 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Abusive Language on Online Platforms: A Critical Analysis
Feb 27, 2021
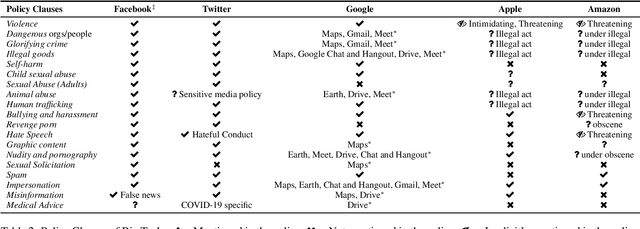
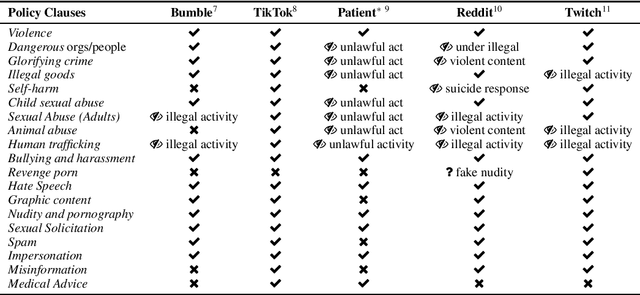

Abusive language on online platforms is a major societal problem, often leading to important societal problems such as the marginalisation of underrepresented minorities. There are many different forms of abusive language such as hate speech, profanity, and cyber-bullying, and online platforms seek to moderate it in order to limit societal harm, to comply with legislation, and to create a more inclusive environment for their users. Within the field of Natural Language Processing, researchers have developed different methods for automatically detecting abusive language, often focusing on specific subproblems or on narrow communities, as what is considered abusive language very much differs by context. We argue that there is currently a dichotomy between what types of abusive language online platforms seek to curb, and what research efforts there are to automatically detect abusive language. We thus survey existing methods as well as content moderation policies by online platforms in this light, and we suggest directions for future work.
Interpretation of Natural Language Rules in Conversational Machine Reading
Aug 28, 2018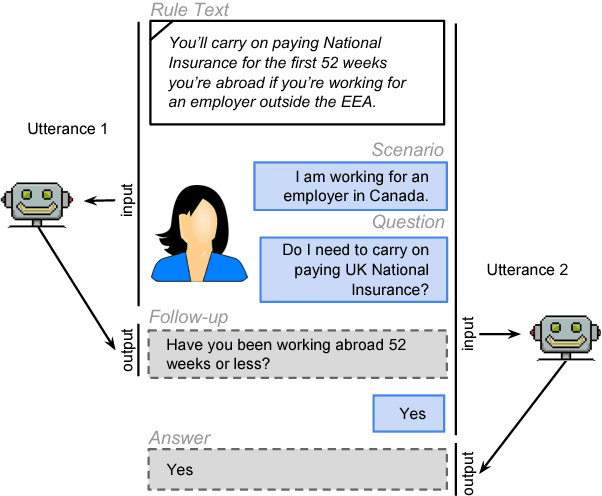

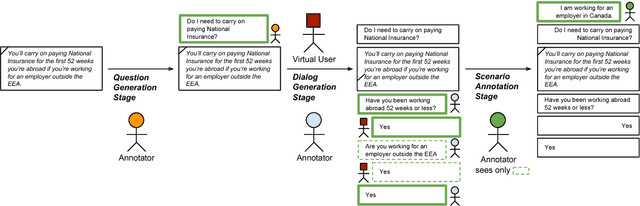
Most work in machine reading focuses on question answering problems where the answer is directly expressed in the text to read. However, many real-world question answering problems require the reading of text not because it contains the literal answer, but because it contains a recipe to derive an answer together with the reader's background knowledge. One example is the task of interpreting regulations to answer "Can I...?" or "Do I have to...?" questions such as "I am working in Canada. Do I have to carry on paying UK National Insurance?" after reading a UK government website about this topic. This task requires both the interpretation of rules and the application of background knowledge. It is further complicated due to the fact that, in practice, most questions are underspecified, and a human assistant will regularly have to ask clarification questions such as "How long have you been working abroad?" when the answer cannot be directly derived from the question and text. In this paper, we formalise this task and develop a crowd-sourcing strategy to collect 32k task instances based on real-world rules and crowd-generated questions and scenarios. We analyse the challenges of this task and assess its difficulty by evaluating the performance of rule-based and machine-learning baselines. We observe promising results when no background knowledge is necessary, and substantial room for improvement whenever background knowledge is needed.
