 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Body is a Cage: the Role of Morphology in Graph-Based Incompatible Control
Oct 05, 2020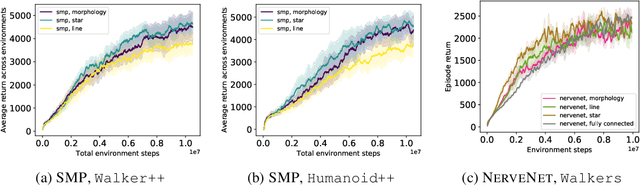

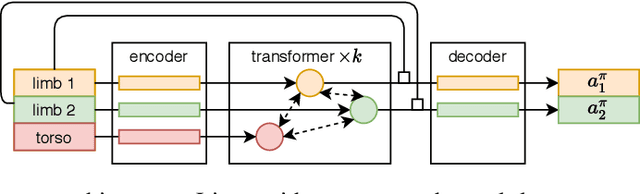
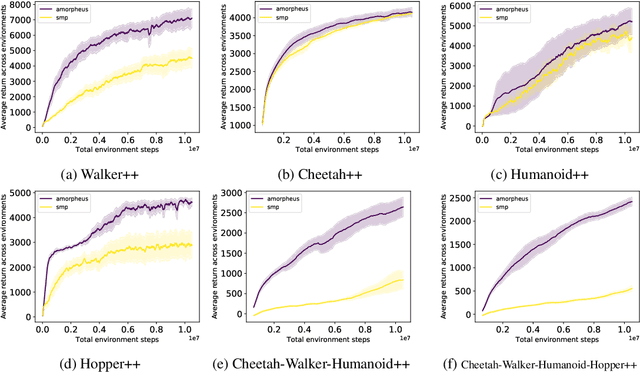
Multitask Reinforcement Learning is a promising way to obtain models with better performance, generalisation, data efficiency, and robustness. Most existing work is limited to compatible settings, where the state and action space dimensions are the same across tasks. Graph Neural Networks (GNN) are one way to address incompatible environments, because they can process graphs of arbitrary size. They also allow practitioners to inject biases encoded in the structure of the input graph. Existing work in graph-based continuous control uses the physical morphology of the agent to construct the input graph, i.e., encoding limb features as node labels and using edges to connect the nodes if their corresponded limbs are physically connected. In this work, we present a series of ablations on existing methods that show that morphological information encoded in the graph does not improve their performance. Motivated by the hypothesis that any benefits GNNs extract from the graph structure are outweighed by difficulties they create for message passing, we also propose Amorpheus, a transformer-based approach. Further results show that, while Amorpheus ignores the morphological information that GNNs encode, it nonetheless substantially outperforms GNN-based methods.
The Impact of Non-stationarity on Generalisation in Deep Reinforcement Learning
Jun 16, 2020
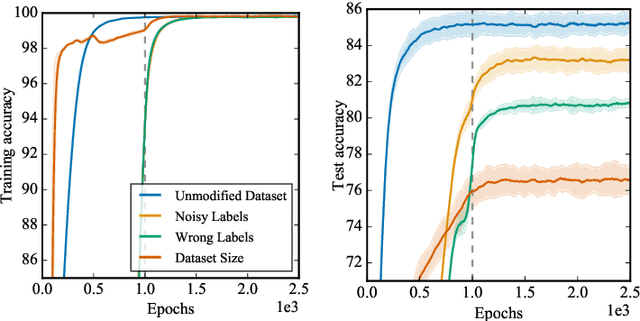
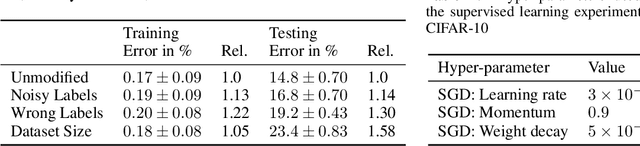
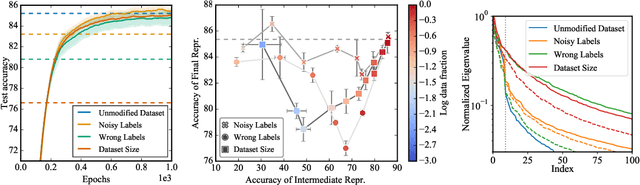
Non-stationarity arises in Reinforcement Learning (RL) even in stationary environments. Most RL algorithms collect new data throughout training, using a non-stationary behaviour policy. Furthermore, training targets in RL can change even with a fixed state distribution when the policy, critic, or bootstrap values are updated. We study these types of non-stationarity in supervised learning settings as well as in RL, finding that they can lead to worse generalisation performance when using deep neural network function approximators. Consequently, to improve generalisation of deep RL agents, we propose Iterated Relearning (ITER). ITER augments standard RL training by repeated knowledge transfer of the current policy into a freshly initialised network, which thereby experiences less non-stationarity during training. Experimentally, we show that ITER improves performance on the challenging generalisation benchmarks ProcGen and Multiroom.
