 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Preserving Attacks For Robust Reinforcement Learning
Jan 12, 2026Adversarial robustness in RL is difficult because perturbations affect entire trajectories: strong attacks can break learning, while weak attacks yield little robustness, and the appropriate strength varies by state. We propose $α$-reward-preserving attacks, which adapt the strength of the adversary so that an $α$ fraction of the nominal-to-worst-case return gap remains achievable at each state. In deep RL, we use a gradient-based attack direction and learn a state-dependent magnitude $η\le η_{\mathcal B}$ selected via a critic $Q^π_α((s,a),η)$ trained off-policy over diverse radii. This adaptive tuning calibrates attack strength and, with intermediate $α$, improves robustness across radii while preserving nominal performance, outperforming fixed- and random-radius baselines.
Robust Deep Reinforcement Learning Through Adversarial Attacks and Training : A Survey
Mar 01, 2024Deep Reinforcement Learning (DRL) is an approach for training autonomous agents across various complex environments. Despite its significant performance in well known environments, it remains susceptible to minor conditions variations, raising concerns about its reliability in real-world applications. To improve usability, DRL must demonstrate trustworthiness and robustness. A way to improve robustness of DRL to unknown changes in the conditions is through Adversarial Training, by training the agent against well suited adversarial attacks on the dynamics of the environment. Addressing this critical issue, our work presents an in-depth analysis of contemporary adversarial attack methodologies, systematically categorizing them and comparing their objectives and operational mechanisms. This classification offers a detailed insight into how adversarial attacks effectively act for evaluating the resilience of DRL agents, thereby paving the way for enhancing their robustness.
Improving Robustness of Deep Reinforcement Learning Agents: Environment Attacks based on Critic Networks
Apr 07, 2021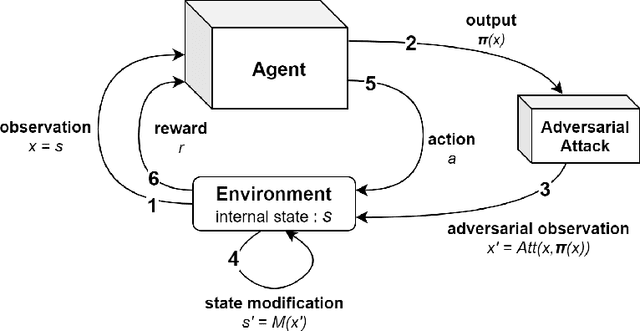
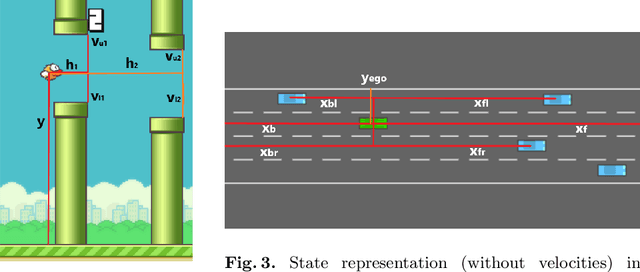
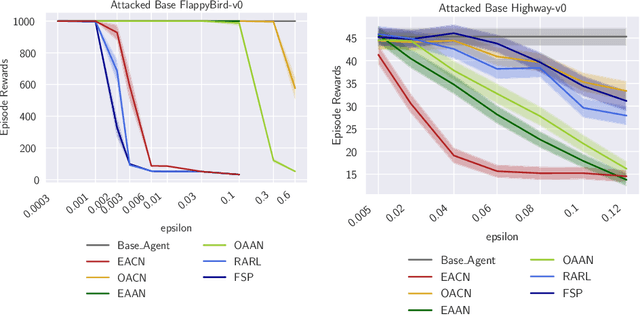
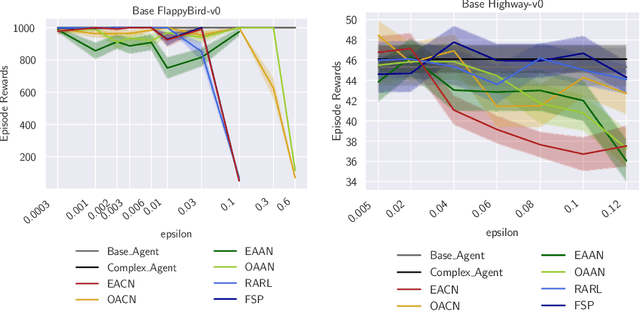
To improve policy robustness of deep reinforcement learning agents, a line of recent works focus on producing disturbances of the environment. Existing approaches of the literature to generate meaningful disturbances of the environment are adversarial reinforcement learning methods. These methods set the problem as a two-player game between the protagonist agent, which learns to perform a task in an environment, and the adversary agent, which learns to disturb the protagonist via modifications of the considered environment. Both protagonist and adversary are trained with deep reinforcement learning algorithms. Alternatively, we propose in this paper to build on gradient-based adversarial attacks, usually used for classification tasks for instance, that we apply on the critic network of the protagonist to identify efficient disturbances of the environment. Rather than learning an attacker policy, which usually reveals as very complex and unstable, we leverage the knowledge of the critic network of the protagonist, to dynamically complexify the task at each step of the learning process. We show that our method, while being faster and lighter, leads to significantly better improvements in policy robustness than existing methods of the literature.