 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydraSum: Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models
Nov 03, 2021
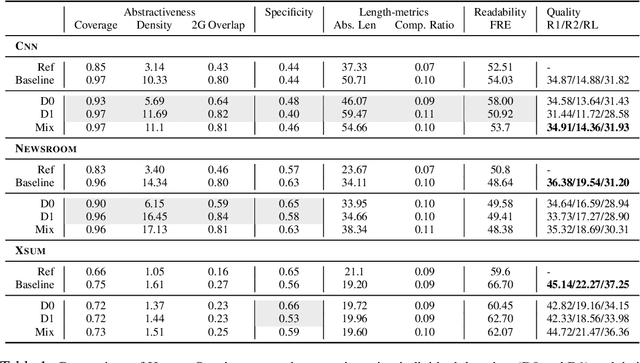
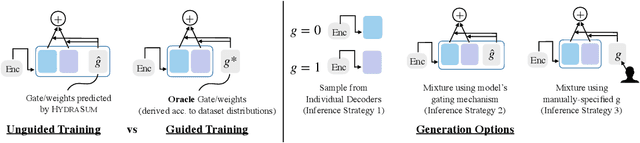

Existing abstractive summarization models lack explicit control mechanisms that would allow users to influence the stylistic features of the model outputs. This results in generating generic summaries that do not cater to the users needs or preferences. To address this issue we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models, e.g. BART, to a mixture-of-experts version consisting of multiple decoders. Our proposed model encourages each expert, i.e. decoder, to learn and generate stylistically-distinct summaries along dimensions such as abstractiveness, length, specificity, and others. At each time step, HydraSum employs a gating mechanism that decides the contribution of each individual decoder to the next token's output probability distribution. Through experiments on three summarization datasets (CNN, Newsroom, XSum), we demonstrate that this gating mechanism automatically learns to assign contrasting summary styles to different HydraSum decoders under the standard training objective without the need for additional supervision. We further show that a guided version of the training process can explicitly govern which summary style is partitioned between decoders, e.g. high abstractiveness vs. low abstractiveness or high specificity vs. low specificity, and also increase the stylistic-difference between individual decoders. Finally, our experiments demonstrate that our decoder framework is highly flexible: during inference, we can sample from individual decoders or mixtures of different subsets of the decoders to yield a diverse set of summaries and enforce single- and multi-style control over summary generation.
MoFE: Mixture of Factual Experts for Controlling Hallucinations in Abstractive Summarization
Oct 14, 2021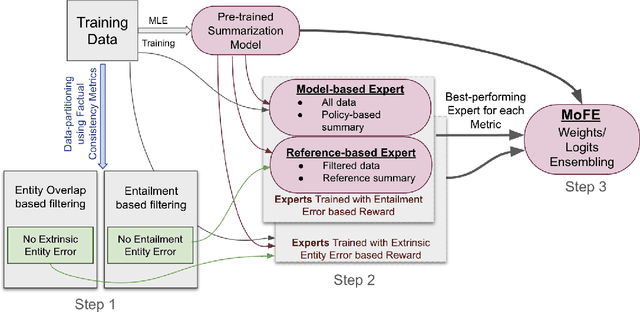
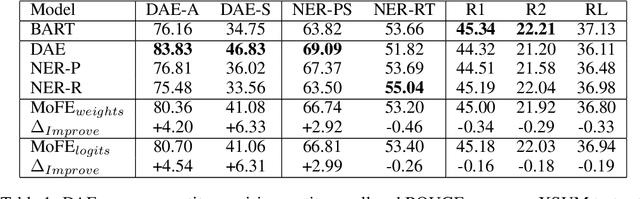
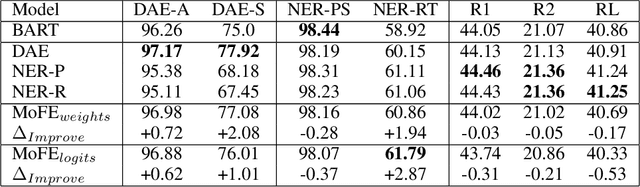
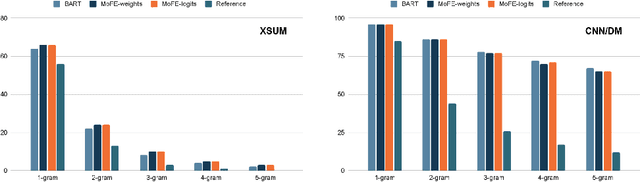
Neural abstractive summarization models are susceptible to generating factually inconsistent content, a phenomenon known as hallucination. This limits the usability and adoption of these systems in real-world applications. To reduce the presence of hallucination, we propose the Mixture of Factual Experts (MoFE) model, which combines multiple summarization experts that each target a specific type of error. We train our experts using reinforcement learning (RL) to minimize the error defined by two factual consistency metrics: entity overlap and dependency arc entailment. We construct MoFE by combining the experts using two ensembling strategies (weights and logits) and evaluate them on two summarization datasets (XSUM and CNN/DM). Our experiments on BART models show that the MoFE improves performance according to both entity overlap and dependency arc entailment, without a significant performance drop on standard ROUGE metrics. The performance improvement also transfers to unseen factual consistency metrics, such as question answer-based factuality evaluation metric and BERTScore precision with respect to the source document.
SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization
Apr 15, 2021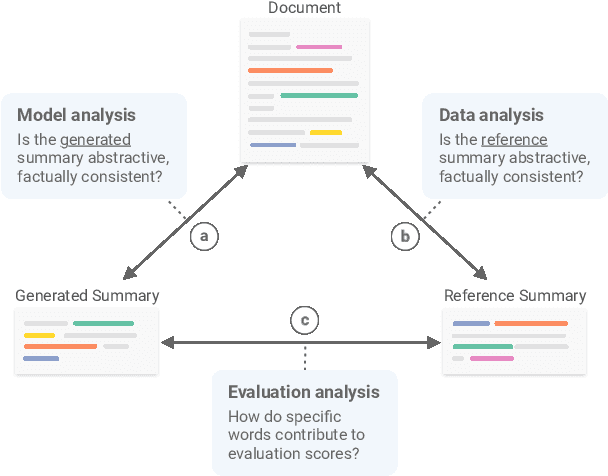
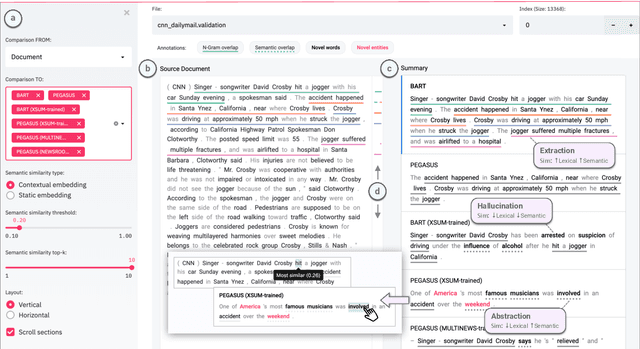
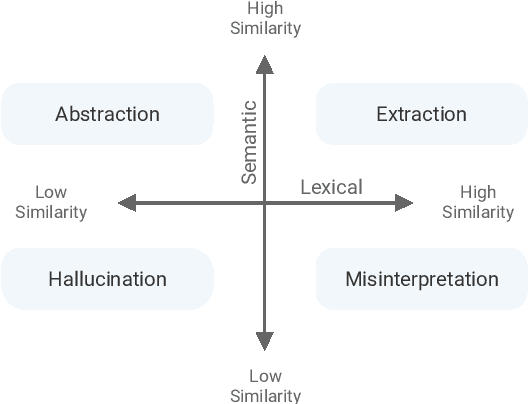

Novel neural architectures, training strategies, and the availability of large-scale corpora haven been the driving force behind recent progress in abstractive text summarization. However, due to the black-box nature of neural models, uninformative evaluation metrics, and scarce tooling for model and data analysis, the true performance and failure modes of summarization models remain largely unknown. To address this limitation, we introduce SummVis, an open-source tool for visualizing abstractive summaries that enables fine-grained analysis of the models, data, and evaluation metrics associated with text summarization. Through its lexical and semantic visualizations, the tools offers an easy entry point for in-depth model prediction exploration across important dimensions such as factual consistency or abstractiveness. The tool together with several pre-computed model outputs is available at https://github.com/robustness-gym/summvis.
