 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-Cost Teleoperation: Augmenting GELLO with Force
Jul 18, 2025

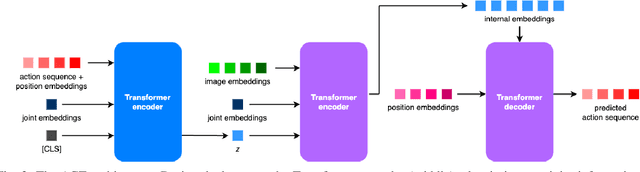

In this work we extend the low-cost GELLO teleoperation system, initially designed for joint position control, with additional force information. Our first extension is to implement force feedback, allowing users to feel resistance when interacting with the environment. Our second extension is to add force information into the data collection process and training of imitation learning models. We validate our additions by implementing these on a GELLO system with a Franka Panda arm as the follower robot, performing a user study, and comparing the performance of policies trained with and without force information on a range of simulated and real dexterous manipulation tasks. Qualitatively, users with robotics experience preferred our controller, and the addition of force inputs improved task success on the majority of tasks.
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
Jul 10, 2024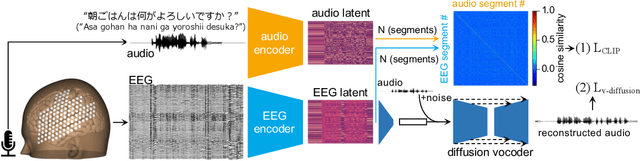

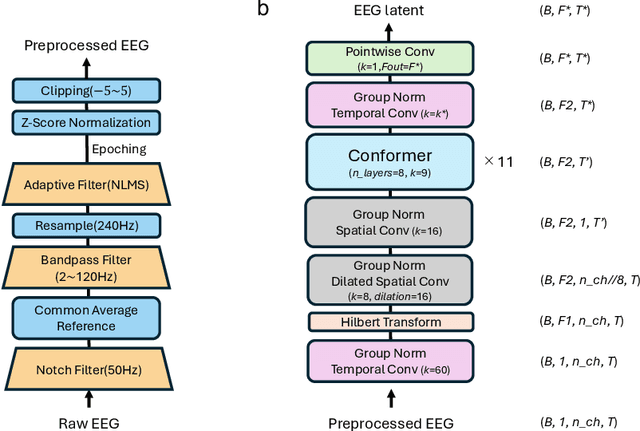

Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
Preference-Learning Emitters for Mixed-Initiative Quality-Diversity Algorithms
Oct 25, 2022
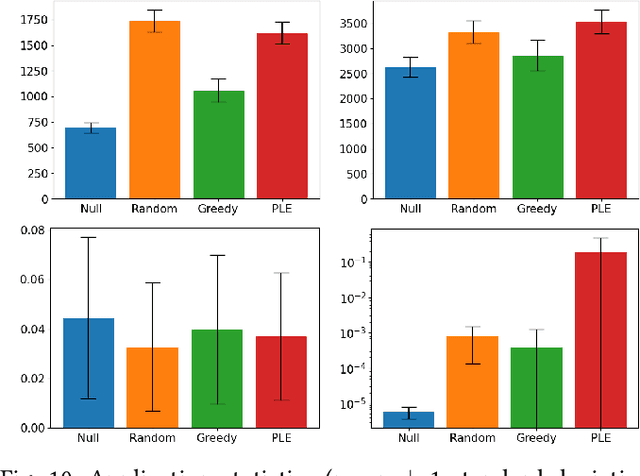