Knowledge Graph Completion via Complex Tensor Factorization
Nov 26, 2017
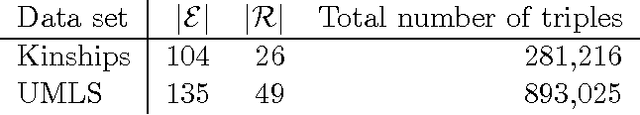
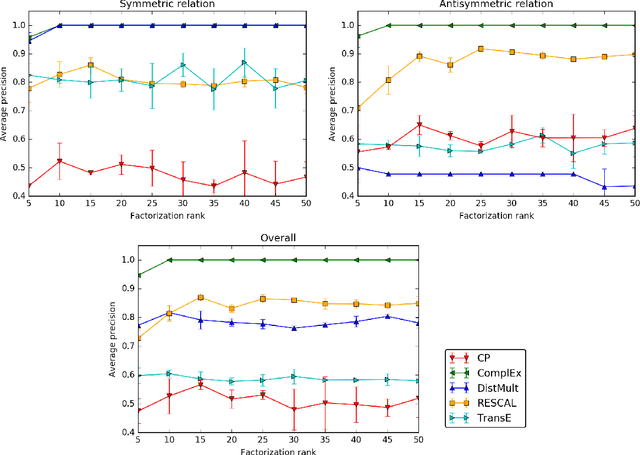
In statistical relational learning, knowledge graph completion deals with automatically understanding the structure of large knowledge graphs---labeled directed graphs---and predicting missing relationships---labeled edges. State-of-the-art embedding models propose different trade-offs between modeling expressiveness, and time and space complexity. We reconcile both expressiveness and complexity through the use of complex-valued embeddings and explore the link between such complex-valued embeddings and unitary diagonalization. We corroborate our approach theoretically and show that all real square matrices---thus all possible relation/adjacency matrices---are the real part of some unitarily diagonalizable matrix. This results opens the door to a lot of other applications of square matrices factorization. Our approach based on complex embeddings is arguably simple, as it only involves a Hermitian dot product, the complex counterpart of the standard dot product between real vectors, whereas other methods resort to more and more complicated composition functions to increase their expressiveness. The proposed complex embeddings are scalable to large data sets as it remains linear in both space and time, while consistently outperforming alternative approaches on standard link prediction benchmarks.
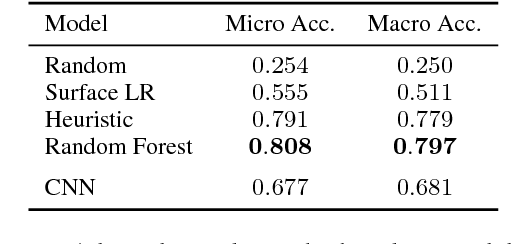
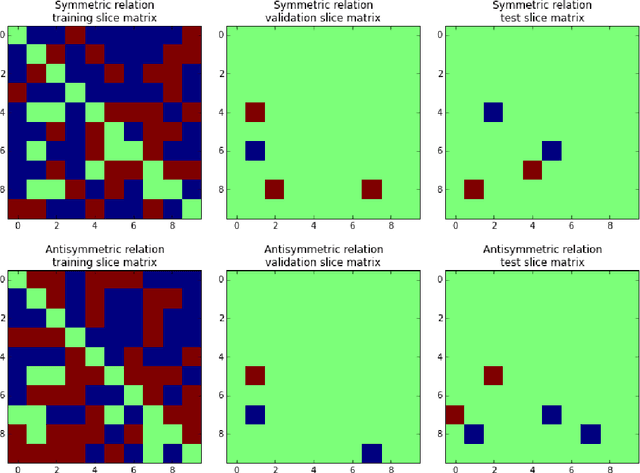
On Inductive Abilities of Latent Factor Models for Relational Learning
Sep 17, 2017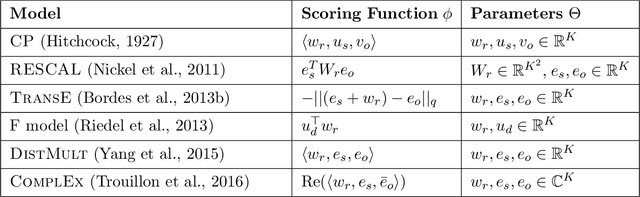
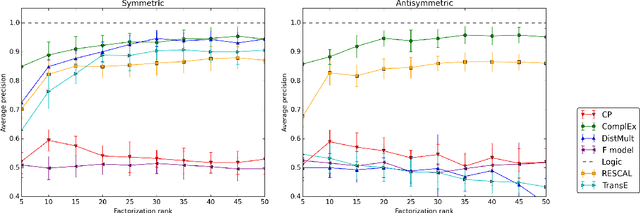

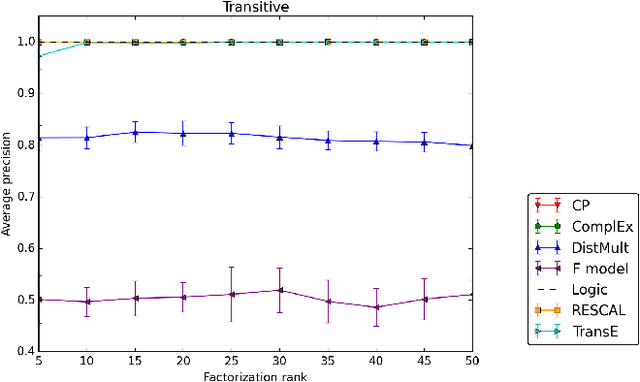
