 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldLLM: Improving LLMs' world modeling using curiosity-driven theory-making
Jun 07, 2025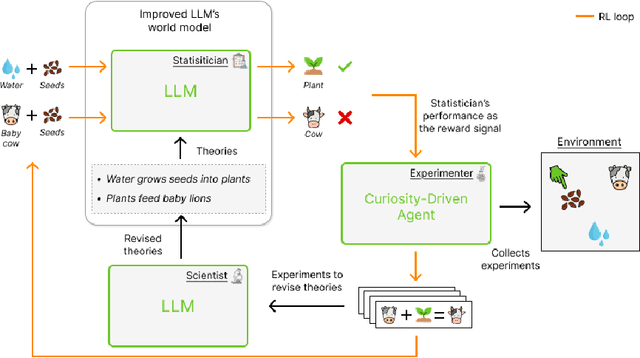
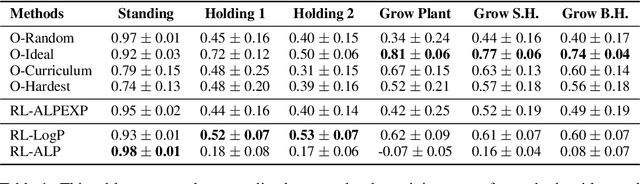
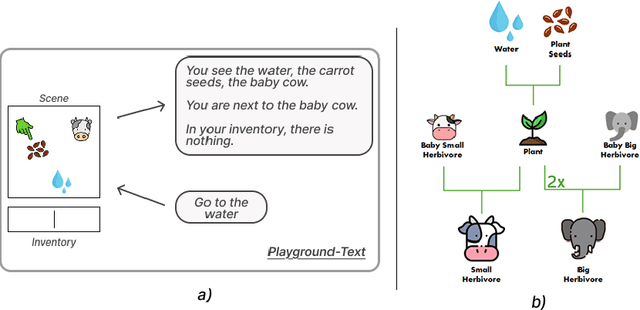
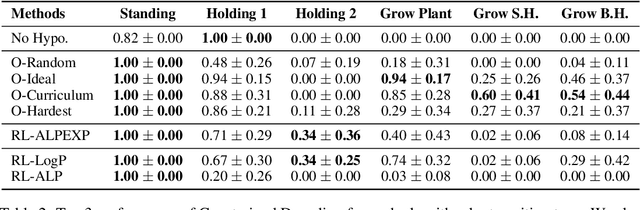
Large Language Models (LLMs) possess general world knowledge but often struggle to generate precise predictions in structured, domain-specific contexts such as simulations. These limitations arise from their inability to ground their broad, unstructured understanding in specific environments. To address this, we present WorldLLM, a framework that enhances LLM-based world modeling by combining Bayesian inference and autonomous active exploration with reinforcement learning. WorldLLM leverages the in-context learning abilities of LLMs to guide an LLM-based world model's predictions using natural language hypotheses given in its prompt. These hypotheses are iteratively refined through a Bayesian inference framework that leverages a second LLM as the proposal distribution given collected evidence. This evidence is collected using a curiosity-driven reinforcement learning policy that explores the environment to find transitions with a low log-likelihood under our LLM-based predictive model using the current hypotheses. By alternating between refining hypotheses and collecting new evidence, our framework autonomously drives continual improvement of the predictions. Our experiments demonstrate the effectiveness of WorldLLM in a textual game environment that requires agents to manipulate and combine objects. The framework not only enhances predictive accuracy, but also generates human-interpretable theories of environment dynamics.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024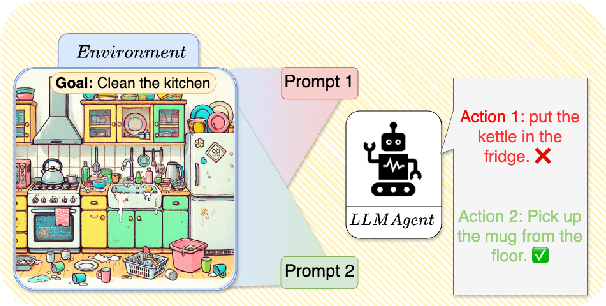
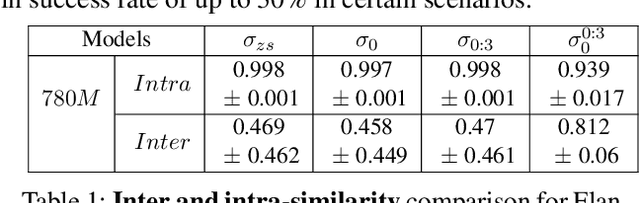
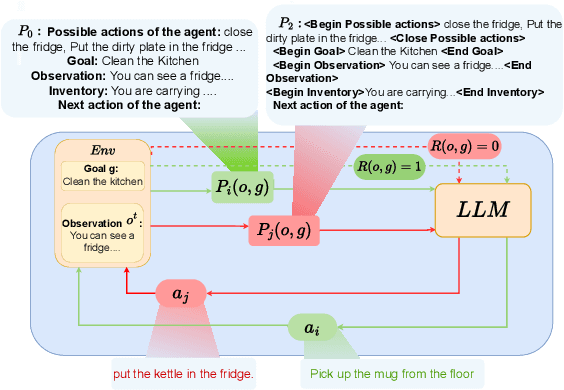
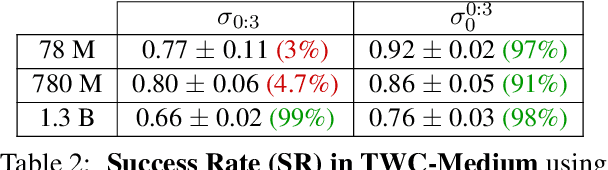
Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.
SAC-GLAM: Improving Online RL for LLM agents with Soft Actor-Critic and Hindsight Relabeling
Oct 16, 2024



The past years have seen Large Language Models (LLMs) strive not only as generative models but also as agents solving textual sequential decision-making tasks. When facing complex environments where their zero-shot abilities are insufficient, recent work showed online Reinforcement Learning (RL) could be used for the LLM agent to discover and learn efficient strategies interactively. However, most prior work sticks to on-policy algorithms, which greatly reduces the scope of methods such agents could use for both exploration and exploitation, such as experience replay and hindsight relabeling. Yet, such methods may be key for LLM learning agents, and in particular when designing autonomous intrinsically motivated agents sampling and pursuing their own goals (i.e. autotelic agents). This paper presents and studies an adaptation of Soft Actor-Critic and hindsight relabeling to LLM agents. Our method not only paves the path towards autotelic LLM agents that learn online but can also outperform on-policy methods in more classic multi-goal RL environments.