 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODIP: Efficient Model-Based Optimization for Diffusion Policies
Jun 09, 2026Diffusion policies (DPs) have emerged as expressive policy representations for robot learning, often used with imitation learning methods such as behavioral cloning (BC). However, while their success has largely been confined to BC, direct reinforcement learning (RL) fine-tuning remains challenging because actions are generated through a multi-step denoising process. In this work, we propose MODIP, a framework for the offline-to-online fine-tuning of DPs. Rather than directly applying RL to the DPs, MODIP leverages a world model (WM) to guide policy adaptation and keeps the simplicity and stability of BC. We utilize model predictive control (MPC) to generate high-quality trajectories within the WM, and use them as supervised targets for fine-tuning the DP. To make MPC planning efficient, MODIP uses a terminal state value instead of a policy-dependent state-action value, reducing inference time. Additionally, MODIP trains critics with policy-independent TD targets, reducing training time. Experiments on D4RL (MuJoCo, Kitchen) and RoboMimic tasks show that MODIP improves diffusion policies beyond BC, and is competitive with or outperforms diffusion policy RL fine-tuning methods and strong model-based baselines such as TD-MPC2.
Improving Zero-Shot Offline RL via Behavioral Task Sampling
Apr 28, 2026Offline zero-shot reinforcement learning (RL) aims to learn agents that optimize unseen reward functions without additional environment interaction. The standard approach to this problem trains task-conditioned policies by sampling task vectors that define linear reward functions over learned state representations. In most existing algorithms, these task vectors are randomly sampled, implicitly assuming this adequately captures the structure of the task space. We argue that doing so leads to suboptimal zero-shot generalization. To address this limitation, we propose extracting task vectors directly from the offline dataset and using them to define the task distribution used for policy training. We introduce a simple and general reward function extraction procedure that integrates into existing offline zero-shot RL algorithms. Across multiple benchmark environments and baselines, our approach improves zero-shot performance by an average of 20%, highlighting the importance of principled task sampling in offline zero-shot RL.
IntentVLM: Open-Vocabulary Intention Recognition through Forward-Inverse Modeling with Video-Language Models
Apr 27, 2026Improving the effectiveness of human-robot interaction requires social robots to accurately infer human goals through robust intention understanding. This challenge is particularly critical in multimodal settings, where agents must integrate heterogeneous signals including text, visual cues to form a coherent interpretation of user intent. This paper presents IntentVLM, a novel two-stage video-language framework designed for open-vocabulary human intention recognition. The approach is inspired by forward-inverse modeling in cognitive science by decomposing intention understanding into goal candidate generation followed by structured inference through selection, effectively reducing hallucinations in latent reasoning. Evaluated on the IntentQA and Inst-IT Bench datasets, IntentVLM achieves state-of-the-art results with up to 80% accuracy, notably surpassing the baseline performance by 30% and matches human performance. Our findings demonstrate that this structured reasoning approach enhances open-vocabulary intention understanding without catastrophic forgetting, offering a robust foundation for human-centered robotics.
Iterative On-Policy Refinement of Hierarchical Diffusion Policies for Language-Conditioned Manipulation
Mar 05, 2026Hierarchical policies for language-conditioned manipulation decompose tasks into subgoals, where a high-level planner guides a low-level controller. However, these hierarchical agents often fail because the planner generates subgoals without considering the actual limitations of the controller. Existing solutions attempt to bridge this gap via intermediate modules or shared representations, but they remain limited by their reliance on fixed offline datasets. We propose HD-ExpIt, a framework for iterative fine-tuning of hierarchical diffusion policies via environment feedback. HD-ExpIt organizes training into a self-reinforcing cycle: it utilizes diffusion-based planning to autonomously discover successful behaviors, which are then distilled back into the hierarchical policy. This loop enables both components to improve while implicitly grounding the planner in the controller's actual capabilities without requiring explicit proxy models. Empirically, HD-ExpIt significantly improves hierarchical policies trained solely on offline data, achieving state-of-the-art performance on the long-horizon CALVIN benchmark among methods trained from scratch.
Controlling Intent Expressiveness in Robot Motion with Diffusion Models
Oct 14, 2025



Legibility of robot motion is critical in human-robot interaction, as it allows humans to quickly infer a robot's intended goal. Although traditional trajectory generation methods typically prioritize efficiency, they often fail to make the robot's intentions clear to humans. Meanwhile, existing approaches to legible motion usually produce only a single "most legible" trajectory, overlooking the need to modulate intent expressiveness in different contexts. In this work, we propose a novel motion generation framework that enables controllable legibility across the full spectrum, from highly legible to highly ambiguous motions. We introduce a modeling approach based on an Information Potential Field to assign continuous legibility scores to trajectories, and build upon it with a two-stage diffusion framework that first generates paths at specified legibility levels and then translates them into executable robot actions. Experiments in both 2D and 3D reaching tasks demonstrate that our approach produces diverse and controllable motions with varying degrees of legibility, while achieving performance comparable to SOTA. Code and project page: https://legibility-modulator.github.io.