Latent factor models are increasingly popular for modeling multi-relational knowledge graphs. By their vectorial nature, it is not only hard to interpret why this class of models works so well, but also to understand where they fail and how they might be improved. We conduct an experimental survey of state-of-the-art models, not towards a purely comparative end, but as a means to get insight about their inductive abilities. To assess the strengths and weaknesses of each model, we create simple tasks that exhibit first, atomic properties of binary relations, and then, common inter-relational inference through synthetic genealogies. Based on these experimental results, we propose new research directions to improve on existing models.
SentiHood: Targeted Aspect Based Sentiment Analysis Dataset for Urban Neighbourhoods
Oct 12, 2016
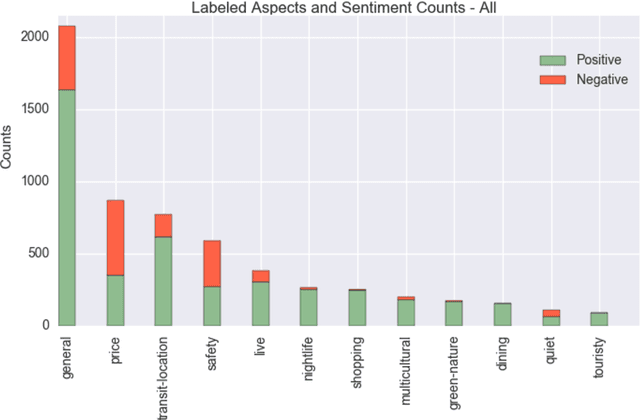
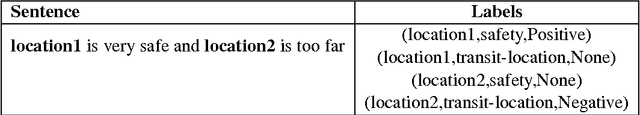
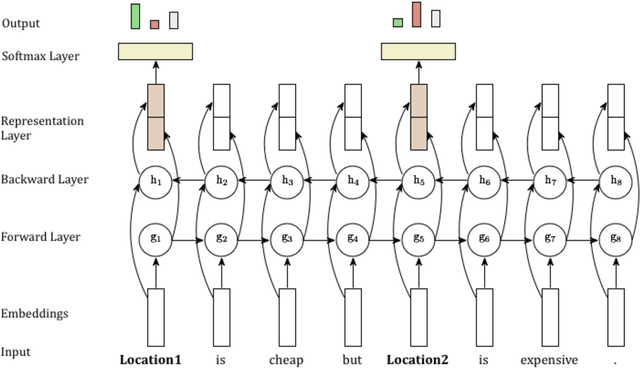
In this paper, we introduce the task of targeted aspect-based sentiment analysis. The goal is to extract fine-grained information with respect to entities mentioned in user comments. This work extends both aspect-based sentiment analysis that assumes a single entity per document and targeted sentiment analysis that assumes a single sentiment towards a target entity. In particular, we identify the sentiment towards each aspect of one or more entities. As a testbed for this task, we introduce the SentiHood dataset, extracted from a question answering (QA) platform where urban neighbourhoods are discussed by users. In this context units of text often mention several aspects of one or more neighbourhoods. This is the first time that a generic social media platform in this case a QA platform, is used for fine-grained opinion mining. Text coming from QA platforms is far less constrained compared to text from review specific platforms which current datasets are based on. We develop several strong baselines, relying on logistic regression and state-of-the-art recurrent neural networks.
