 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning is Forgetting: LLM Training As Lossy Compression
Apr 08, 2026Despite the increasing prevalence of large language models (LLMs), we still have a limited understanding of how their representational spaces are structured. This limits our ability to interpret how and what they learn or relate them to learning in humans. We argue LLMs are best seen as an instance of lossy compression, where over training they learn by retaining only information in their training data relevant to their objective(s). We show pre-training results in models that are optimally compressed for next-sequence prediction, approaching the Information Bottleneck bound on compression. Across an array of open weights models, each compresses differently, likely due to differences in the data and training recipes used. However even across different families of LLMs the optimality of a model's compression, and the information present in it, can predict downstream performance on across a wide array of benchmarks, letting us directly link representational structure to actionable insights about model performance. In the general case the work presented here offers a unified Information-Theoretic framing for how these models learn that is deployable at scale.
Reverse Engineering Human Preferences with Reinforcement Learning
May 21, 2025The capabilities of Large Language Models (LLMs) are routinely evaluated by other LLMs trained to predict human preferences. This framework--known as LLM-as-a-judge--is highly scalable and relatively low cost. However, it is also vulnerable to malicious exploitation, as LLM responses can be tuned to overfit the preferences of the judge. Previous work shows that the answers generated by a candidate-LLM can be edited post hoc to maximise the score assigned to them by a judge-LLM. In this study, we adopt a different approach and use the signal provided by judge-LLMs as a reward to adversarially tune models that generate text preambles designed to boost downstream performance. We find that frozen LLMs pipelined with these models attain higher LLM-evaluation scores than existing frameworks. Crucially, unlike other frameworks which intervene directly on the model's response, our method is virtually undetectable. We also demonstrate that the effectiveness of the tuned preamble generator transfers when the candidate-LLM and the judge-LLM are replaced with models that are not used during training. These findings raise important questions about the design of more reliable LLM-as-a-judge evaluation settings. They also demonstrate that human preferences can be reverse engineered effectively, by pipelining LLMs to optimise upstream preambles via reinforcement learning--an approach that could find future applications in diverse tasks and domains beyond adversarial attacks.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
LLMs can implicitly learn from mistakes in-context
Feb 12, 2025Learning from mistakes is a fundamental feature of human intelligence. Previous work has shown that Large Language Models (LLMs) can also learn from incorrect answers when provided with a comprehensive rationale detailing why an answer is wrong or how to correct it. In this work, we examine whether LLMs can learn from mistakes in mathematical reasoning tasks when these explanations are not provided. We investigate if LLMs are able to implicitly infer such rationales simply from observing both incorrect and correct answers. Surprisingly, we find that LLMs perform better, on average, when rationales are eliminated from the context and incorrect answers are simply shown alongside correct ones. This approach also substantially outperforms chain-of-thought prompting in our evaluations. We show that these results are consistent across LLMs of different sizes and varying reasoning abilities. Further, we carry out an in-depth analysis, and show that prompting with both wrong and correct answers leads to greater performance and better generalisation than introducing additional, more diverse question-answer pairs into the context. Finally, we show that new rationales generated by models that have only observed incorrect and correct answers are scored equally as highly by humans as those produced with the aid of exemplar rationales. Our results demonstrate that LLMs are indeed capable of in-context implicit learning.