I-FailSense: Towards General Robotic Failure Detection with Vision-Language Models
Sep 19, 2025Language-conditioned robotic manipulation in open-world settings requires not only accurate task execution but also the ability to detect failures for robust deployment in real-world environments. Although recent advances in vision-language models (VLMs) have significantly improved the spatial reasoning and task-planning capabilities of robots, they remain limited in their ability to recognize their own failures. In particular, a critical yet underexplored challenge lies in detecting semantic misalignment errors, where the robot executes a task that is semantically meaningful but inconsistent with the given instruction. To address this, we propose a method for building datasets targeting Semantic Misalignment Failures detection, from existing language-conditioned manipulation datasets. We also present I-FailSense, an open-source VLM framework with grounded arbitration designed specifically for failure detection. Our approach relies on post-training a base VLM, followed by training lightweight classification heads, called FS blocks, attached to different internal layers of the VLM and whose predictions are aggregated using an ensembling mechanism. Experiments show that I-FailSense outperforms state-of-the-art VLMs, both comparable in size and larger, in detecting semantic misalignment errors. Notably, despite being trained only on semantic misalignment detection, I-FailSense generalizes to broader robotic failure categories and effectively transfers to other simulation environments and real-world with zero-shot or minimal post-training. The datasets and models are publicly released on HuggingFace (Webpage: https://clemgris.github.io/I-FailSense/).
HERAKLES: Hierarchical Skill Compilation for Open-ended LLM Agents
Aug 20, 2025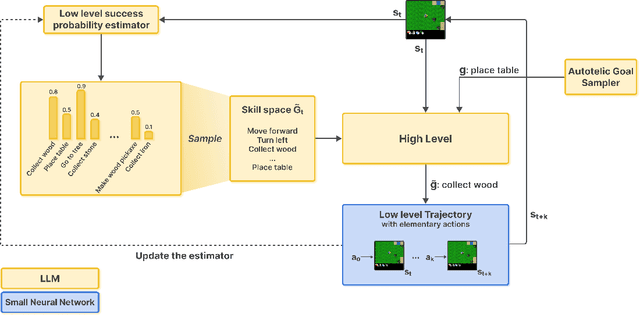
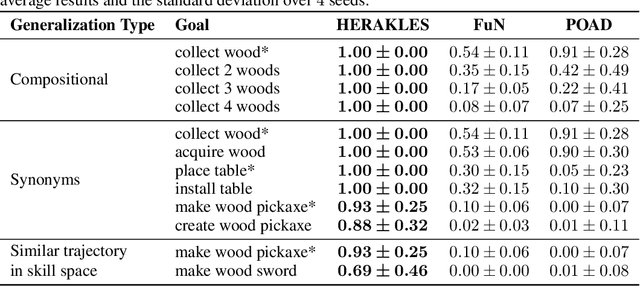
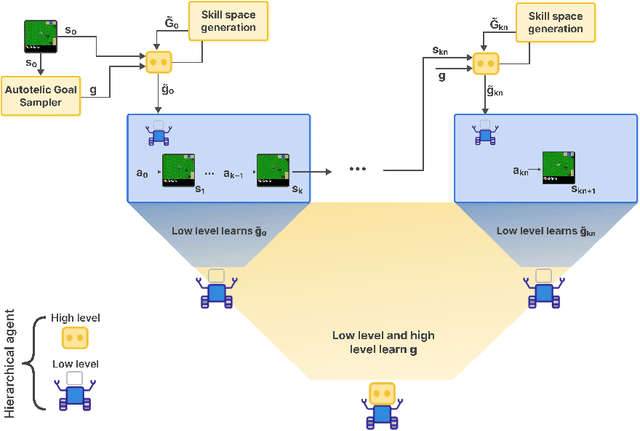

Open-ended AI agents need to be able to learn efficiently goals of increasing complexity, abstraction and heterogeneity over their lifetime. Beyond sampling efficiently their own goals, autotelic agents specifically need to be able to keep the growing complexity of goals under control, limiting the associated growth in sample and computational complexity. To adress this challenge, recent approaches have leveraged hierarchical reinforcement learning (HRL) and language, capitalizing on its compositional and combinatorial generalization capabilities to acquire temporally extended reusable behaviours. Existing approaches use expert defined spaces of subgoals over which they instantiate a hierarchy, and often assume pre-trained associated low-level policies. Such designs are inadequate in open-ended scenarios, where goal spaces naturally diversify across a broad spectrum of difficulties. We introduce HERAKLES, a framework that enables a two-level hierarchical autotelic agent to continuously compile mastered goals into the low-level policy, executed by a small, fast neural network, dynamically expanding the set of subgoals available to the high-level policy. We train a Large Language Model (LLM) to serve as the high-level controller, exploiting its strengths in goal decomposition and generalization to operate effectively over this evolving subgoal space. We evaluate HERAKLES in the open-ended Crafter environment and show that it scales effectively with goal complexity, improves sample efficiency through skill compilation, and enables the agent to adapt robustly to novel challenges over time.
