 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Machine Learning Problems
Jul 02, 2021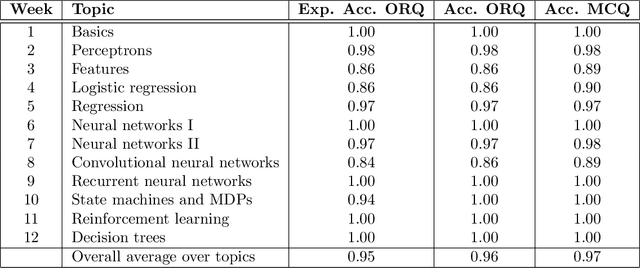

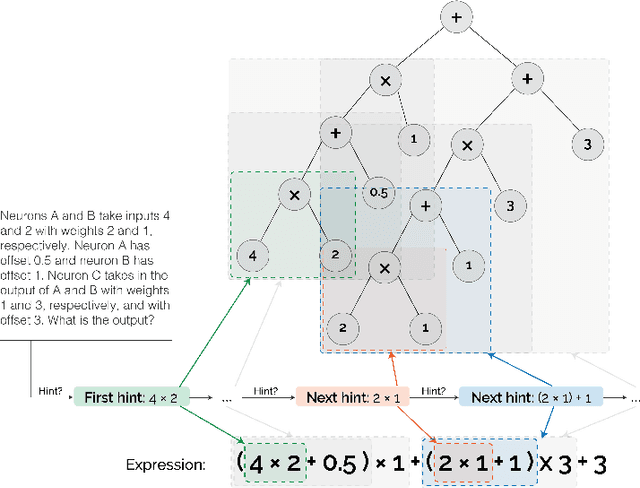
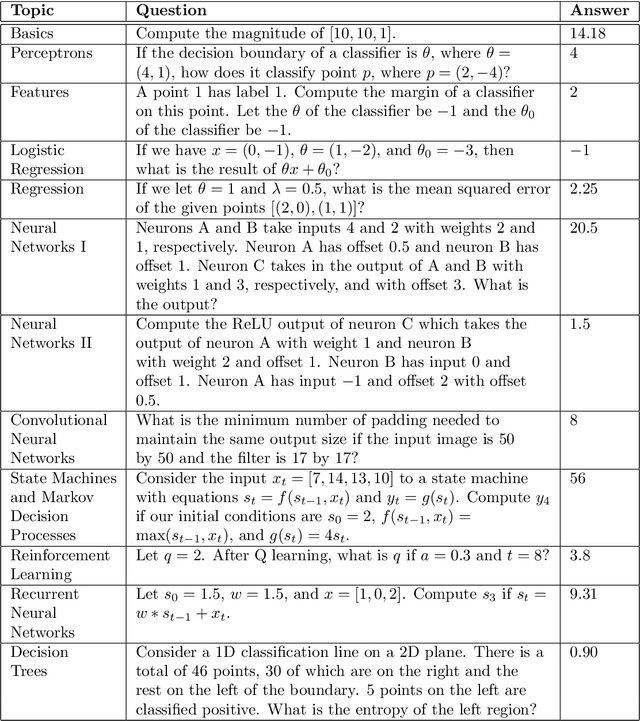
Can a machine learn Machine Learning? This work trains a machine learning model to solve machine learning problems from a University undergraduate level course. We generate a new training set of questions and answers consisting of course exercises, homework, and quiz questions from MIT's 6.036 Introduction to Machine Learning course and train a machine learning model to answer these questions. Our system demonstrates an overall accuracy of 96% for open-response questions and 97% for multiple-choice questions, compared with MIT students' average of 93%, achieving grade A performance in the course, all in real-time. Questions cover all 12 topics taught in the course, excluding coding questions or questions with images. Topics include: (i) basic machine learning principles; (ii) perceptrons; (iii) feature extraction and selection; (iv) logistic regression; (v) regression; (vi) neural networks; (vii) advanced neural networks; (viii) convolutional neural networks; (ix) recurrent neural networks; (x) state machines and MDPs; (xi) reinforcement learning; and (xii) decision trees. Our system uses Transformer models within an encoder-decoder architecture with graph and tree representations. An important aspect of our approach is a data-augmentation scheme for generating new example problems. We also train a machine learning model to generate problem hints. Thus, our system automatically generates new questions across topics, answers both open-response questions and multiple-choice questions, classifies problems, and generates problem hints, pushing the envelope of AI for STEM education.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020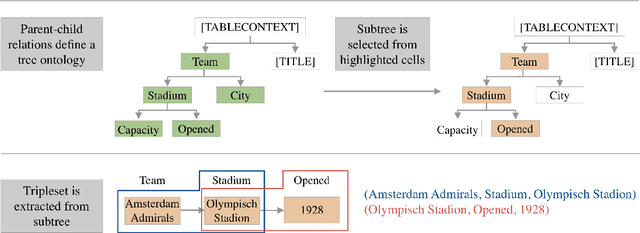
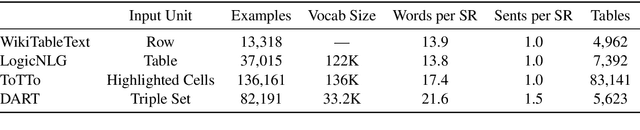
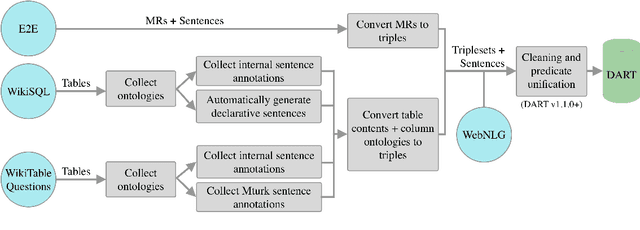
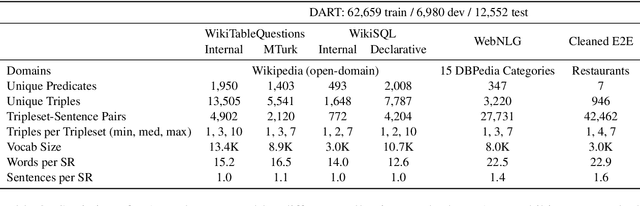
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.