 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Environments and Language with Rendering Functions and Vision-Language Models
Sep 24, 2024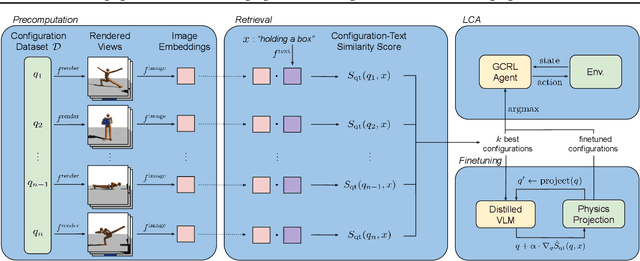
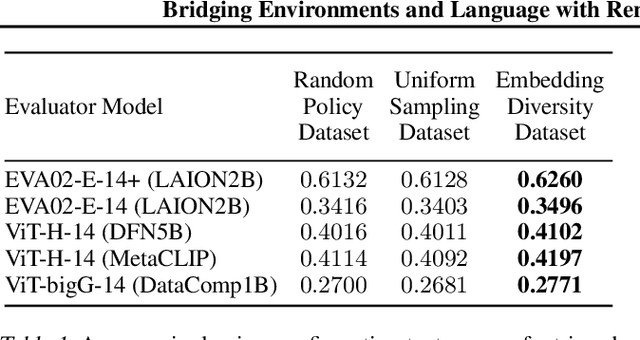

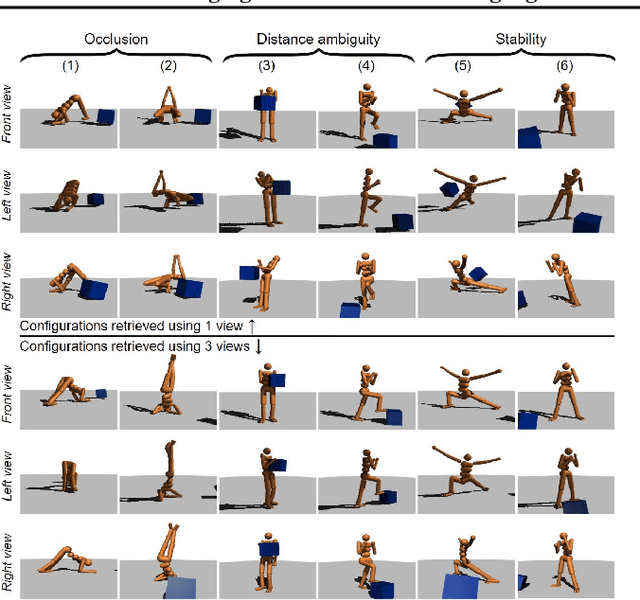
Vision-language models (VLMs) have tremendous potential for grounding language, and thus enabling language-conditioned agents (LCAs) to perform diverse tasks specified with text. This has motivated the study of LCAs based on reinforcement learning (RL) with rewards given by rendering images of an environment and evaluating those images with VLMs. If single-task RL is employed, such approaches are limited by the cost and time required to train a policy for each new task. Multi-task RL (MTRL) is a natural alternative, but requires a carefully designed corpus of training tasks and does not always generalize reliably to new tasks. Therefore, this paper introduces a novel decomposition of the problem of building an LCA: first find an environment configuration that has a high VLM score for text describing a task; then use a (pretrained) goal-conditioned policy to reach that configuration. We also explore several enhancements to the speed and quality of VLM-based LCAs, notably, the use of distilled models, and the evaluation of configurations from multiple viewpoints to resolve the ambiguities inherent in a single 2D view. We demonstrate our approach on the Humanoid environment, showing that it results in LCAs that outperform MTRL baselines in zero-shot generalization, without requiring any textual task descriptions or other forms of environment-specific annotation during training. Videos and an interactive demo can be found at https://europe.naverlabs.com/text2control
Risk-Conditioned Distributional Soft Actor-Critic for Risk-Sensitive Navigation
Apr 09, 2021
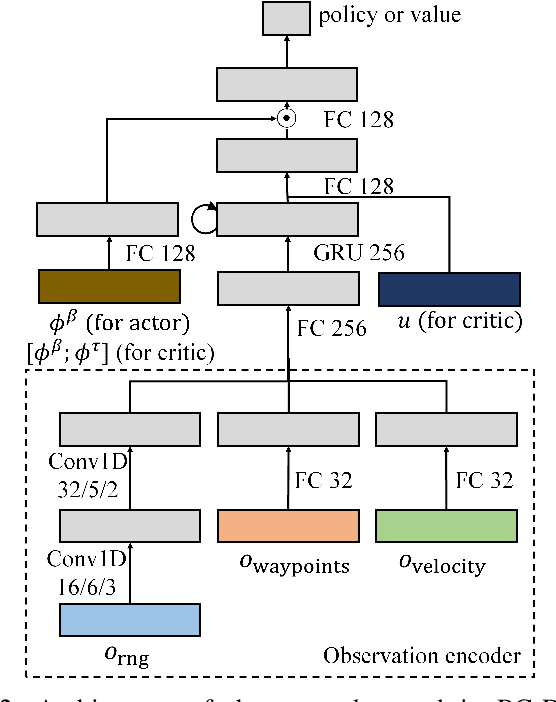


