 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Planning Capabilities through Intrinsic Self-Critique
Dec 30, 2025We demonstrate an approach for LLMs to critique their \emph{own} answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
Evaluating Gemini in an arena for learning
May 30, 2025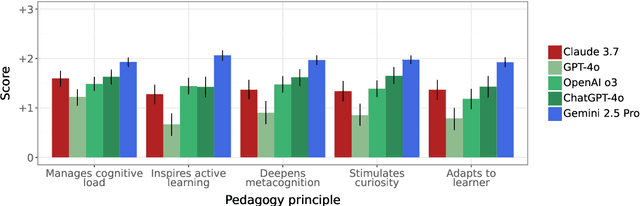

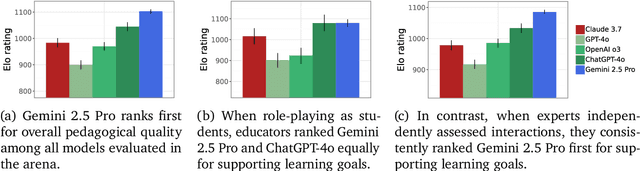
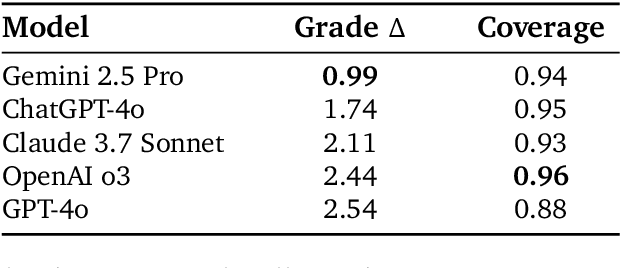
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
Controllable Neural Symbolic Regression
Apr 20, 2023In symbolic regression, the goal is to find an analytical expression that accurately fits experimental data with the minimal use of mathematical symbols such as operators, variables, and constants. However, the combinatorial space of possible expressions can make it challenging for traditional evolutionary algorithms to find the correct expression in a reasonable amount of time. To address this issue, Neural Symbolic Regression (NSR) algorithms have been developed that can quickly identify patterns in the data and generate analytical expressions. However, these methods, in their current form, lack the capability to incorporate user-defined prior knowledge, which is often required in natural sciences and engineering fields. To overcome this limitation, we propose a novel neural symbolic regression method, named Neural Symbolic Regression with Hypothesis (NSRwH) that enables the explicit incorporation of assumptions about the expected structure of the ground-truth expression into the prediction process. Our experiments demonstrate that the proposed conditioned deep learning model outperforms its unconditioned counterparts in terms of accuracy while also providing control over the predicted expression structure.
Deep Generative Symbolic Regression with Monte-Carlo-Tree-Search
Feb 22, 2023Symbolic regression (SR) is the problem of learning a symbolic expression from numerical data. Recently, deep neural models trained on procedurally-generated synthetic datasets showed competitive performance compared to more classical Genetic Programming (GP) algorithms. Unlike their GP counterparts, these neural approaches are trained to generate expressions from datasets given as context. This allows them to produce accurate expressions in a single forward pass at test time. However, they usually do not benefit from search abilities, which result in low performance compared to GP on out-of-distribution datasets. In this paper, we propose a novel method which provides the best of both worlds, based on a Monte-Carlo Tree Search procedure using a context-aware neural mutation model, which is initially pre-trained to learn promising mutations, and further refined from successful experiences in an online fashion. The approach demonstrates state-of-the-art performance on the well-known \texttt{SRBench} benchmark.
End-to-end symbolic regression with transformers
Apr 22, 2022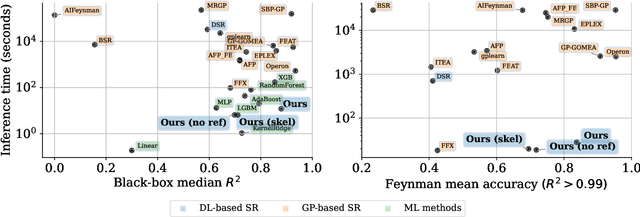