Complex Embeddings for Simple Link Prediction
Jun 20, 2016
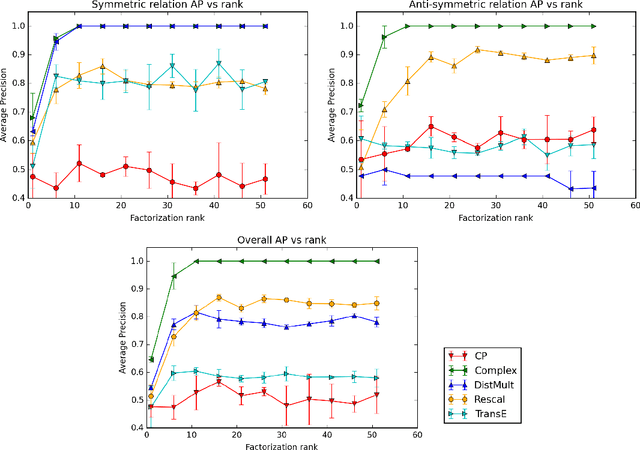
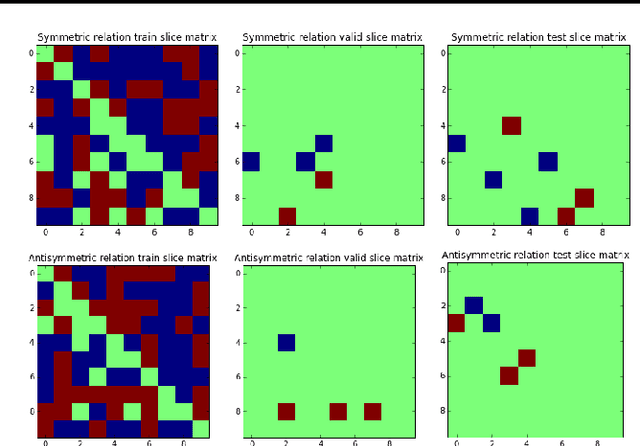
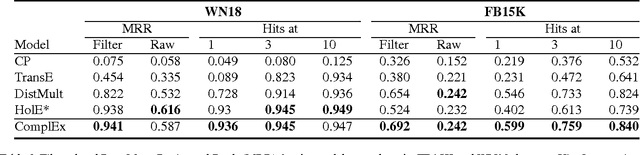
In statistical relational learning, the link prediction problem is key to automatically understand the structure of large knowledge bases. As in previous studies, we propose to solve this problem through latent factorization. However, here we make use of complex valued embeddings. The composition of complex embeddings can handle a large variety of binary relations, among them symmetric and antisymmetric relations. Compared to state-of-the-art models such as Neural Tensor Network and Holographic Embeddings, our approach based on complex embeddings is arguably simpler, as it only uses the Hermitian dot product, the complex counterpart of the standard dot product between real vectors. Our approach is scalable to large datasets as it remains linear in both space and time, while consistently outperforming alternative approaches on standard link prediction benchmarks.
A Factorization Machine Framework for Testing Bigram Embeddings in Knowledgebase Completion
Apr 20, 2016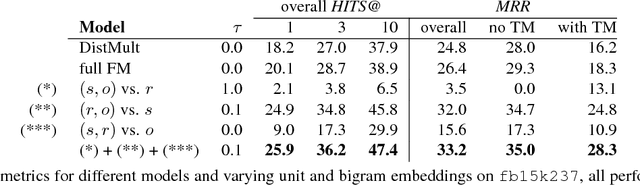
Embedding-based Knowledge Base Completion models have so far mostly combined distributed representations of individual entities or relations to compute truth scores of missing links. Facts can however also be represented using pairwise embeddings, i.e. embeddings for pairs of entities and relations. In this paper we explore such bigram embeddings with a flexible Factorization Machine model and several ablations from it. We investigate the relevance of various bigram types on the fb15k237 dataset and find relative improvements compared to a compositional model.