Modern navigation algorithms based on deep reinforcement learning (RL) show promising efficiency and robustness. However, most deep RL algorithms operate in a risk-neutral manner, making no special attempt to shield users from relatively rare but serious outcomes, even if such shielding might cause little loss of performance. Furthermore, such algorithms typically make no provisions to ensure safety in the presence of inaccuracies in the models on which they were trained, beyond adding a cost-of-collision and some domain randomization while training, in spite of the formidable complexity of the environments in which they operate. In this paper, we present a novel distributional RL algorithm that not only learns an uncertainty-aware policy, but can also change its risk measure without expensive fine-tuning or retraining. Our method shows superior performance and safety over baselines in partially-observed navigation tasks. We also demonstrate that agents trained using our method can adapt their policies to a wide range of risk measures at run-time.
Knowledge Graph Completion via Complex Tensor Factorization
Nov 26, 2017
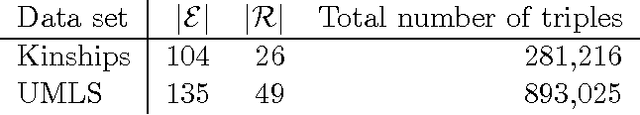
In statistical relational learning, knowledge graph completion deals with automatically understanding the structure of large knowledge graphs---labeled directed graphs---and predicting missing relationships---labeled edges. State-of-the-art embedding models propose different trade-offs between modeling expressiveness, and time and space complexity. We reconcile both expressiveness and complexity through the use of complex-valued embeddings and explore the link between such complex-valued embeddings and unitary diagonalization. We corroborate our approach theoretically and show that all real square matrices---thus all possible relation/adjacency matrices---are the real part of some unitarily diagonalizable matrix. This results opens the door to a lot of other applications of square matrices factorization. Our approach based on complex embeddings is arguably simple, as it only involves a Hermitian dot product, the complex counterpart of the standard dot product between real vectors, whereas other methods resort to more and more complicated composition functions to increase their expressiveness. The proposed complex embeddings are scalable to large data sets as it remains linear in both space and time, while consistently outperforming alternative approaches on standard link prediction benchmarks.