Atla Selene Mini: A General Purpose Evaluation Model
Jan 27, 2025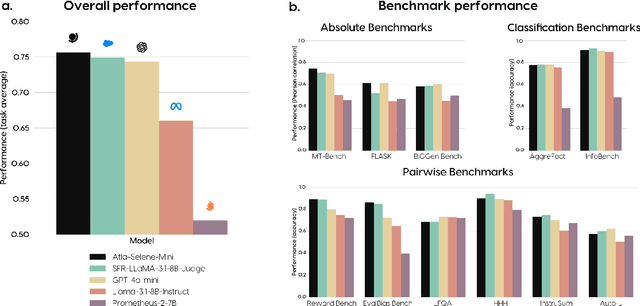
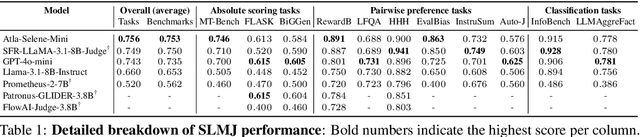

We introduce Atla Selene Mini, a state-of-the-art small language model-as-a-judge (SLMJ). Selene Mini is a general-purpose evaluator that outperforms the best SLMJs and GPT-4o-mini on overall performance across 11 out-of-distribution benchmarks, spanning absolute scoring, classification, and pairwise preference tasks. It is the highest-scoring 8B generative model on RewardBench, surpassing strong baselines like GPT-4o and specialized judges. To achieve this, we develop a principled data curation strategy that augments public datasets with synthetically generated critiques and ensures high quality through filtering and dataset ablations. We train our model on a combined direct preference optimization (DPO) and supervised fine-tuning (SFT) loss, and produce a highly promptable evaluator that excels in real-world scenarios. Selene Mini shows dramatically improved zero-shot agreement with human expert evaluations on financial and medical industry datasets. It is also robust to variations in prompt format. Preliminary results indicate that Selene Mini is the top-ranking evaluator in a live, community-driven Judge Arena. We release the model weights on HuggingFace (https://hf.co/AtlaAI/Selene-1-Mini-Llama-3.1-8B) and Ollama to encourage widespread community adoption.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
Nov 19, 2024



The capabilities and limitations of Large Language Models have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstrate a general ability to solve problems. On the other hand, they show surprising reasoning gaps when compared to humans, casting doubt on the robustness of their generalisation strategies. The sheer volume of data used in the design of LLMs has precluded us from applying the method traditionally used to measure generalisation: train-test set separation. To overcome this, we study what kind of generalisation strategies LLMs employ when performing reasoning tasks by investigating the pretraining data they rely on. For two models of different sizes (7B and 35B) and 2.5B of their pretraining tokens, we identify what documents influence the model outputs for three simple mathematical reasoning tasks and contrast this to the data that are influential for answering factual questions. We find that, while the models rely on mostly distinct sets of data for each factual question, a document often has a similar influence across different reasoning questions within the same task, indicating the presence of procedural knowledge. We further find that the answers to factual questions often show up in the most influential data. However, for reasoning questions the answers usually do not show up as highly influential, nor do the answers to the intermediate reasoning steps. When we characterise the top ranked documents for the reasoning questions qualitatively, we confirm that the influential documents often contain procedural knowledge, like demonstrating how to obtain a solution using formulae or code. Our findings indicate that the approach to reasoning the models use is unlike retrieval, and more like a generalisable strategy that synthesises procedural knowledge from documents doing a similar form of reasoning.
Understanding Likelihood Over-optimisation in Direct Alignment Algorithms
Oct 15, 2024



Direct Alignment Algorithms (DAAs), such as Direct Preference Optimisation (DPO) and Identity Preference Optimisation (IPO), have emerged as alternatives to online Reinforcement Learning from Human Feedback (RLHF) algorithms such as Proximal Policy Optimisation (PPO) for aligning language models to human preferences, without the need for explicit reward modelling. These methods generally aim to increase the likelihood of generating better (preferred) completions while discouraging worse (non-preferred) ones, while staying close to the original model's behaviour. In this work, we explore the relationship between completion likelihood and model performance in state-of-the-art DAAs, and identify a critical issue of likelihood over-optimisation. Contrary to expectations, we find that higher likelihood of better completions and larger margins between better and worse completion likelihoods do not necessarily lead to better performance, and may even degrade it. Our analysis reveals that while higher likelihood correlates with better memorisation of factual knowledge patterns, a slightly lower completion likelihood tends to improve output diversity, thus leading to better generalisation to unseen scenarios. Moreover, we identify two key indicators that signal when over-optimised output diversity begins to harm performance: Decreasing Entropy over Top-k Tokens and Diminishing Top-k Probability Mass. Our experimental results validate that these indicators are reliable signs of declining performance under different regularisations, helping prevent over-optimisation and improve alignment with human preferences.
