 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs can implicitly learn from mistakes in-context
Feb 12, 2025Learning from mistakes is a fundamental feature of human intelligence. Previous work has shown that Large Language Models (LLMs) can also learn from incorrect answers when provided with a comprehensive rationale detailing why an answer is wrong or how to correct it. In this work, we examine whether LLMs can learn from mistakes in mathematical reasoning tasks when these explanations are not provided. We investigate if LLMs are able to implicitly infer such rationales simply from observing both incorrect and correct answers. Surprisingly, we find that LLMs perform better, on average, when rationales are eliminated from the context and incorrect answers are simply shown alongside correct ones. This approach also substantially outperforms chain-of-thought prompting in our evaluations. We show that these results are consistent across LLMs of different sizes and varying reasoning abilities. Further, we carry out an in-depth analysis, and show that prompting with both wrong and correct answers leads to greater performance and better generalisation than introducing additional, more diverse question-answer pairs into the context. Finally, we show that new rationales generated by models that have only observed incorrect and correct answers are scored equally as highly by humans as those produced with the aid of exemplar rationales. Our results demonstrate that LLMs are indeed capable of in-context implicit learning.
GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing
Sep 29, 2020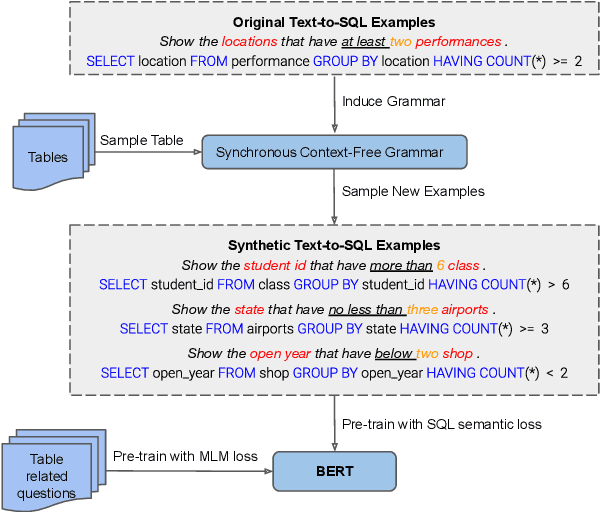


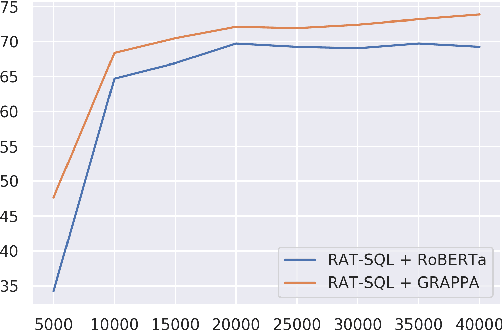
We present GraPPa, an effective pre-training approach for table semantic parsing that learns a compositional inductive bias in the joint representations of textual and tabular data. We construct synthetic question-SQL pairs over high-quality tables via a synchronous context-free grammar (SCFG) induced from existing text-to-SQL datasets. We pre-train our model on the synthetic data using a novel text-schema linking objective that predicts the syntactic role of a table field in the SQL for each question-SQL pair. To maintain the model's ability to represent real-world data, we also include masked language modeling (MLM) over several existing table-and-language datasets to regularize the pre-training process. On four popular fully supervised and weakly supervised table semantic parsing benchmarks, GraPPa significantly outperforms RoBERTa-large as the feature representation layers and establishes new state-of-the-art results on all of them.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020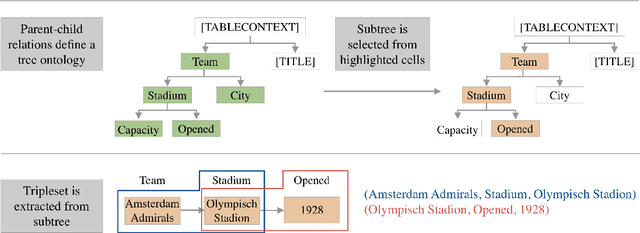
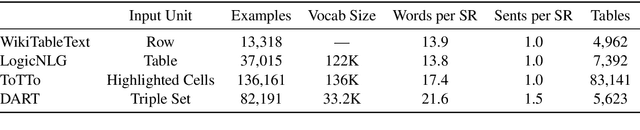
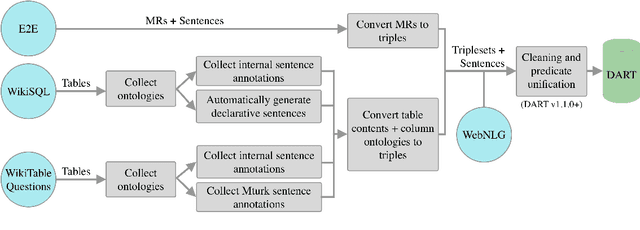
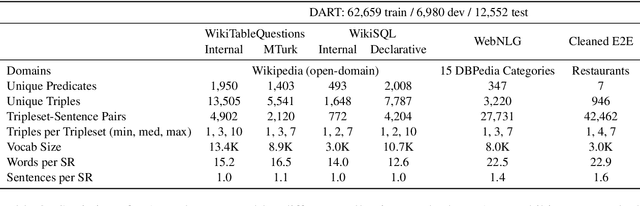
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
May 14, 2020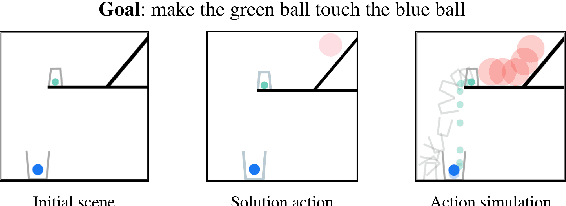

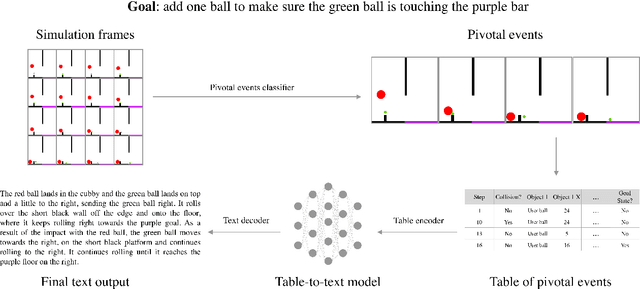
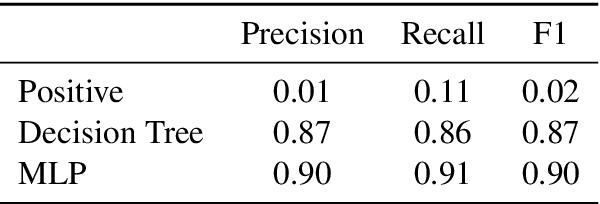
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations. Dataset, code and documentation are available at https://github.com/salesforce/esprit.