FastIF: Scalable Influence Functions for Efficient Model Interpretation and Debugging
Dec 31, 2020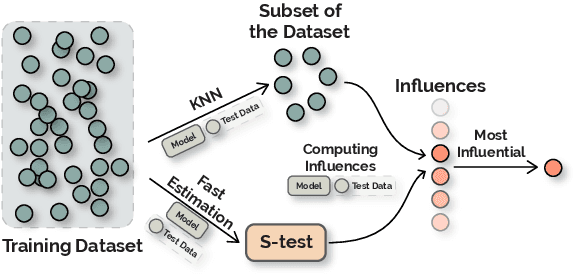

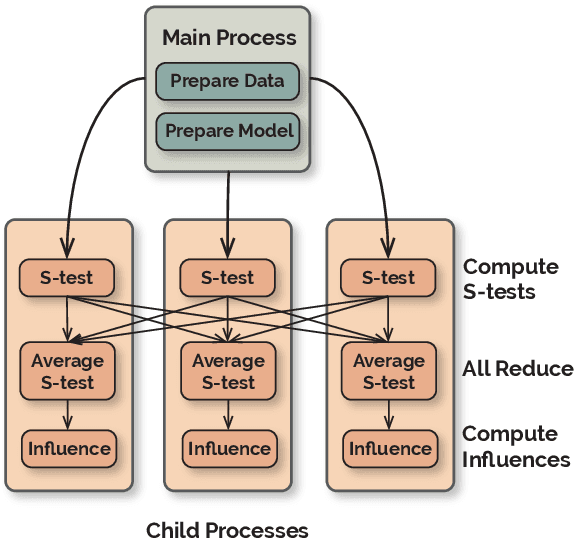
Influence functions approximate the 'influences' of training data-points for test predictions and have a wide variety of applications. Despite the popularity, their computational cost does not scale well with model and training data size. We present FastIF, a set of simple modifications to influence functions that significantly improves their run-time. We use k-Nearest Neighbors (kNN) to narrow the search space down to a subset of good candidate data points, identify the configurations that best balance the speed-quality trade-off in estimating the inverse Hessian-vector product, and introduce a fast parallel variant. Our proposed method achieves about 80x speedup while being highly correlated with the original influence values. With the availability of the fast influence functions, we demonstrate their usefulness in four applications. First, we examine whether influential data-points can 'explain' test time behavior using the framework of simulatability. Second, we visualize the influence interactions between training and test data-points. Third, we show that we can correct model errors by additional fine-tuning on certain influential data-points, improving the accuracy of a trained MNLI model by 2.6% on the HANS challenge set using a small number of gradient updates. Finally, we experiment with a data-augmentation setup where we use influence functions to search for new data-points unseen during training to improve model performance. Overall, our fast influence functions can be efficiently applied to large models and datasets, and our experiments demonstrate the potential of influence functions in model interpretation and correcting model errors. Code is available at https://github.com/salesforce/fast-influence-functions
Profile Prediction: An Alignment-Based Pre-Training Task for Protein Sequence Models
Dec 01, 2020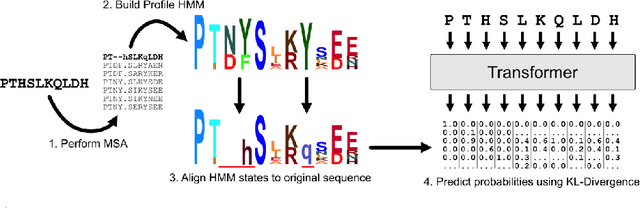
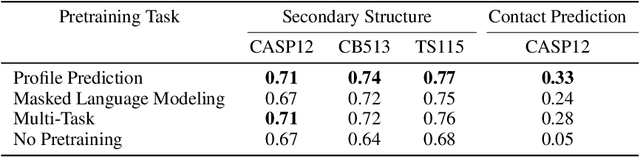
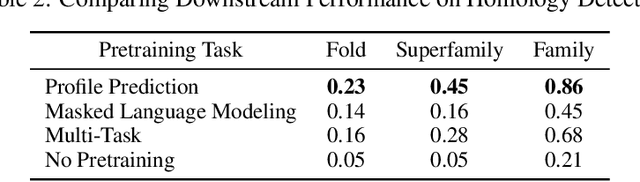
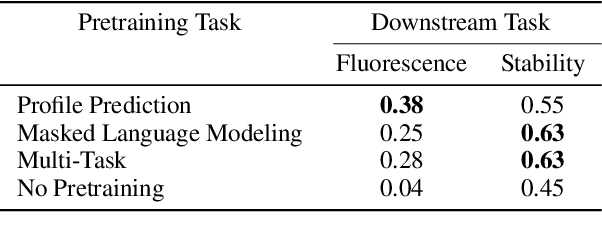
For protein sequence datasets, unlabeled data has greatly outpaced labeled data due to the high cost of wet-lab characterization. Recent deep-learning approaches to protein prediction have shown that pre-training on unlabeled data can yield useful representations for downstream tasks. However, the optimal pre-training strategy remains an open question. Instead of strictly borrowing from natural language processing (NLP) in the form of masked or autoregressive