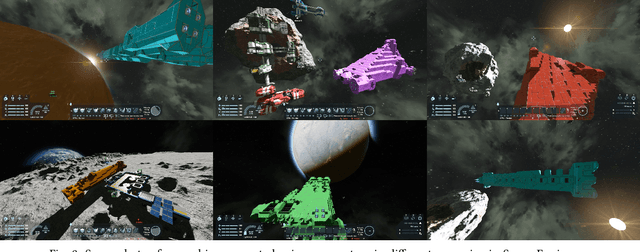
In mixed-initiative co-creation tasks, where a human and a machine jointly create items, it is valuable for the generative system to provide multiple relevant suggestions to the designer. Quality-diversity algorithms have been commonly used for this, as they can provide diverse suggestions that are representative of salient areas of the solution space, showcasing solutions with both high fitness and different properties that the designer might be interested in. Since these suggestions are what drives the search process, it is important that they provide the right inspiration for the designer, as well as not stray too far away from the search trajectory, i.e., they should be aligned with what the designer is looking for. Additionally, in most cases, many interactions with the system are required before the designer is content with a solution. In this work, we tackle both of these problems with an interactive constrained MAP-Elites system by crafting emitters that are able to learn the preferences of the designer and use them in automated hidden steps. By learning such preferences, we remain aligned with the designer's intentions, and by applying automatic steps, we generate more solutions per system interaction, giving a larger number of choices to the designer and speeding up the search process. We propose a general framework for preference-learning emitters and test it on a procedural content generation task in the video game Space Engineers. In an internal study, we show that preference-learning emitters allow users to more quickly find relevant solutions.
Surrogate Infeasible Fitness Acquirement FI-2Pop for Procedural Content Generation
May 12, 2022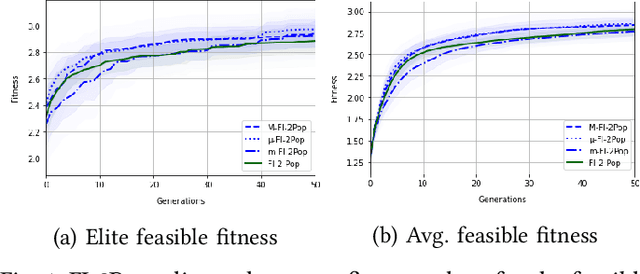
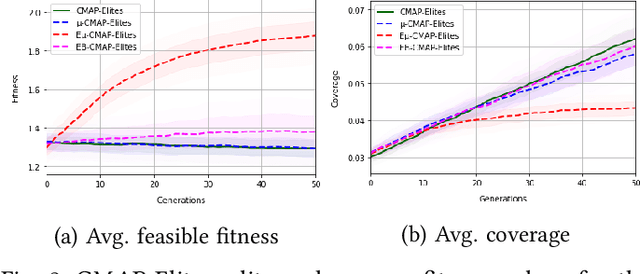