Assessing Social and Intersectional Biases in Contextualized Word Representations
Nov 04, 2019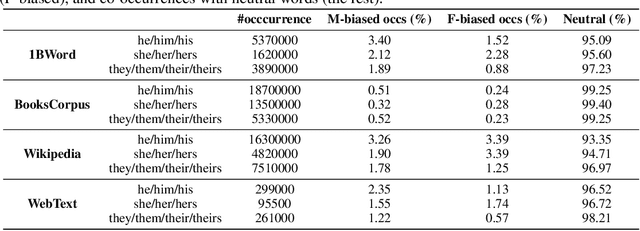

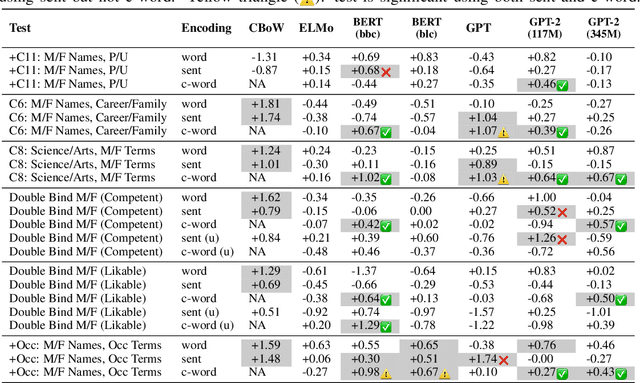

Social bias in machine learning has drawn significant attention, with work ranging from demonstrations of bias in a multitude of applications, curating definitions of fairness for different contexts, to developing algorithms to mitigate bias. In natural language processing, gender bias has been shown to exist in context-free word embeddings. Recently, contextual word representations have outperformed word embeddings in several downstream NLP tasks. These word representations are conditioned on their context within a sentence, and can also be used to encode the entire sentence. In this paper, we analyze the extent to which state-of-the-art models for contextual word representations, such as BERT and GPT-2, encode biases with respect to gender, race, and intersectional identities. Towards this, we propose assessing bias at the contextual word level. This novel approach captures the contextual effects of bias missing in context-free word embeddings, yet avoids confounding effects that underestimate bias at the sentence encoding level. We demonstrate evidence of bias at the corpus level, find varying evidence of bias in embedding association tests, show in particular that racial bias is strongly encoded in contextual word models, and observe that bias effects for intersectional minorities are exacerbated beyond their constituent minority identities. Further, evaluating bias effects at the contextual word level captures biases that are not captured at the sentence level, confirming the need for our novel approach.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
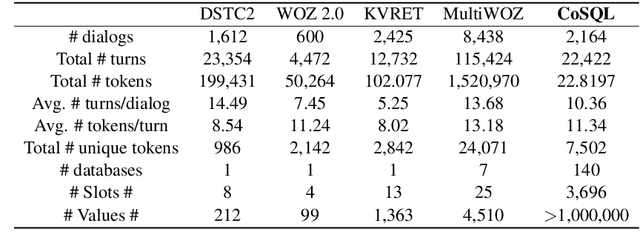
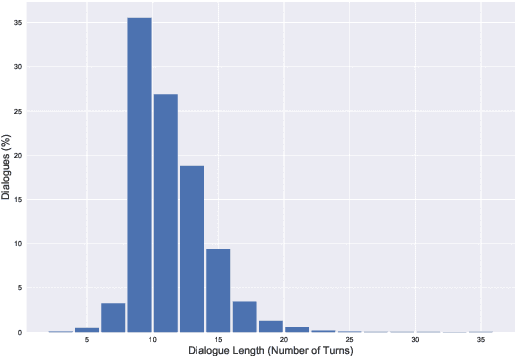
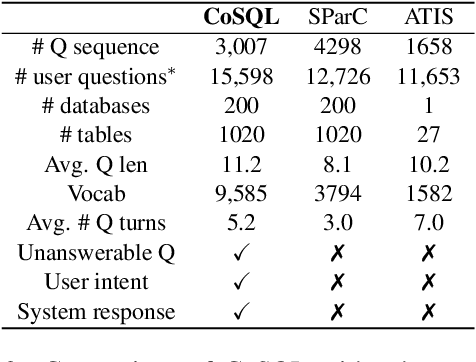
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
SParC: Cross-Domain Semantic Parsing in Context
Jun 05, 2019
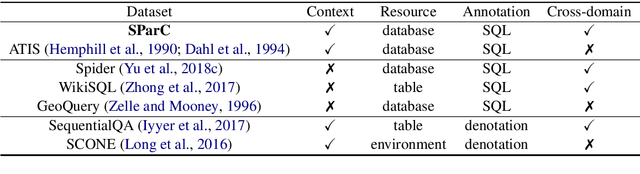

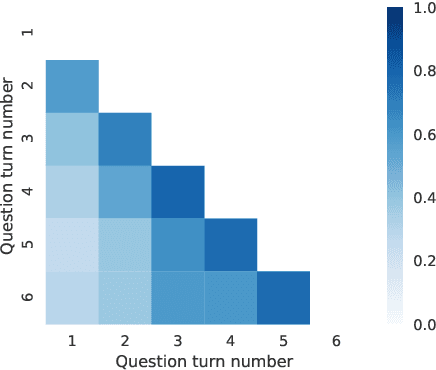
We present SParC, a dataset for cross-domainSemanticParsing inContext that consists of 4,298 coherent question sequences (12k+ individual questions annotated with SQL queries). It is obtained from controlled user interactions with 200 complex databases over 138 domains. We provide an in-depth analysis of SParC and show that it introduces new challenges compared to existing datasets. SParC demonstrates complex contextual dependencies, (2) has greater semantic diversity, and (3) requires generalization to unseen domains due to its cross-domain nature and the unseen databases at test time. We experiment with two state-of-the-art text-to-SQL models adapted to the context-dependent, cross-domain setup. The best model obtains an exact match accuracy of 20.2% over all questions and less than10% over all interaction sequences, indicating that the cross-domain setting and the con-textual phenomena of the dataset present significant challenges for future research. The dataset, baselines, and leaderboard are released at https://yale-lily.github.io/sparc.