language modeling, we introduce a new pre-training task: directly predicting protein profiles derived from multiple sequence alignments. Using a set of five, standardized downstream tasks for protein models, we demonstrate that our pre-training task along with a multi-task objective outperforms masked language modeling alone on all five tasks. Our results suggest that protein sequence models may benefit from leveraging biologically-inspired inductive biases that go beyond existing language modeling techniques in NLP.
Explaining and Improving Model Behavior with k Nearest Neighbor Representations
Oct 18, 2020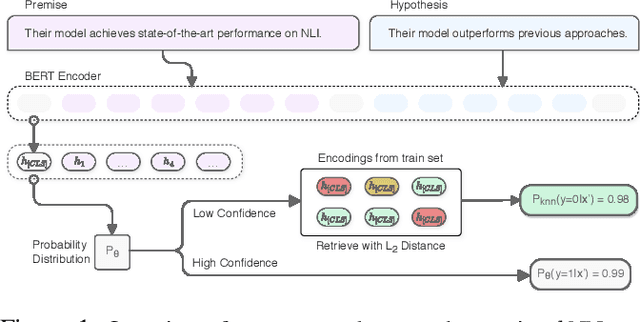



Interpretability techniques in NLP have mainly focused on understanding individual predictions using attention visualization or gradient-based saliency maps over tokens. We propose using k nearest neighbor (kNN) representations to identify training examples responsible for a model's predictions and obtain a corpus-level understanding of the model's behavior. Apart from interpretability, we show that kNN representations are effective at uncovering learned spurious associations, identifying mislabeled examples, and improving the fine-tuned model's performance. We focus on Natural Language Inference (NLI) as a case study and experiment with multiple datasets. Our method deploys backoff to kNN for BERT and RoBERTa on examples with low model confidence without any update to the model parameters. Our results indicate that the kNN approach makes the finetuned model more robust to adversarial inputs.
Explaining Creative Artifacts
Oct 14, 2020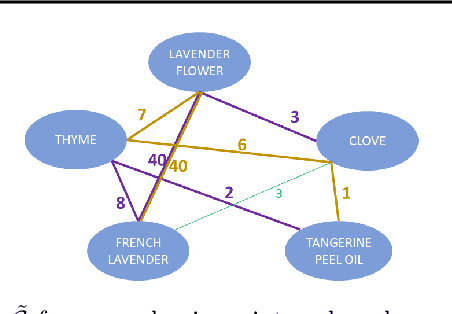
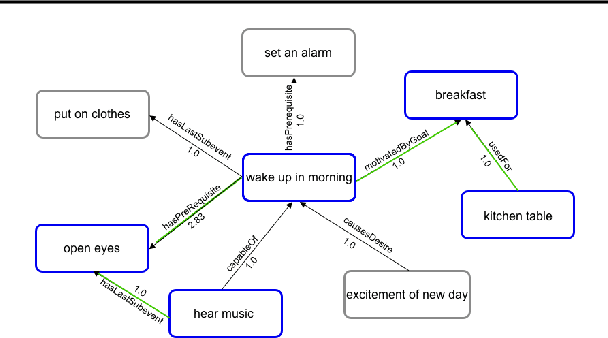
Human creativity is often described as the mental process of combining associative elements into a new form, but emerging computational creativity algorithms may not operate in this manner. Here we develop an inverse problem formulation to deconstruct the products of combinatorial and compositional creativity into associative chains as a form of post-hoc interpretation that matches the human creative process. In particular, our formulation is structured as solving a traveling salesman problem through a knowledge graph of associative elements. We demonstrate our approach using an example in explaining culinary computational creativity where there is an explicit semantic structure, and two examples in language generation where we either extract explicit concepts that map to a knowledge graph or we consider distances in a word embedding space. We close by casting the length of an optimal traveling salesman path as a measure of novelty in creativity.