Privileged Information Dropout in Reinforcement Learning
May 19, 2020



Using privileged information during training can improve the sample efficiency and performance of machine learning systems. This paradigm has been applied to reinforcement learning (RL), primarily in the form of distillation or auxiliary tasks, and less commonly in the form of augmenting the inputs of agents. In this work, we investigate Privileged Information Dropout (\pid) for achieving the latter which can be applied equally to value-based and policy-based RL algorithms. Within a simple partially-observed environment, we demonstrate that \pid outperforms alternatives for leveraging privileged information, including distillation and auxiliary tasks, and can successfully utilise different types of privileged information. Finally, we analyse its effect on the learned representations.
Multi-agent Hierarchical Reinforcement Learning with Dynamic Termination
Oct 21, 2019
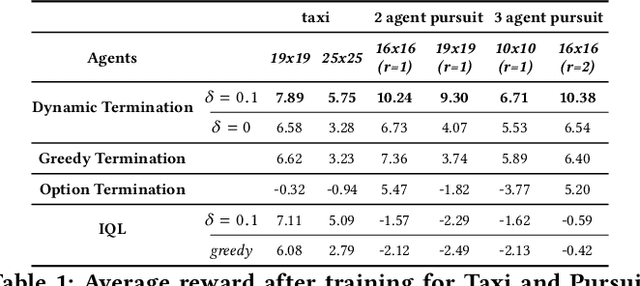
In a multi-agent system, an agent's optimal policy will typically depend on the policies chosen by others. Therefore, a key issue in multi-agent systems research is that of predicting the behaviours of others, and responding promptly to changes in such behaviours. One obvious possibility is for each agent to broadcast their current intention, for example, the currently executed option in a hierarchical reinforcement learning framework. However, this approach results in inflexibility of agents if options have an extended duration and are dynamic. While adjusting the executed option at each step improves flexibility from a single-agent perspective, frequent changes in options can induce inconsistency between an agent's actual behaviour and its broadcast intention. In order to balance flexibility and predictability, we propose a dynamic termination Bellman equation that allows the agents to flexibly terminate their options. We evaluate our model empirically on a set of multi-agent pursuit and taxi tasks, and show that our agents learn to adapt flexibly across scenarios that require different termination behaviours.
Deep Residual Reinforcement Learning
May 03, 2019
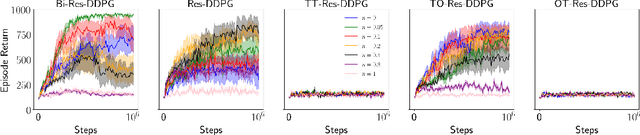
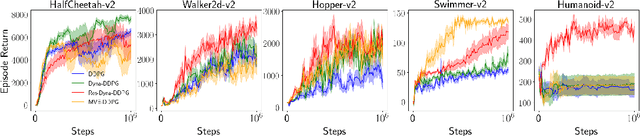
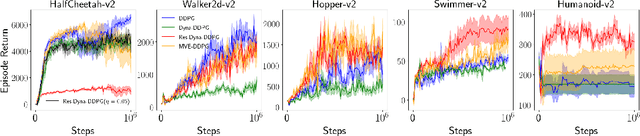
We revisit residual algorithms in both model-free and model-based reinforcement learning settings. We propose the bidirectional target network technique to stabilize residual algorithms, yielding a residual version of DDPG that significantly outperforms vanilla DDPG in the DeepMind Control Suite benchmark. Moreover, we find the residual algorithm an effective approach to the distribution mismatch problem in model-based planning. Compared with the existing TD($k$) method, our residual-based method makes weaker assumptions about the model and yields a greater performance boost.