Online Learning to Sample
Mar 15, 2016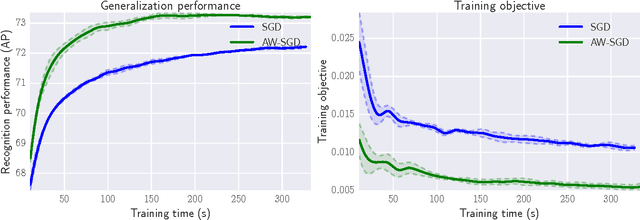

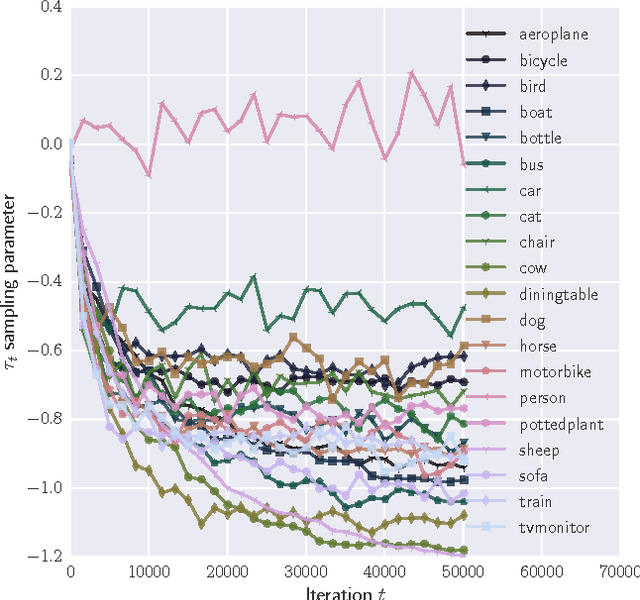
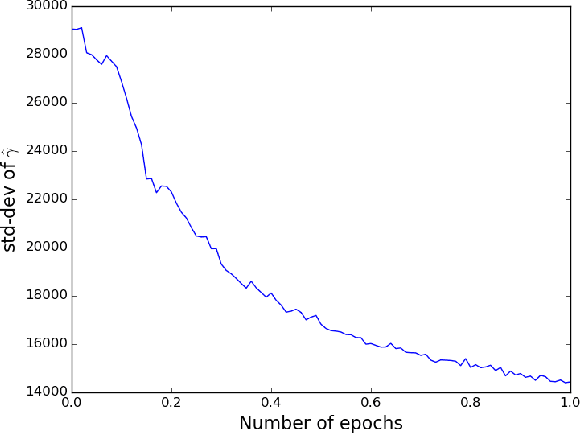
Stochastic Gradient Descent (SGD) is one of the most widely used techniques for online optimization in machine learning. In this work, we accelerate SGD by adaptively learning how to sample the most useful training examples at each time step. First, we show that SGD can be used to learn the best possible sampling distribution of an importance sampling estimator. Second, we show that the sampling distribution of an SGD algorithm can be estimated online by incrementally minimizing the variance of the gradient. The resulting algorithm - called Adaptive Weighted SGD (AW-SGD) - maintains a set of parameters to optimize, as well as a set of parameters to sample learning examples. We show that AWSGD yields faster convergence in three different applications: (i) image classification with deep features, where the sampling of images depends on their labels, (ii) matrix factorization, where rows and columns are not sampled uniformly, and (iii) reinforcement learning, where the optimized and exploration policies are estimated at the same time, where our approach corresponds to an off-policy gradient algorithm.