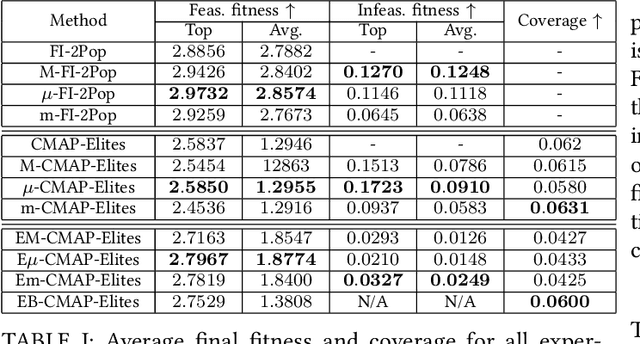
When generating content for video games using procedural content generation (PCG), the goal is to create functional assets of high quality. Prior work has commonly leveraged the feasible-infeasible two-population (FI-2Pop) constrained optimisation algorithm for PCG, sometimes in combination with the multi-dimensional archive of phenotypic-elites (MAP-Elites) algorithm for finding a set of diverse solutions. However, the fitness function for the infeasible population only takes into account the number of constraints violated. In this paper we present a variant of FI-2Pop in which a surrogate model is trained to predict the fitness of feasible children from infeasible parents, weighted by the probability of producing feasible children. This drives selection towards higher-fitness, feasible solutions. We demonstrate our method on the task of generating spaceships for Space Engineers, showing improvements over both standard FI-2Pop, and the more recent multi-emitter constrained MAP-Elites algorithm.
On the link between conscious function and general intelligence in humans and machines
Mar 24, 2022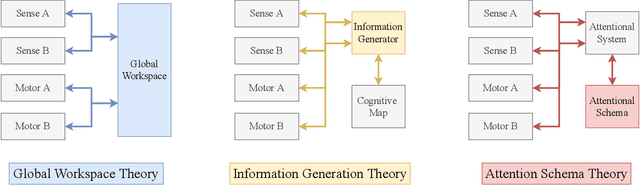
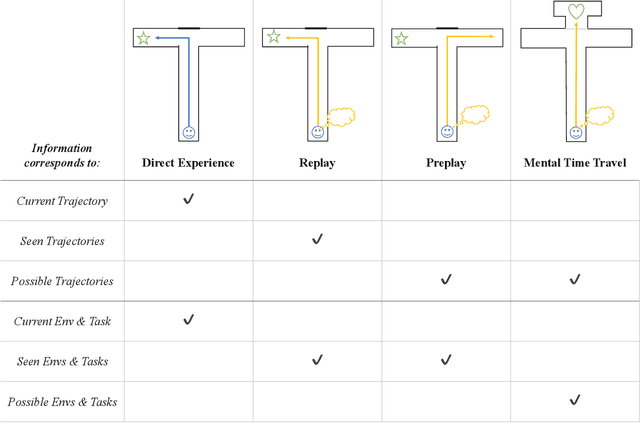
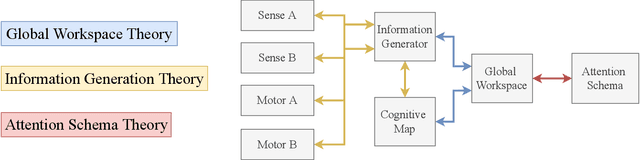
In popular media, there is often a connection drawn between the advent of awareness in artificial agents and those same agents simultaneously achieving human or superhuman level intelligence. In this work, we explore the validity and potential application of this seemingly intuitive link between consciousness and intelligence. We do so by examining the cognitive abilities associated with three contemporary theories of conscious function: Global Workspace Theory (GWT), Information Generation Theory (IGT), and Attention Schema Theory (AST). We find that all three theories specifically relate conscious function to some aspect of domain-general intelligence in humans. With this insight, we turn to the field of Artificial Intelligence (AI) and find that, while still far from demonstrating general intelligence, many state-of-the-art deep learning methods have begun to incorporate key aspects of each of the three functional theories. Given this apparent trend, we use the motivating example of mental time travel in humans to propose ways in which insights from each of the three theories may be combined into a unified model. We believe that doing so can enable the development of artificial agents which are not only more generally intelligent but are also consistent with multiple current theories of conscious function.
All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
Feb 24, 2022
Upside down reinforcement learning (UDRL) flips the conventional use of the return in the objective function in RL upside down, by taking returns as input and predicting actions. UDRL is based purely on supervised learning, and bypasses some prominent issues in RL: bootstrapping, off-policy corrections, and discount factors. While previous work with UDRL demonstrated it in a traditional online RL setting, here we show that this single algorithm can also work in the imitation learning and offline RL settings, be extended to the goal-conditioned RL setting, and even the meta-RL setting. With a general agent architecture, a single UDRL agent can learn across all paradigms.
Learning Relative Return Policies With Upside-Down Reinforcement Learning
Feb 23, 2022
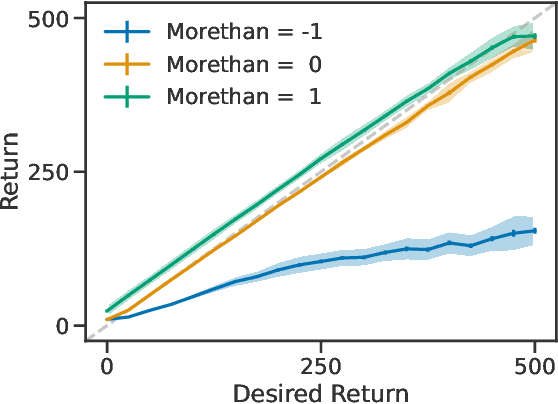
Lately, there has been a resurgence of interest in using supervised learning to solve reinforcement learning problems. Recent work in this area has largely focused on learning command-conditioned policies. We investigate the potential of one such method -- upside-down reinforcement learning -- to work with commands that specify a desired relationship between some scalar value and the observed return. We show that upside-down reinforcement learning can learn to carry out such commands online in a tabular bandit setting and in CartPole with non-linear function approximation. By doing so, we demonstrate the power of this family of methods and open the way for their practical use under more complicated command structures.
Diversity-based Trajectory and Goal Selection with Hindsight Experience Replay
Aug 17, 2021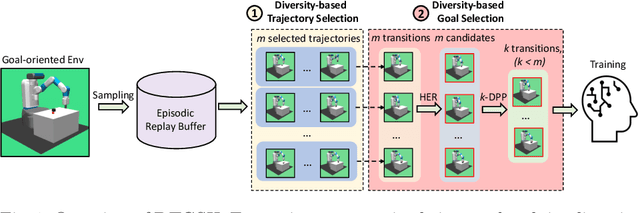
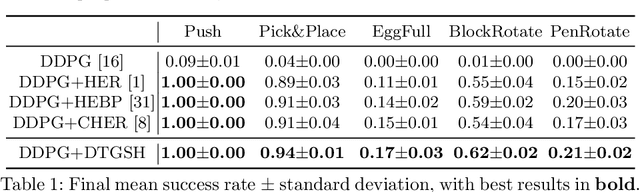
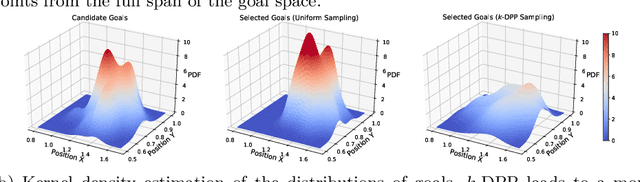