Imagine Beyond! Distributionally Robust Auto-Encoding for State Space Coverage in Online Reinforcement Learning
May 23, 2025Goal-Conditioned Reinforcement Learning (GCRL) enables agents to autonomously acquire diverse behaviors, but faces major challenges in visual environments due to high-dimensional, semantically sparse observations. In the online setting, where agents learn representations while exploring, the latent space evolves with the agent's policy, to capture newly discovered areas of the environment. However, without incentivization to maximize state coverage in the representation, classical approaches based on auto-encoders may converge to latent spaces that over-represent a restricted set of states frequently visited by the agent. This is exacerbated in an intrinsic motivation setting, where the agent uses the distribution encoded in the latent space to sample the goals it learns to master. To address this issue, we propose to progressively enforce distributional shifts towards a uniform distribution over the full state space, to ensure a full coverage of skills that can be learned in the environment. We introduce DRAG (Distributionally Robust Auto-Encoding for GCRL), a method that combines the $\beta$-VAE framework with Distributionally Robust Optimization. DRAG leverages an adversarial neural weighter of training states of the VAE, to account for the mismatch between the current data distribution and unseen parts of the environment. This allows the agent to construct semantically meaningful latent spaces beyond its immediate experience. Our approach improves state space coverage and downstream control performance on hard exploration environments such as mazes and robotic control involving walls to bypass, without pre-training nor prior environment knowledge.
A tale of two goals: leveraging sequentiality in multi-goal scenarios
Mar 27, 2025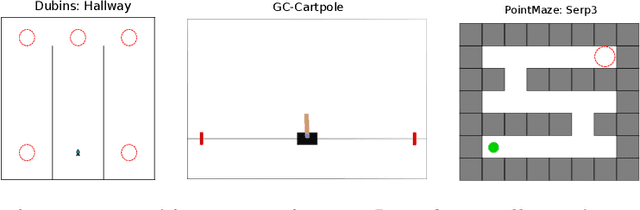



Several hierarchical reinforcement learning methods leverage planning to create a graph or sequences of intermediate goals, guiding a lower-level goal-conditioned (GC) policy to reach some final goals. The low-level policy is typically conditioned on the current goal, with the aim of reaching it as quickly as possible. However, this approach can fail when an intermediate goal can be reached in multiple ways, some of which may make it impossible to continue toward subsequent goals. To address this issue, we introduce two instances of Markov Decision Process (MDP) where the optimization objective favors policies that not only reach the current goal but also subsequent ones. In the first, the agent is conditioned on both the current and final goals, while in the second, it is conditioned on the next two goals in the sequence. We conduct a series of experiments on navigation and pole-balancing tasks in which sequences of intermediate goals are given. By evaluating policies trained with TD3+HER on both the standard GC-MDP and our proposed MDPs, we show that, in most cases, conditioning on the next two goals improves stability and sample efficiency over other approaches.
VIPER: Visual Perception and Explainable Reasoning for Sequential Decision-Making
Mar 19, 2025While Large Language Models (LLMs) excel at reasoning on text and Vision-Language Models (VLMs) are highly effective for visual perception, applying those models for visual instruction-based planning remains a widely open problem. In this paper, we introduce VIPER, a novel framework for multimodal instruction-based planning that integrates VLM-based perception with LLM-based reasoning. Our approach uses a modular pipeline where a frozen VLM generates textual descriptions of image observations, which are then processed by an LLM policy to predict actions based on the task goal. We fine-tune the reasoning module using behavioral cloning and reinforcement learning, improving our agent's decision-making capabilities. Experiments on the ALFWorld benchmark show that VIPER significantly outperforms state-of-the-art visual instruction-based planners while narrowing the gap with purely text-based oracles. By leveraging text as an intermediate representation, VIPER also enhances explainability, paving the way for a fine-grained analysis of perception and reasoning components.