ReviewRobot: Explainable Paper Review Generation based on Knowledge Synthesis
Oct 13, 2020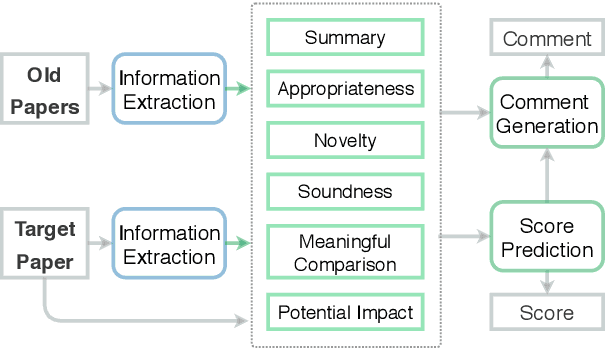
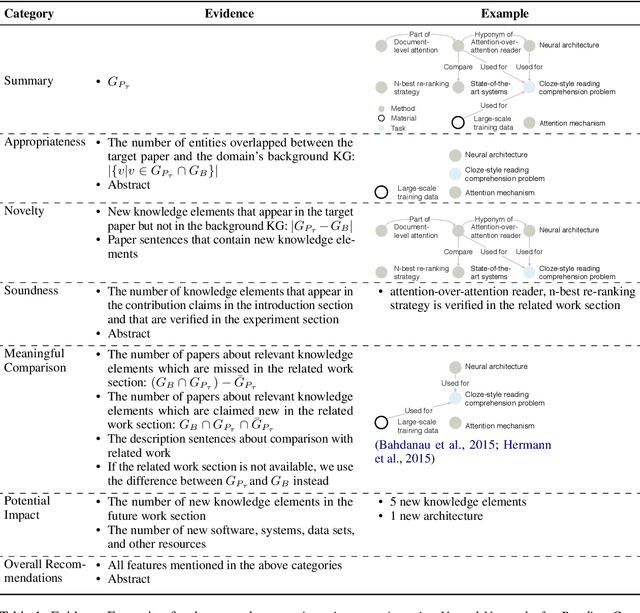
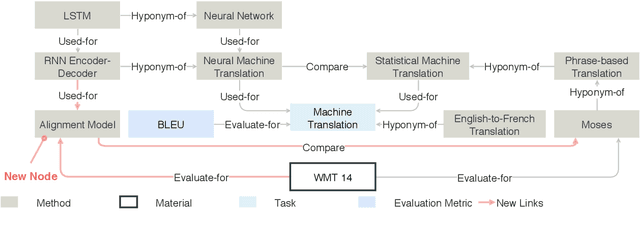

To assist human review process, we build a novel ReviewRobot to automatically assign a review score and write comments for multiple categories. A good review needs to be knowledgeable, namely that the comments should be constructive and informative to help improve the paper; and explainable by providing detailed evidence. ReviewRobot achieves these goals via three steps: (1) We perform domain-specific Information Extraction to construct a knowledge graph (KG) from the target paper under review, a related work KG from the papers cited by the target paper, and a background KG from a large collection of previous papers in the domain. (2) By comparing these three KGs we predict a review score and detailed structured knowledge as evidence for each review category. (3) We carefully select and generalize human review sentences into templates, and apply these templates to transform the review scores and evidence into natural language comments. Experimental results show that our review score predictor reaches 71.4-100% accuracy. Human assessment by domain experts shows that 41.7%-70.5% of the comments generated by ReviewRobot are valid and constructive, and better than human-written ones 20% of the time. Thus, ReviewRobot can serve as an assistant for paper reviewers, program chairs and authors.