Approximate Inference with the Variational Holder Bound
Jun 19, 2015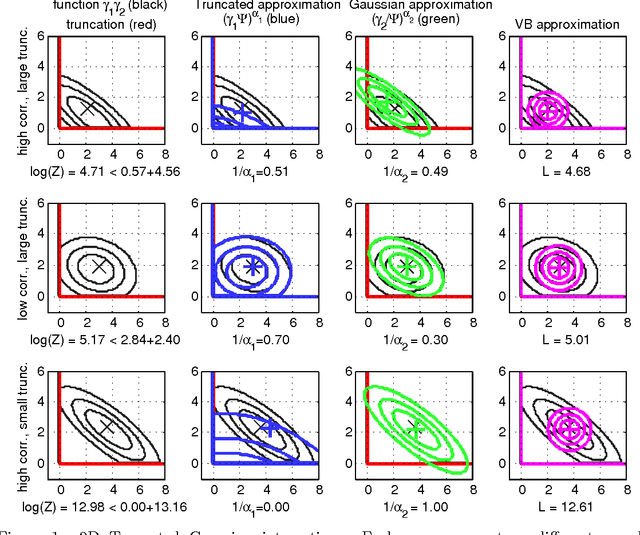

We introduce the Variational Holder (VH) bound as an alternative to Variational Bayes (VB) for approximate Bayesian inference. Unlike VB which typically involves maximization of a non-convex lower bound with respect to the variational parameters, the VH bound involves minimization of a convex upper bound to the intractable integral with respect to the variational parameters. Minimization of the VH bound is a convex optimization problem; hence the VH method can be applied using off-the-shelf convex optimization algorithms and the approximation error of the VH bound can also be analyzed using tools from convex optimization literature. We present experiments on the task of integrating a truncated multivariate Gaussian distribution and compare our method to VB, EP and a state-of-the-art numerical integration method for this problem.
Overlapping Trace Norms in Multi-View Learning
Apr 27, 2014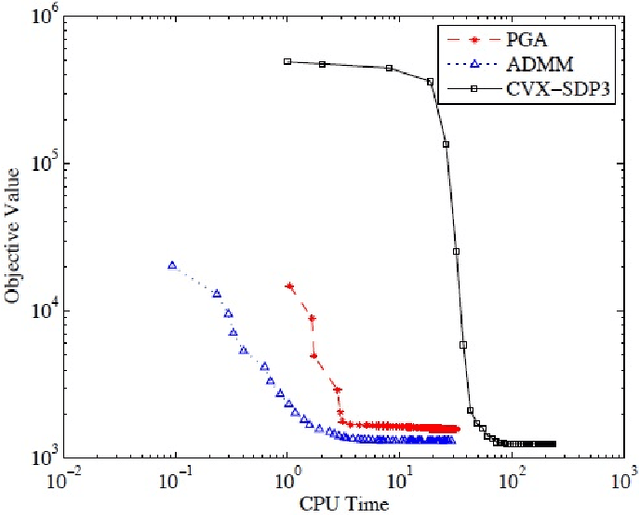
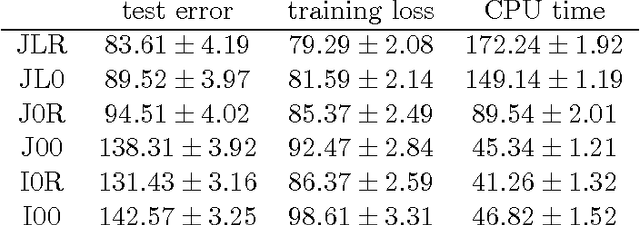
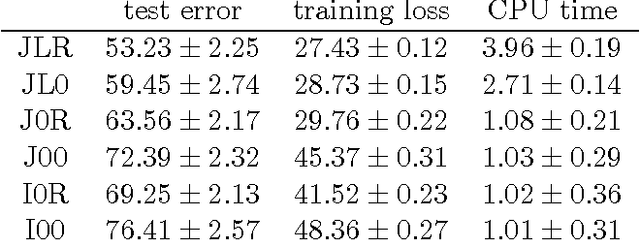

Multi-view learning leverages correlations between different sources of data to make predictions in one view based on observations in another view. A popular approach is to assume that, both, the correlations between the views and the view-specific covariances have a low-rank structure, leading to inter-battery factor analysis, a model closely related to canonical correlation analysis. We propose a convex relaxation of this model using structured norm regularization. Further, we extend the convex formulation to a robust version by adding an l1-penalized matrix to our estimator, similarly to convex robust PCA. We develop and compare scalable algorithms for several convex multi-view models. We show experimentally that the view-specific correlations are improving data imputation performances, as well as labeling accuracy in real-world multi-label prediction tasks.