Improving Reward Models with Synthetic Critiques
May 31, 2024

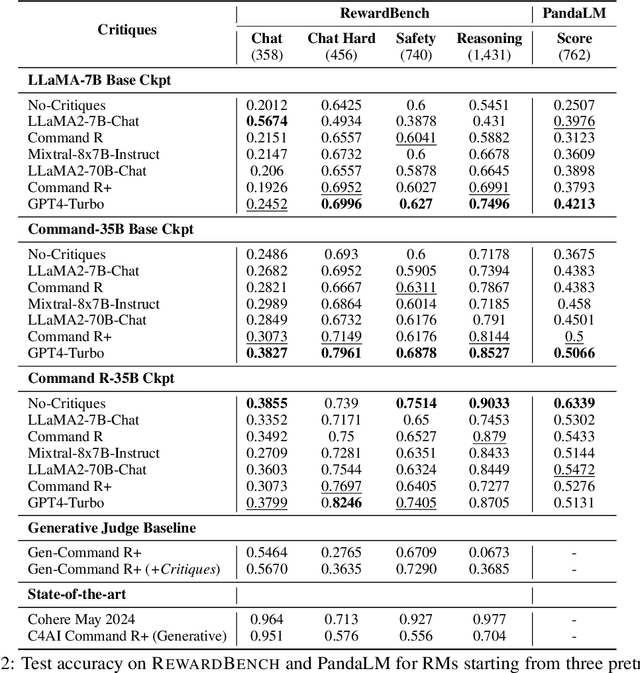
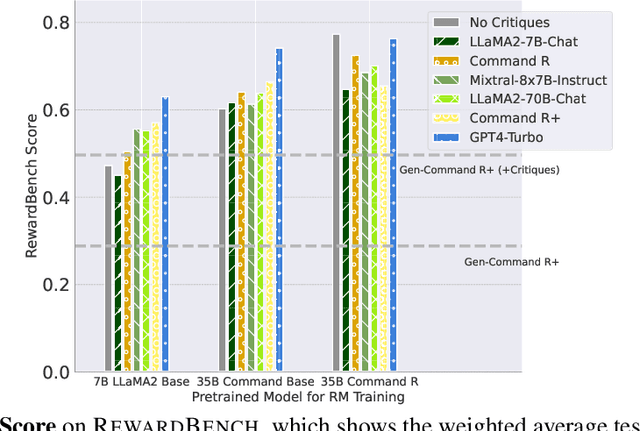
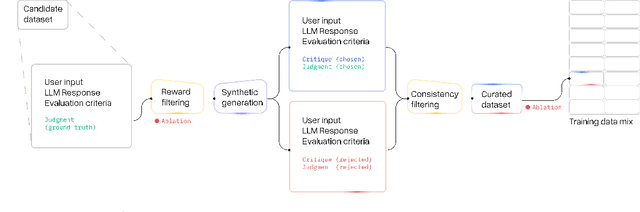
Reward models (RM) play a critical role in aligning language models through the process of reinforcement learning from human feedback. RMs are trained to predict a score reflecting human preference, which requires significant time and cost for human annotation. Additionally, RMs tend to quickly overfit on superficial features in the training set, hindering their generalization performance on unseen distributions. We propose a novel approach using synthetic natural language critiques generated by large language models to provide additional feedback, evaluating aspects such as instruction following, correctness, and style. This offers richer signals and more robust features for RMs to assess and score on. We demonstrate that high-quality critiques improve the performance and data efficiency of RMs initialized from different pretrained models. Conversely, we also show that low-quality critiques negatively impact performance. Furthermore, incorporating critiques enhances the interpretability and robustness of RM training.
