 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pragmatic Look at Deep Imitation Learning
Paper and Code
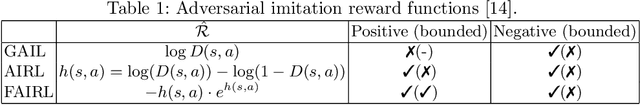
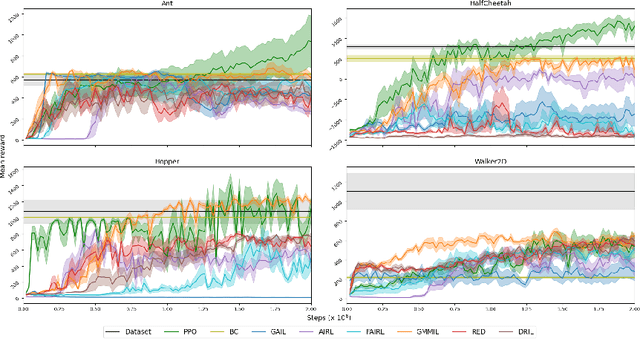
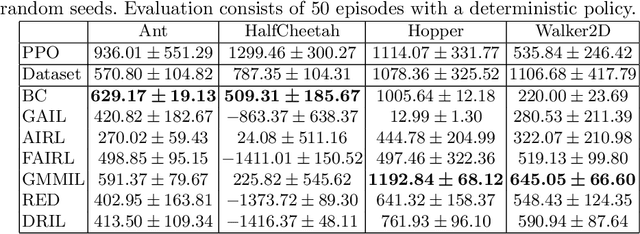
The introduction of the generative adversarial imitation learning (GAIL) algorithm has spurred the development of scalable imitation learning approaches using deep neural networks. The GAIL objective can be thought of as 1) matching the expert policy's state distribution; 2) penalising the learned policy's state distribution; and 3) maximising entropy. While theoretically motivated, in practice GAIL can be difficult to apply, not least due to the instabilities of adversarial training. In this paper, we take a pragmatic look at GAIL and related imitation learning algorithms. We implement and automatically tune a range of algorithms in a unified experimental setup, presenting a fair evaluation between the competing methods. From our results, our primary recommendation is to consider non-adversarial methods. Furthermore, we discuss the common components of imitation learning objectives, and present promising avenues for future research.