On Inductive Abilities of Latent Factor Models for Relational Learning
Sep 17, 2017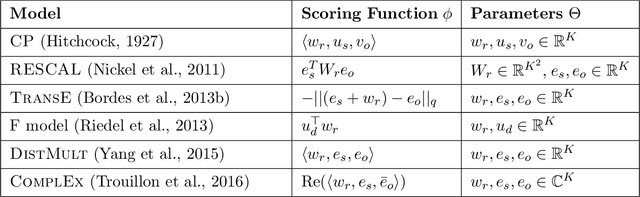
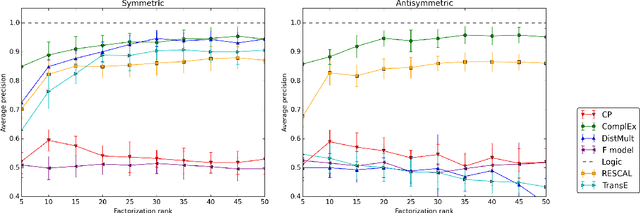

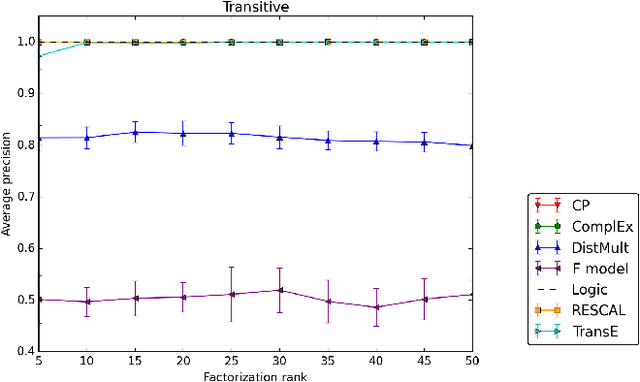
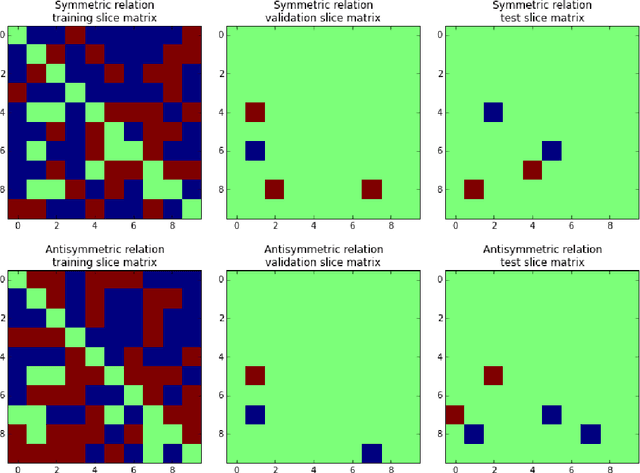
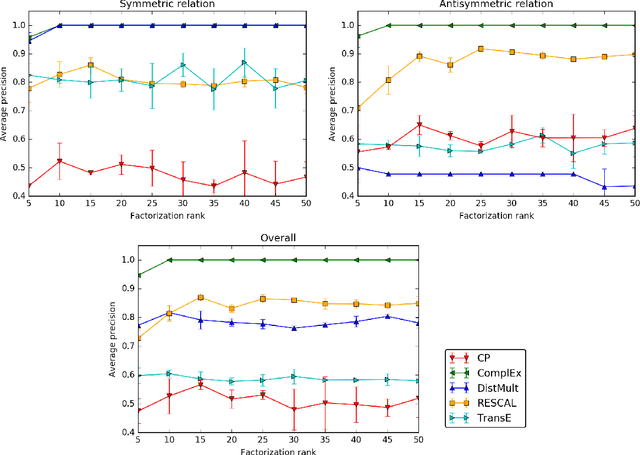
Latent factor models are increasingly popular for modeling multi-relational knowledge graphs. By their vectorial nature, it is not only hard to interpret why this class of models works so well, but also to understand where they fail and how they might be improved. We conduct an experimental survey of state-of-the-art models, not towards a purely comparative end, but as a means to get insight about their inductive abilities. To assess the strengths and weaknesses of each model, we create simple tasks that exhibit first, atomic properties of binary relations, and then, common inter-relational inference through synthetic genealogies. Based on these experimental results, we propose new research directions to improve on existing models.
