 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Environments and Language with Rendering Functions and Vision-Language Models
Sep 24, 2024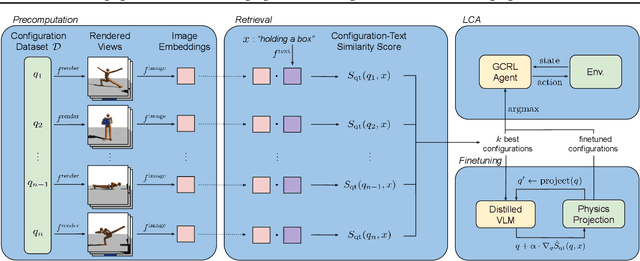
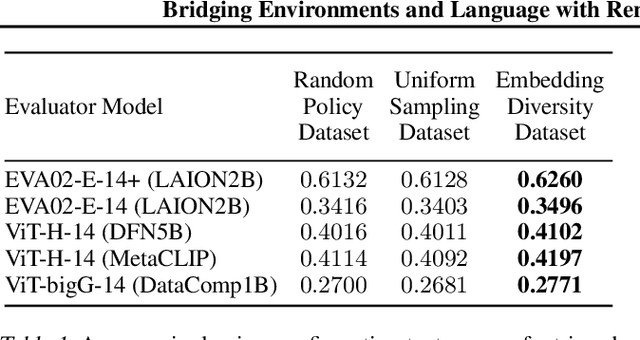

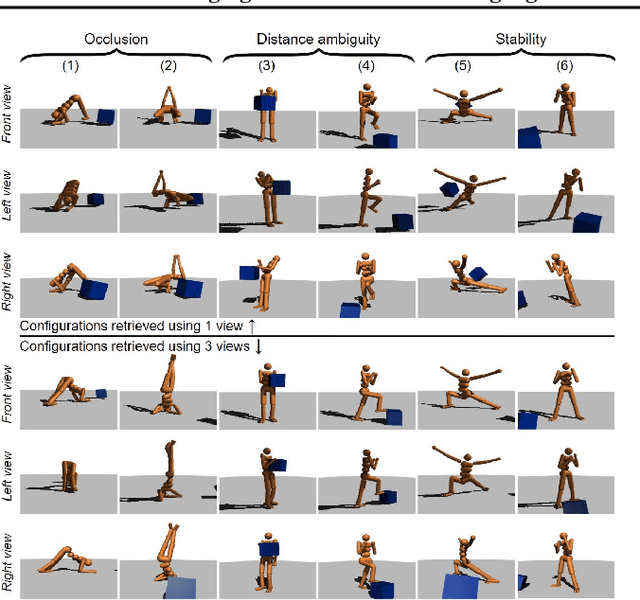
Vision-language models (VLMs) have tremendous potential for grounding language, and thus enabling language-conditioned agents (LCAs) to perform diverse tasks specified with text. This has motivated the study of LCAs based on reinforcement learning (RL) with rewards given by rendering images of an environment and evaluating those images with VLMs. If single-task RL is employed, such approaches are limited by the cost and time required to train a policy for each new task. Multi-task RL (MTRL) is a natural alternative, but requires a carefully designed corpus of training tasks and does not always generalize reliably to new tasks. Therefore, this paper introduces a novel decomposition of the problem of building an LCA: first find an environment configuration that has a high VLM score for text describing a task; then use a (pretrained) goal-conditioned policy to reach that configuration. We also explore several enhancements to the speed and quality of VLM-based LCAs, notably, the use of distilled models, and the evaluation of configurations from multiple viewpoints to resolve the ambiguities inherent in a single 2D view. We demonstrate our approach on the Humanoid environment, showing that it results in LCAs that outperform MTRL baselines in zero-shot generalization, without requiring any textual task descriptions or other forms of environment-specific annotation during training. Videos and an interactive demo can be found at https://europe.naverlabs.com/text2control