Hindsight experience replay (HER) is a goal relabelling technique typically used with off-policy deep reinforcement learning algorithms to solve goal-oriented tasks; it is well suited to robotic manipulation tasks that deliver only sparse rewards. In HER, both trajectories and transitions are sampled uniformly for training. However, not all of the agent's experiences contribute equally to training, and so naive uniform sampling may lead to inefficient learning. In this paper, we propose diversity-based trajectory and goal selection with HER (DTGSH). Firstly, trajectories are sampled according to the diversity of the goal states as modelled by determinantal point processes (DPPs). Secondly, transitions with diverse goal states are selected from the trajectories by using k-DPPs. We evaluate DTGSH on five challenging robotic manipulation tasks in simulated robot environments, where we show that our method can learn more quickly and reach higher performance than other state-of-the-art approaches on all tasks.
A Pragmatic Look at Deep Imitation Learning
Aug 04, 2021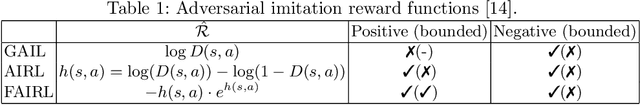
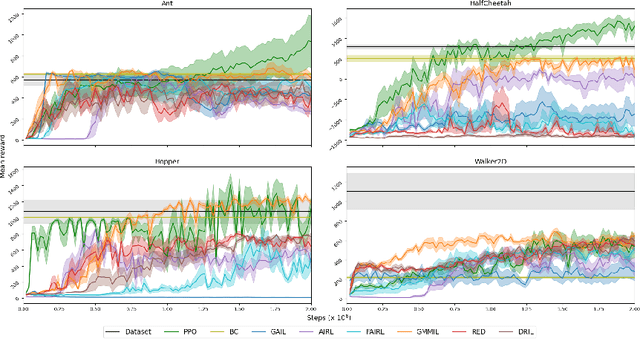
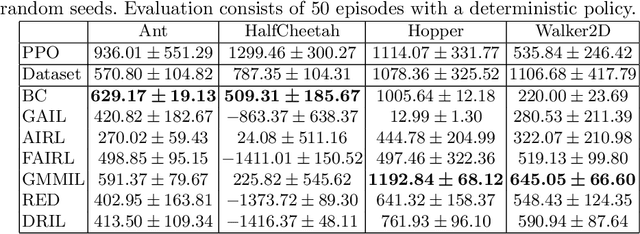
The introduction of the generative adversarial imitation learning (GAIL) algorithm has spurred the development of scalable imitation learning approaches using deep neural networks. The GAIL objective can be thought of as 1) matching the expert policy's state distribution; 2) penalising the learned policy's state distribution; and 3) maximising entropy. While theoretically motivated, in practice GAIL can be difficult to apply, not least due to the instabilities of adversarial training. In this paper, we take a pragmatic look at GAIL and related imitation learning algorithms. We implement and automatically tune a range of algorithms in a unified experimental setup, presenting a fair evaluation between the competing methods. From our results, our primary recommendation is to consider non-adversarial methods. Furthermore, we discuss the common components of imitation learning objectives, and present promising avenues for future research.
Privileged Information Dropout in Reinforcement Learning
May 19, 2020



Using privileged information during training can improve the sample efficiency and performance of machine learning systems. This paradigm has been applied to reinforcement learning (RL), primarily in the form of distillation or auxiliary tasks, and less commonly in the form of augmenting the inputs of agents. In this work, we investigate Privileged Information Dropout (\pid) for achieving the latter which can be applied equally to value-based and policy-based RL algorithms. Within a simple partially-observed environment, we demonstrate that \pid outperforms alternatives for leveraging privileged information, including distillation and auxiliary tasks, and can successfully utilise different types of privileged information. Finally, we analyse its effect on the learned representations.