Optimal Policies for Observing Time Series and Related Restless Bandit Problems
Mar 29, 2017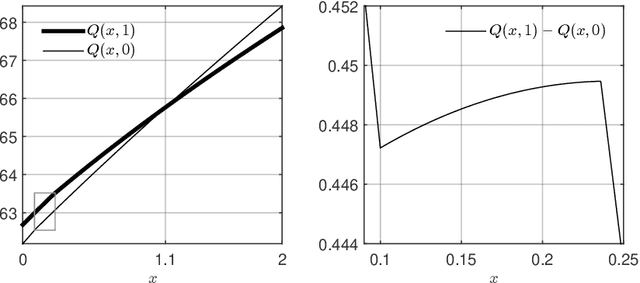
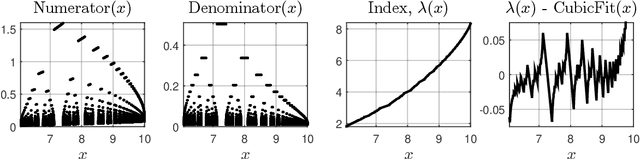
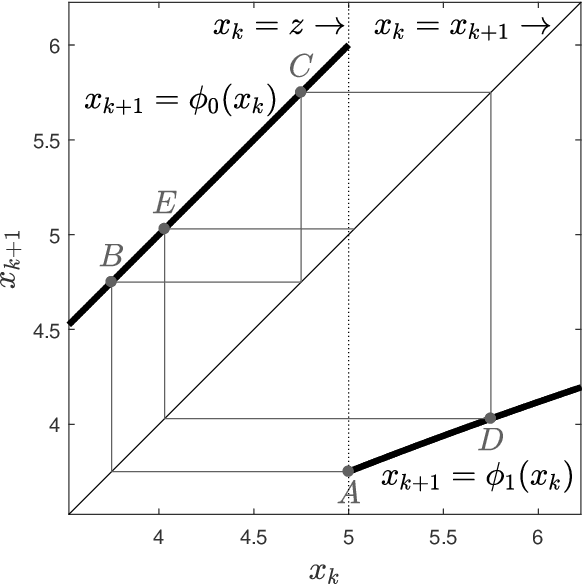

The trade-off between the cost of acquiring and processing data, and uncertainty due to a lack of data is fundamental in machine learning. A basic instance of this trade-off is the problem of deciding when to make noisy and costly observations of a discrete-time Gaussian random walk, so as to minimise the posterior variance plus observation costs. We present the first proof that a simple policy, which observes when the posterior variance exceeds a threshold, is optimal for this problem. The proof generalises to a wide range of cost functions other than the posterior variance. This result implies that optimal policies for linear-quadratic-Gaussian control with costly observations have a threshold structure. It also implies that the restless bandit problem of observing multiple such time series, has a well-defined Whittle index. We discuss computation of that index, give closed-form formulae for it, and compare the performance of the associated index policy with heuristic policies. The proof is based on a new verification theorem that demonstrates threshold structure for Markov decision processes, and on the relation between binary sequences known as mechanical words and the dynamics of discontinuous nonlinear maps, which frequently arise in physics, control and biology.
When are Kalman-filter restless bandits indexable?
Sep 15, 2015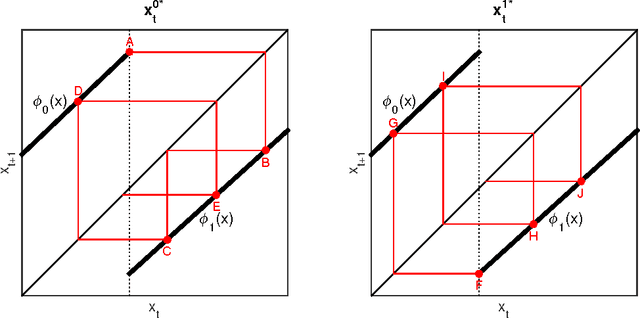


We study the restless bandit associated with an extremely simple scalar Kalman filter model in discrete time. Under certain assumptions, we prove that the problem is indexable in the sense that the Whittle index is a non-decreasing function of the relevant belief state. In spite of the long history of this problem, this appears to be the first such proof. We use results about Schur-convexity and mechanical words, which are particular binary strings intimately related to palindromes.
