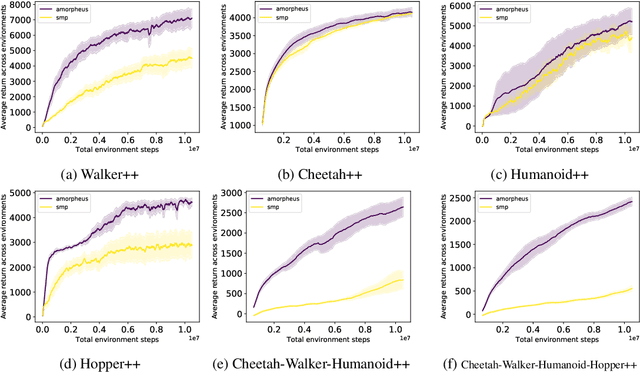
Multitask Reinforcement Learning is a promising way to obtain models with better performance, generalisation, data efficiency, and robustness. Most existing work is limited to compatible settings, where the state and action space dimensions are the same across tasks. Graph Neural Networks (GNN) are one way to address incompatible environments, because they can process graphs of arbitrary size. They also allow practitioners to inject biases encoded in the structure of the input graph. Existing work in graph-based continuous control uses the physical morphology of the agent to construct the input graph, i.e., encoding limb features as node labels and using edges to connect the nodes if their corresponded limbs are physically connected. In this work, we present a series of ablations on existing methods that show that morphological information encoded in the graph does not improve their performance. Motivated by the hypothesis that any benefits GNNs extract from the graph structure are outweighed by difficulties they create for message passing, we also propose Amorpheus, a transformer-based approach. Further results show that, while Amorpheus ignores the morphological information that GNNs encode, it nonetheless substantially outperforms GNN-based methods.