 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning of High-Quality Behaviors Under Robust Style Alignment
Jan 30, 2026We study offline reinforcement learning of style-conditioned policies using explicit style supervision via subtrajectory labeling functions. In this setting, aligning style with high task performance is particularly challenging due to distribution shift and inherent conflicts between style and reward. Existing methods, despite introducing numerous definitions of style, often fail to reconcile these objectives effectively. To address these challenges, we propose a unified definition of behavior style and instantiate it into a practical framework. Building on this, we introduce Style-Conditioned Implicit Q-Learning (SCIQL), which leverages offline goal-conditioned RL techniques, such as hindsight relabeling and value learning, and combine it with a new Gated Advantage Weighted Regression mechanism to efficiently optimize task performance while preserving style alignment. Experiments demonstrate that SCIQL achieves superior performance on both objectives compared to prior offline methods. Code, datasets and visuals are available in: https://sciql-iclr-2026.github.io/.
Reward-Preserving Attacks For Robust Reinforcement Learning
Jan 12, 2026Adversarial robustness in RL is difficult because perturbations affect entire trajectories: strong attacks can break learning, while weak attacks yield little robustness, and the appropriate strength varies by state. We propose $α$-reward-preserving attacks, which adapt the strength of the adversary so that an $α$ fraction of the nominal-to-worst-case return gap remains achievable at each state. In deep RL, we use a gradient-based attack direction and learn a state-dependent magnitude $η\le η_{\mathcal B}$ selected via a critic $Q^π_α((s,a),η)$ trained off-policy over diverse radii. This adaptive tuning calibrates attack strength and, with intermediate $α$, improves robustness across radii while preserving nominal performance, outperforming fixed- and random-radius baselines.
Black-Box Combinatorial Optimization with Order-Invariant Reinforcement Learning
Oct 02, 2025We introduce an order-invariant reinforcement learning framework for black-box combinatorial optimization. Classical estimation-of-distribution algorithms (EDAs) often rely on learning explicit variable dependency graphs, which can be costly and fail to capture complex interactions efficiently. In contrast, we parameterize a multivariate autoregressive generative model trained without a fixed variable ordering. By sampling random generation orders during training - a form of information-preserving dropout - the model is encouraged to be invariant to variable order, promoting search-space diversity and shaping the model to focus on the most relevant variable dependencies, improving sample efficiency. We adapt Generalized Reinforcement Policy Optimization (GRPO) to this setting, providing stable policy-gradient updates from scale-invariant advantages. Across a wide range of benchmark algorithms and problem instances of varying sizes, our method frequently achieves the best performance and consistently avoids catastrophic failures.
HERAKLES: Hierarchical Skill Compilation for Open-ended LLM Agents
Aug 20, 2025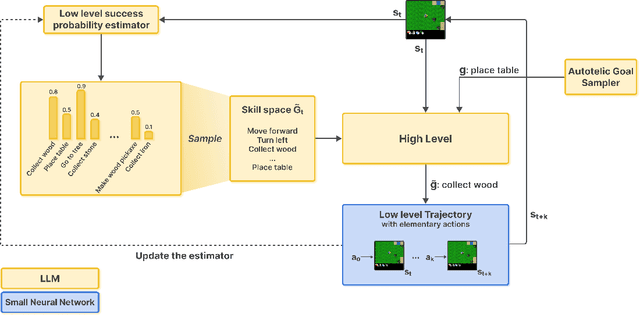
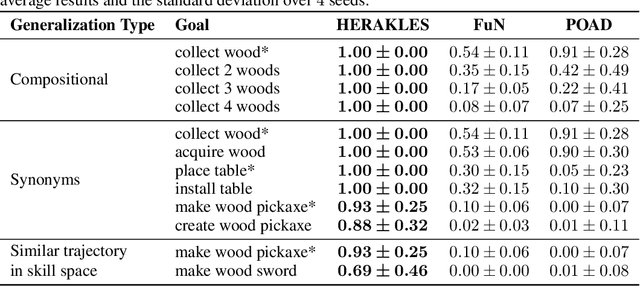
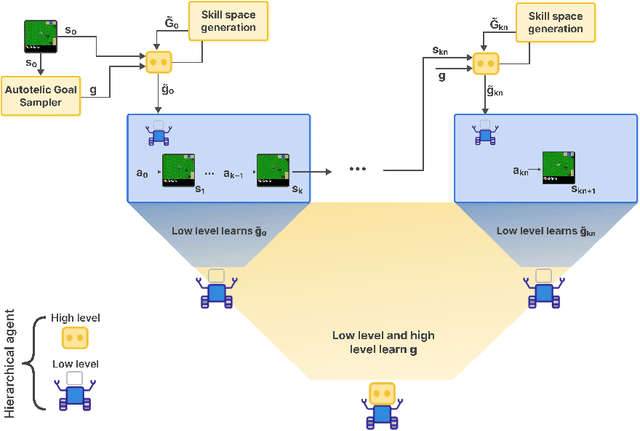