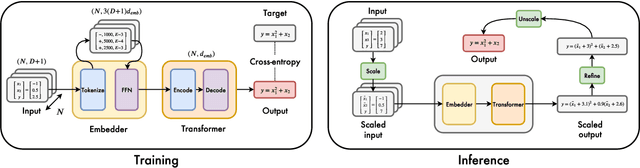
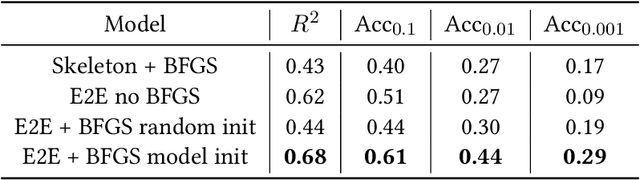
Symbolic regression, the task of predicting the mathematical expression of a function from the observation of its values, is a difficult task which usually involves a two-step procedure: predicting the "skeleton" of the expression up to the choice of numerical constants, then fitting the constants by optimizing a non-convex loss function. The dominant approach is genetic programming, which evolves candidates by iterating this subroutine a large number of times. Neural networks have recently been tasked to predict the correct skeleton in a single try, but remain much less powerful. In this paper, we challenge this two-step procedure, and task a Transformer to directly predict the full mathematical expression, constants included. One can subsequently refine the predicted constants by feeding them to the non-convex optimizer as an informed initialization. We present ablations to show that this end-to-end approach yields better results, sometimes even without the refinement step. We evaluate our model on problems from the SRBench benchmark and show that our model approaches the performance of state-of-the-art genetic programming with several orders of magnitude faster inference.
Deep Symbolic Regression for Recurrent Sequences
Jan 12, 2022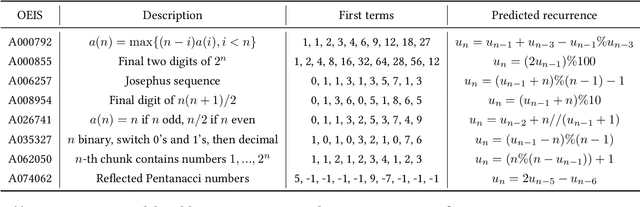
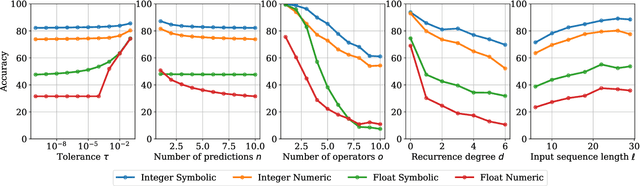
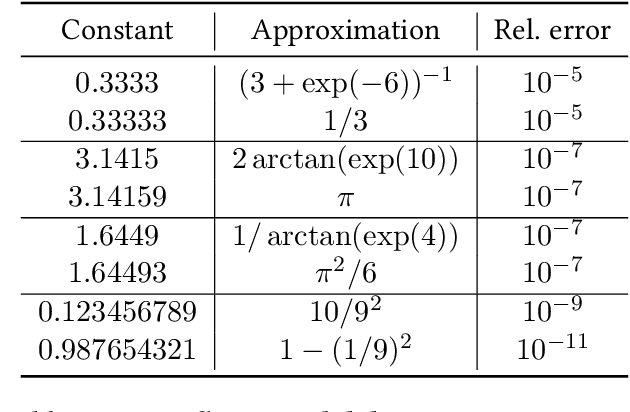
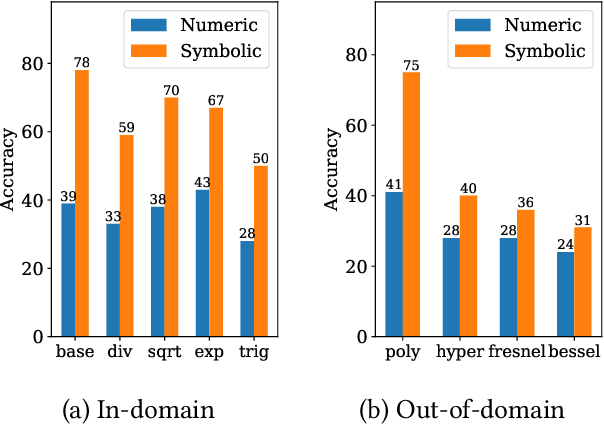
Symbolic regression, i.e. predicting a function from the observation of its values, is well-known to be a challenging task. In this paper, we train Transformers to infer the function or recurrence relation underlying sequences of integers or floats, a typical task in human IQ tests which has hardly been tackled in the machine learning literature. We evaluate our integer model on a subset of OEIS sequences, and show that it outperforms built-in Mathematica functions for recurrence prediction. We also demonstrate that our float model is able to yield informative approximations of out-of-vocabulary functions and constants, e.g. $\operatorname{bessel0}(x)\approx \frac{\sin(x)+\cos(x)}{\sqrt{\pi x}}$ and $1.644934\approx \pi^2/6$. An interactive demonstration of our models is provided at https://bit.ly/3niE5FS.
Direct then Diffuse: Incremental Unsupervised Skill Discovery for State Covering and Goal Reaching
Oct 27, 2021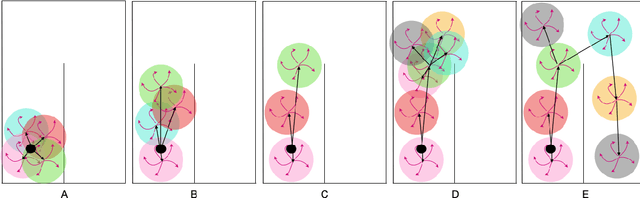
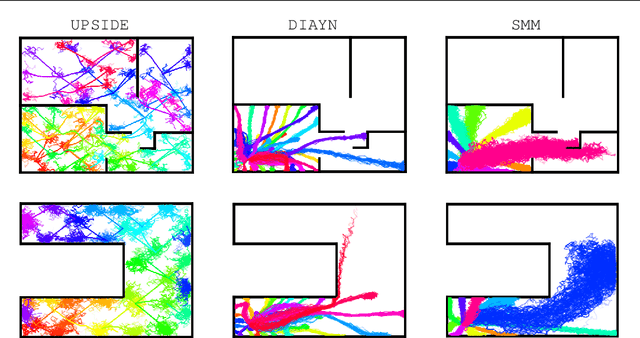
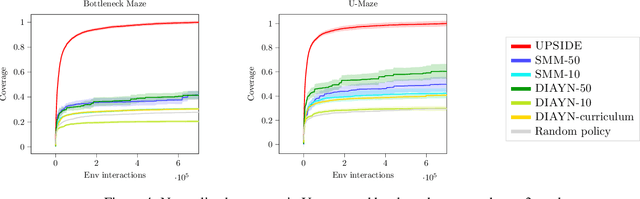