Universal Natural Language Processing with Limited Annotations: Try Few-shot Textual Entailment as a Start
Oct 06, 2020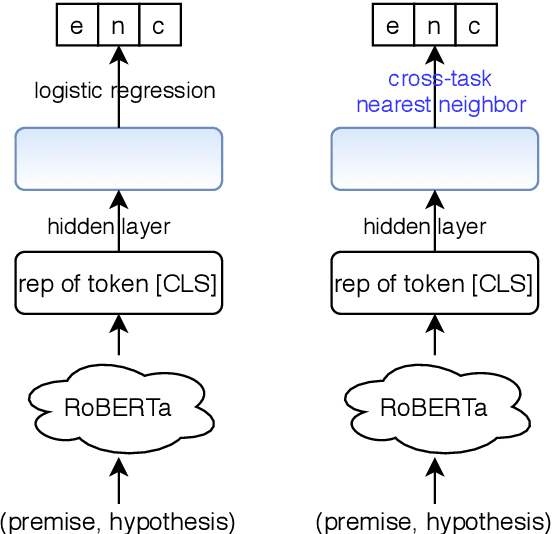
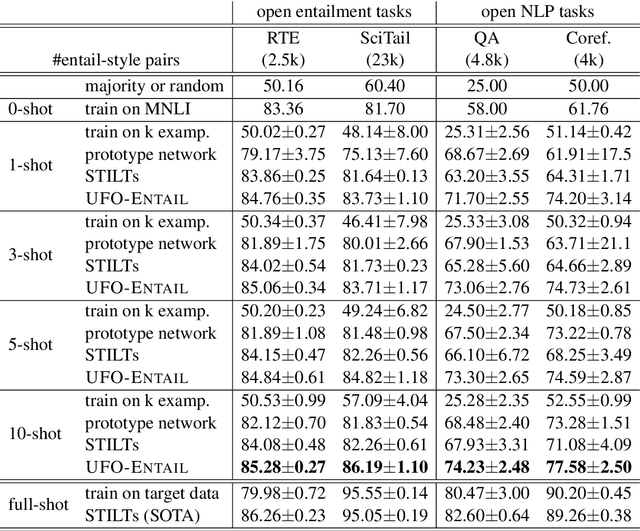
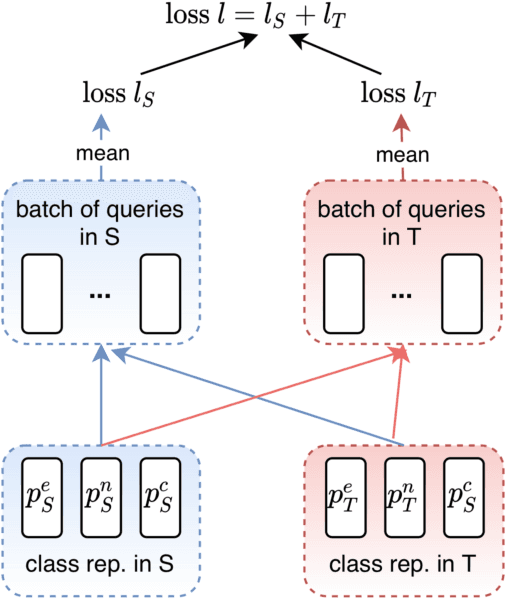
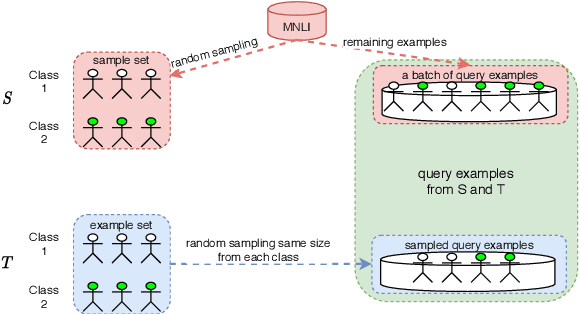
A standard way to address different NLP problems is by first constructing a problem-specific dataset, then building a model to fit this dataset. To build the ultimate artificial intelligence, we desire a single machine that can handle diverse new problems, for which task-specific annotations are limited. We bring up textual entailment as a unified solver for such NLP problems. However, current research of textual entailment has not spilled much ink on the following questions: (i) How well does a pretrained textual entailment system generalize across domains with only a handful of domain-specific examples? and (ii) When is it worth transforming an NLP task into textual entailment? We argue that the transforming is unnecessary if we can obtain rich annotations for this task. Textual entailment really matters particularly when the target NLP task has insufficient annotations. Universal NLP can be probably achieved through different routines. In this work, we introduce Universal Few-shot textual Entailment (UFO-Entail). We demonstrate that this framework enables a pretrained entailment model to work well on new entailment domains in a few-shot setting, and show its effectiveness as a unified solver for several downstream NLP tasks such as question answering and coreference resolution when the end-task annotations are limited. Code: https://github.com/salesforce/UniversalFewShotNLP