Open-ended AI agents need to be able to learn efficiently goals of increasing complexity, abstraction and heterogeneity over their lifetime. Beyond sampling efficiently their own goals, autotelic agents specifically need to be able to keep the growing complexity of goals under control, limiting the associated growth in sample and computational complexity. To adress this challenge, recent approaches have leveraged hierarchical reinforcement learning (HRL) and language, capitalizing on its compositional and combinatorial generalization capabilities to acquire temporally extended reusable behaviours. Existing approaches use expert defined spaces of subgoals over which they instantiate a hierarchy, and often assume pre-trained associated low-level policies. Such designs are inadequate in open-ended scenarios, where goal spaces naturally diversify across a broad spectrum of difficulties. We introduce HERAKLES, a framework that enables a two-level hierarchical autotelic agent to continuously compile mastered goals into the low-level policy, executed by a small, fast neural network, dynamically expanding the set of subgoals available to the high-level policy. We train a Large Language Model (LLM) to serve as the high-level controller, exploiting its strengths in goal decomposition and generalization to operate effectively over this evolving subgoal space. We evaluate HERAKLES in the open-ended Crafter environment and show that it scales effectively with goal complexity, improves sample efficiency through skill compilation, and enables the agent to adapt robustly to novel challenges over time.
Imagine Beyond! Distributionally Robust Auto-Encoding for State Space Coverage in Online Reinforcement Learning
May 23, 2025Goal-Conditioned Reinforcement Learning (GCRL) enables agents to autonomously acquire diverse behaviors, but faces major challenges in visual environments due to high-dimensional, semantically sparse observations. In the online setting, where agents learn representations while exploring, the latent space evolves with the agent's policy, to capture newly discovered areas of the environment. However, without incentivization to maximize state coverage in the representation, classical approaches based on auto-encoders may converge to latent spaces that over-represent a restricted set of states frequently visited by the agent. This is exacerbated in an intrinsic motivation setting, where the agent uses the distribution encoded in the latent space to sample the goals it learns to master. To address this issue, we propose to progressively enforce distributional shifts towards a uniform distribution over the full state space, to ensure a full coverage of skills that can be learned in the environment. We introduce DRAG (Distributionally Robust Auto-Encoding for GCRL), a method that combines the $\beta$-VAE framework with Distributionally Robust Optimization. DRAG leverages an adversarial neural weighter of training states of the VAE, to account for the mismatch between the current data distribution and unseen parts of the environment. This allows the agent to construct semantically meaningful latent spaces beyond its immediate experience. Our approach improves state space coverage and downstream control performance on hard exploration environments such as mazes and robotic control involving walls to bypass, without pre-training nor prior environment knowledge.