Dynamic Mechanism Design for Markets with Strategic Resources
Feb 14, 2012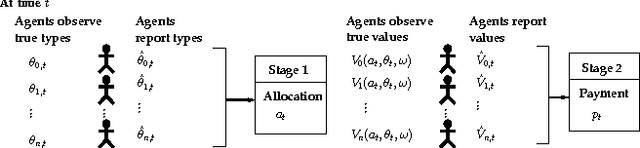
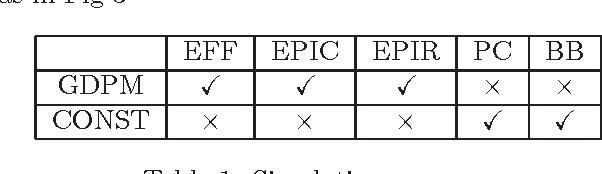
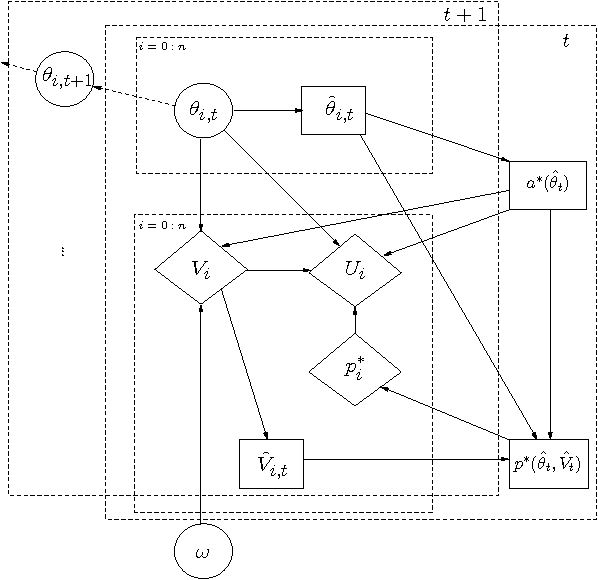
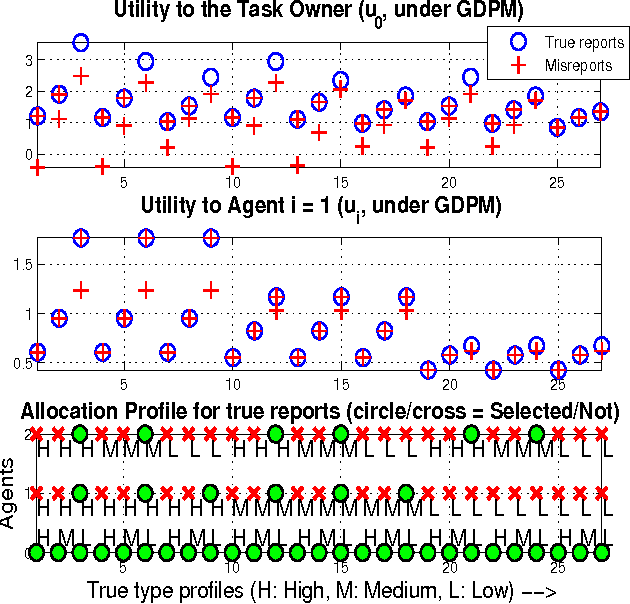
The assignment of tasks to multiple resources becomes an interesting game theoretic problem, when both the task owner and the resources are strategic. In the classical, nonstrategic setting, where the states of the tasks and resources are observable by the controller, this problem is that of finding an optimal policy for a Markov decision process (MDP). When the states are held by strategic agents, the problem of an efficient task allocation extends beyond that of solving an MDP and becomes that of designing a mechanism. Motivated by this fact, we propose a general mechanism which decides on an allocation rule for the tasks and resources and a payment rule to incentivize agents' participation and truthful reports. In contrast to related dynamic strategic control problems studied in recent literature, the problem studied here has interdependent values: the benefit of an allocation to the task owner is not simply a function of the characteristics of the task itself and the allocation, but also of the state of the resources. We introduce a dynamic extension of Mezzetti's two phase mechanism for interdependent valuations. In this changed setting, the proposed dynamic mechanism is efficient, within period ex-post incentive compatible, and within period ex-post individually rational.