Learning meaningful behaviors in the absence of reward is a difficult problem in reinforcement learning. A desirable and challenging unsupervised objective is to learn a set of diverse skills that provide a thorough coverage of the state space while being directed, i.e., reliably reaching distinct regions of the environment. In this paper, we build on the mutual information framework for skill discovery and introduce UPSIDE, which addresses the coverage-directedness trade-off in the following ways: 1) We design policies with a decoupled structure of a directed skill, trained to reach a specific region, followed by a diffusing part that induces a local coverage. 2) We optimize policies by maximizing their number under the constraint that each of them reaches distinct regions of the environment (i.e., they are sufficiently discriminable) and prove that this serves as a lower bound to the original mutual information objective. 3) Finally, we compose the learned directed skills into a growing tree that adaptively covers the environment. We illustrate in several navigation and control environments how the skills learned by UPSIDE solve sparse-reward downstream tasks better than existing baselines.
SaLinA: Sequential Learning of Agents
Oct 15, 2021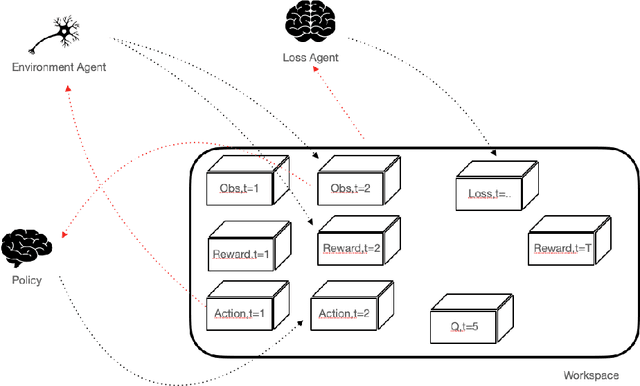


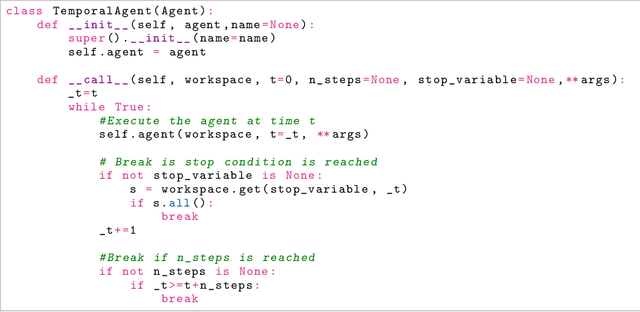
SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.
Privileged Information Dropout in Reinforcement Learning
May 19, 2020



Using privileged information during training can improve the sample efficiency and performance of machine learning systems. This paradigm has been applied to reinforcement learning (RL), primarily in the form of distillation or auxiliary tasks, and less commonly in the form of augmenting the inputs of agents. In this work, we investigate Privileged Information Dropout (\pid) for achieving the latter which can be applied equally to value-based and policy-based RL algorithms. Within a simple partially-observed environment, we demonstrate that \pid outperforms alternatives for leveraging privileged information, including distillation and auxiliary tasks, and can successfully utilise different types of privileged information. Finally, we analyse its effect on the learned representations.
Learning Adaptive Exploration Strategies in Dynamic Environments Through Informed Policy Regularization
May 06, 2020



We study the problem of learning exploration-exploitation strategies that effectively adapt to dynamic environments, where the task may change over time. While RNN-based policies could in principle represent such strategies, in practice their training time is prohibitive and the learning process often converges to poor solutions. In this paper, we consider the case where the agent has access to a description of the task (e.g., a task id or task parameters) at training time, but not at test time. We propose a novel algorithm that regularizes the training of an RNN-based policy using informed policies trained to maximize the reward in each task. This dramatically reduces the sample complexity of training RNN-based policies, without losing their representational power. As a result, our method learns exploration strategies that efficiently balance between gathering information about the unknown and changing task and maximizing the reward over time. We test the performance of our algorithm in a variety of environments where tasks may vary within each episode.