Offline Learning of Controllable Diverse Behaviors
Apr 25, 2025Imitation Learning (IL) techniques aim to replicate human behaviors in specific tasks. While IL has gained prominence due to its effectiveness and efficiency, traditional methods often focus on datasets collected from experts to produce a single efficient policy. Recently, extensions have been proposed to handle datasets of diverse behaviors by mainly focusing on learning transition-level diverse policies or on performing entropy maximization at the trajectory level. While these methods may lead to diverse behaviors, they may not be sufficient to reproduce the actual diversity of demonstrations or to allow controlled trajectory generation. To overcome these drawbacks, we propose a different method based on two key features: a) Temporal Consistency that ensures consistent behaviors across entire episodes and not just at the transition level as well as b) Controllability obtained by constructing a latent space of behaviors that allows users to selectively activate specific behaviors based on their requirements. We compare our approach to state-of-the-art methods over a diverse set of tasks and environments. Project page: https://mathieu-petitbois.github.io/projects/swr/
Structural Deep Encoding for Table Question Answering
Mar 03, 2025Although Transformers-based architectures excel at processing textual information, their naive adaptation for tabular data often involves flattening the table structure. This simplification can lead to the loss of essential inter-dependencies between rows, columns, and cells, while also posing scalability challenges for large tables. To address these issues, prior works have explored special tokens, structured embeddings, and sparse attention patterns. In this paper, we conduct a comprehensive analysis of tabular encoding techniques, which highlights the crucial role of attention sparsity in preserving structural information of tables. We also introduce a set of novel sparse attention mask designs for tabular data, that not only enhance computational efficiency but also preserve structural integrity, leading to better overall performance.
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
Feb 12, 2025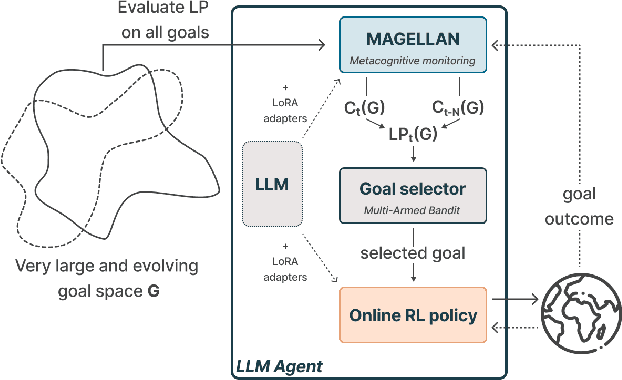
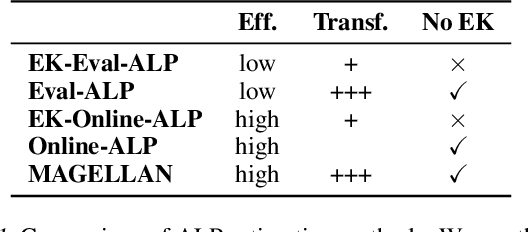
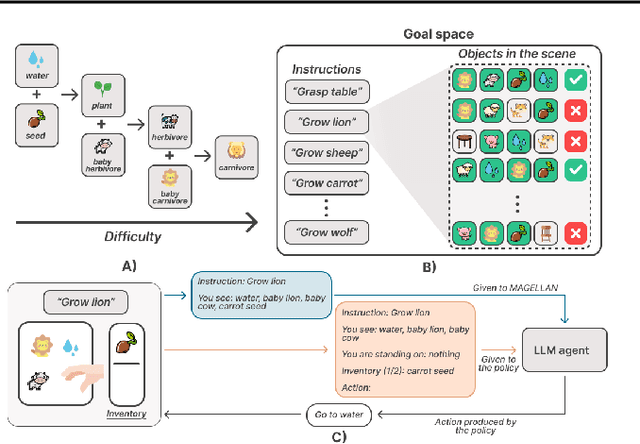
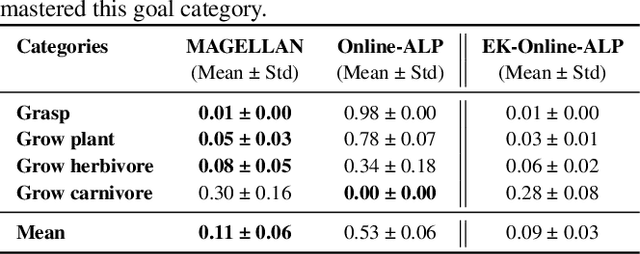
Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM agents trained with online RL in high-dimensional and evolving goal spaces, a key challenge for LP prediction is modeling one's own competence, a form of metacognitive monitoring. Traditional approaches either require extensive sampling or rely on brittle expert-defined goal groupings. We introduce MAGELLAN, a metacognitive framework that lets LLM agents learn to predict their competence and LP online. By capturing semantic relationships between goals, MAGELLAN enables sample-efficient LP estimation and dynamic adaptation to evolving goal spaces through generalization. In an interactive learning environment, we show that MAGELLAN improves LP prediction efficiency and goal prioritization, being the only method allowing the agent to fully master a large and evolving goal space. These results demonstrate how augmenting LLM agents with a metacognitive ability for LP predictions can effectively scale curriculum learning to open-ended goal spaces.