Open Sesame: Getting Inside BERT's Linguistic Knowledge
Jun 04, 2019
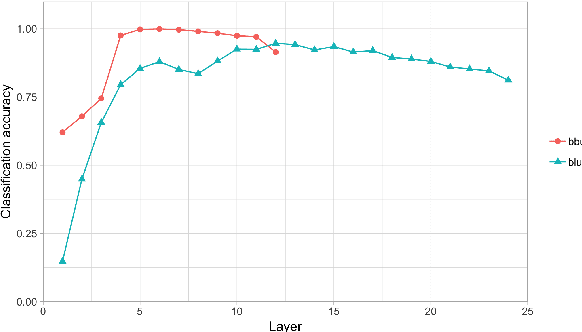
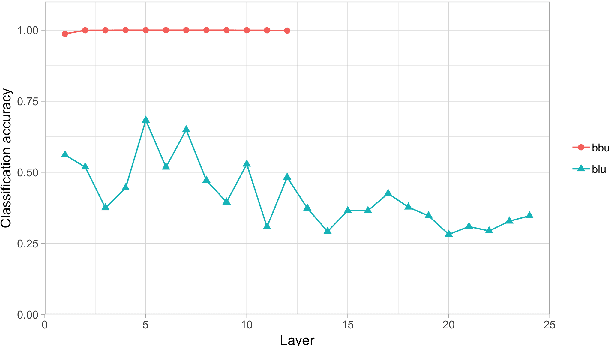
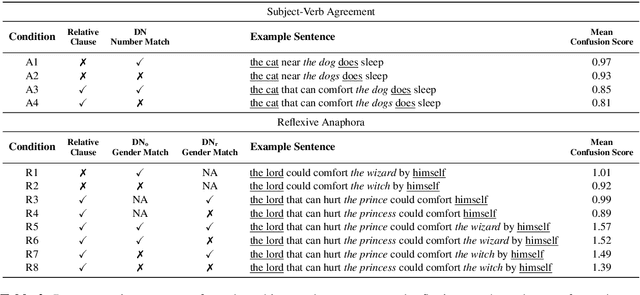
How and to what extent does BERT encode syntactically-sensitive hierarchical information or positionally-sensitive linear information? Recent work has shown that contextual representations like BERT perform well on tasks that require sensitivity to linguistic structure. We present here two studies which aim to provide a better understanding of the nature of BERT's representations. The first of these focuses on the identification of structurally-defined elements using diagnostic classifiers, while the second explores BERT's representation of subject-verb agreement and anaphor-antecedent dependencies through a quantitative assessment of self-attention vectors. In both cases, we find that BERT encodes positional information about word tokens well on its lower layers, but switches to a hierarchically-oriented encoding on higher layers. We conclude then that BERT's representations do indeed model linguistically relevant aspects of hierarchical structure, though they do not appear to show the sharp sensitivity to hierarchical structure that is found in human processing of reflexive anaphora.