GeDi: Generative Discriminator Guided Sequence Generation
Sep 14, 2020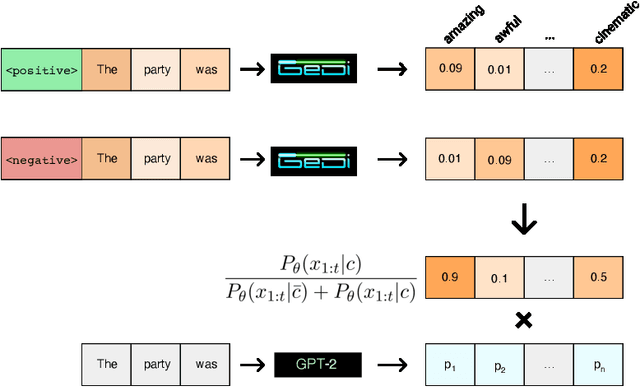
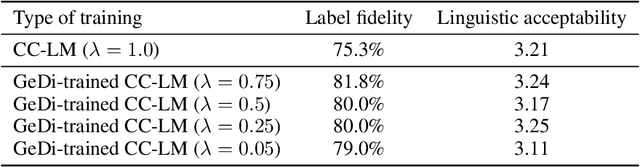
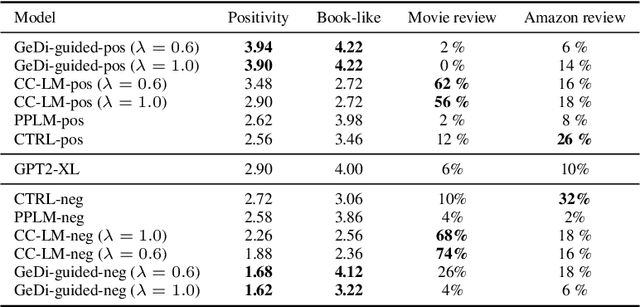
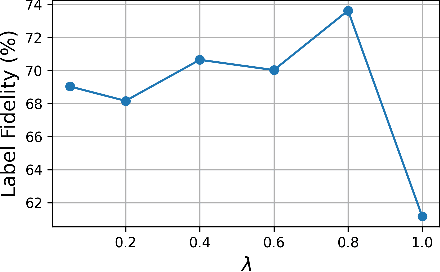
Class-conditional language models (CC-LMs) can be used to generate natural language with specific attributes, such as style or sentiment, by conditioning on an attribute label, or control code. However, we find that these models struggle to control generation when applied to out-of-domain prompts or unseen control codes. To overcome these limitations, we propose generative discriminator (GeDi) guided contrastive generation, which uses CC-LMs as generative discriminators (GeDis) to efficiently guide generation from a (potentially much larger) LM towards a desired attribute. In our human evaluation experiments, we show that GeDis trained for sentiment control on movie reviews are able to control the tone of book text. We also demonstrate that GeDis are able to detoxify generation and control topic while maintaining the same level of linguistic acceptability as direct generation from GPT-2 (1.5B parameters). Lastly, we show that a GeDi trained on only 4 topics can generalize to new control codes from word embeddings, allowing it to guide generation towards wide array of topics.