Navigation with QPHIL: Quantizing Planner for Hierarchical Implicit Q-Learning
Nov 12, 2024



Offline Reinforcement Learning (RL) has emerged as a powerful alternative to imitation learning for behavior modeling in various domains, particularly in complex navigation tasks. An existing challenge with Offline RL is the signal-to-noise ratio, i.e. how to mitigate incorrect policy updates due to errors in value estimates. Towards this, multiple works have demonstrated the advantage of hierarchical offline RL methods, which decouples high-level path planning from low-level path following. In this work, we present a novel hierarchical transformer-based approach leveraging a learned quantizer of the space. This quantization enables the training of a simpler zone-conditioned low-level policy and simplifies planning, which is reduced to discrete autoregressive prediction. Among other benefits, zone-level reasoning in planning enables explicit trajectory stitching rather than implicit stitching based on noisy value function estimates. By combining this transformer-based planner with recent advancements in offline RL, our proposed approach achieves state-of-the-art results in complex long-distance navigation environments.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024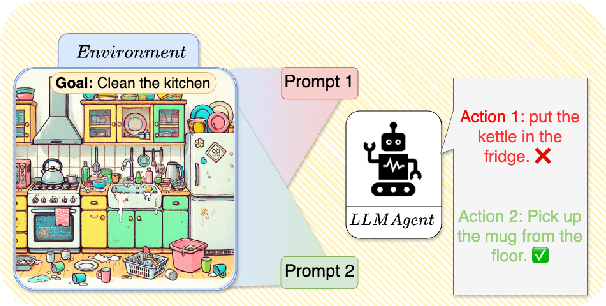
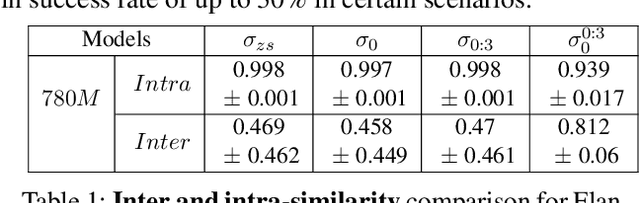
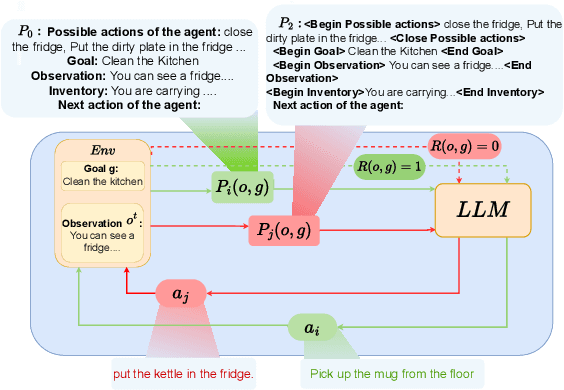
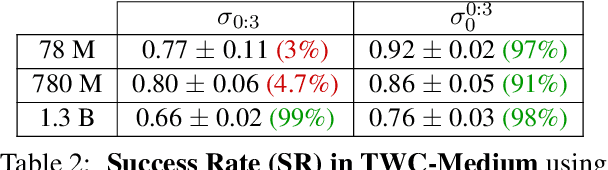
Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.