Generalized Off-Policy Actor-Critic
Mar 27, 2019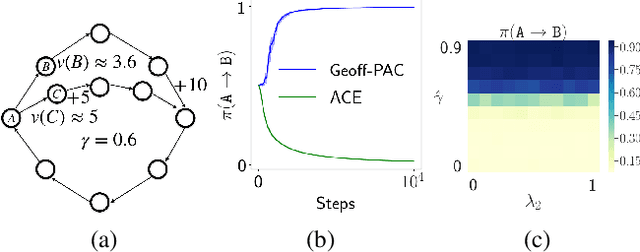



We propose a new objective, the counterfactual objective, unifying existing objectives for off-policy policy gradient algorithms in the continuing reinforcement learning (RL) setting. Compared to the commonly used excursion objective, which can be misleading about the performance of the target policy when deployed, our new objective better predicts such performance. We prove the Generalized Off-Policy Policy Gradient Theorem to compute the policy gradient of the counterfactual objective and use an emphatic approach to get an unbiased sample from this policy gradient, yielding the Generalized Off-Policy Actor-Critic (Geoff-PAC) algorithm. We demonstrate the merits of Geoff-PAC over existing algorithms in Mujoco robot simulation tasks, the first empirical success of emphatic algorithms in prevailing deep RL benchmarks.
Multi-Agent Common Knowledge Reinforcement Learning
Nov 05, 2018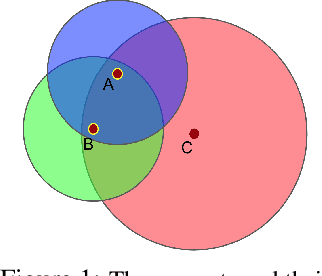

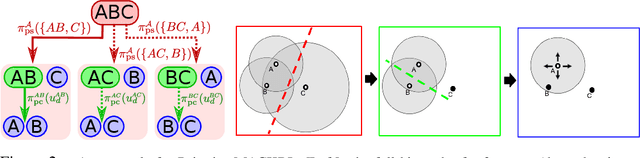
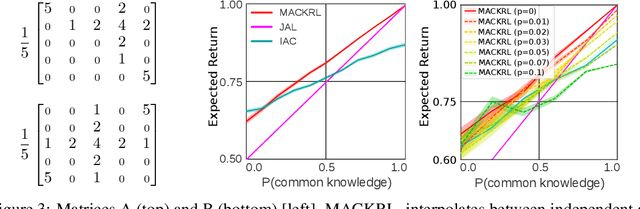
In multi-agent reinforcement learning, centralised policies can only be executed if agents have access to either the global state or an instantaneous communication channel. An alternative approach that circumvents this limitation is to use centralised training of a set of decentralised policies. However, such policies severely limit the agents' ability to coordinate. We propose multi-agent common knowledge reinforcement learning (MACKRL), which strikes a middle ground between these two extremes. Our approach is based on the insight that, even in partially observable settings, subsets of agents often have some common knowledge that they can exploit to coordinate their behaviour. Common knowledge can arise, e.g., if all agents can reliably observe things in their own field of view and know the field of view of other agents. Using this additional information, it is possible to find a centralised policy that conditions only on agents' common knowledge and that can be executed in a decentralised fashion. A resulting challenge is then to determine at what level agents should coordinate. While the common knowledge shared among all agents may not contain much valuable information, there may be subgroups of agents that share common knowledge useful for coordination. MACKRL addresses this challenge using a hierarchical approach: at each level, a controller can either select a joint action for the agents in a given subgroup, or propose a partition of the agents into smaller subgroups whose actions are then selected by controllers at the next level. While action selection involves sampling hierarchically, learning updates are based on the probability of the joint action, calculated by marginalising across the possible decisions of the hierarchy. We show promising results on both a proof-of-concept matrix game and a multi-agent version of StarCraft II Micromanagement.