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
May 08, 2024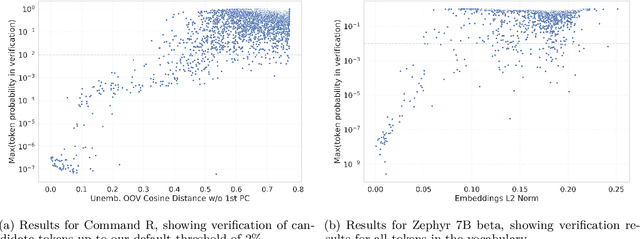
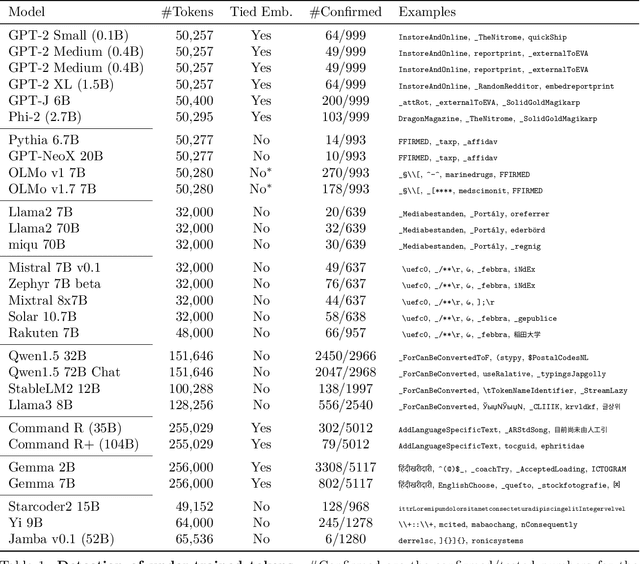
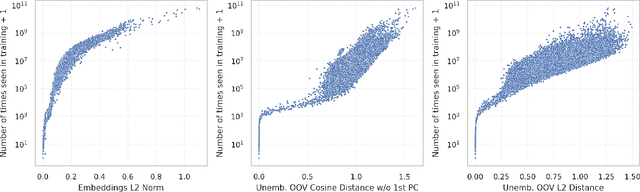
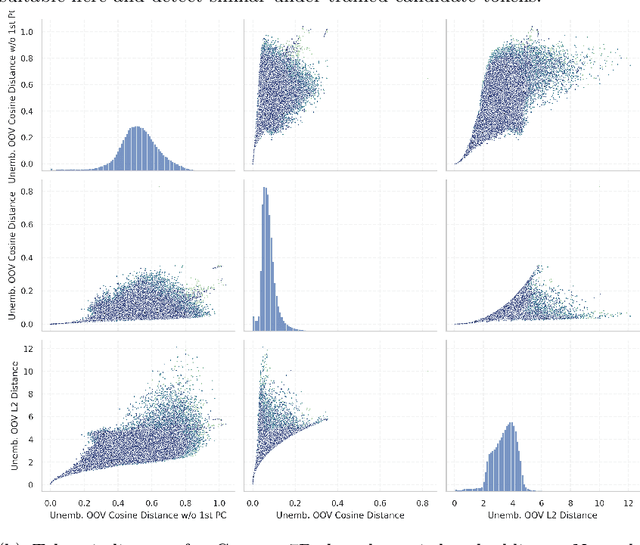
The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. Although such `glitch tokens' that are present in the tokenizer vocabulary, but are nearly or fully absent in training, have been observed across a variety of different models, a consistent way of identifying them has been missing. We present a comprehensive analysis of Large Language Model (LLM) tokenizers, specifically targeting this issue of detecting untrained and under-trained tokens. Through a combination of tokenizer analysis, model weight-based indicators, and prompting techniques, we develop effective methods for automatically detecting these problematic tokens. Our findings demonstrate the prevalence of such tokens across various models and provide insights into improving the efficiency and safety of language models.