 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Negative Samples for Sequential Recommendation
Aug 07, 2022To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Modeling Multi-hop Question Answering as Single Sequence Prediction
May 18, 2022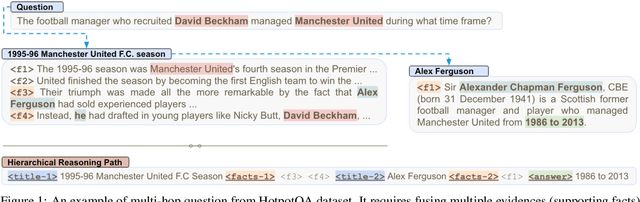
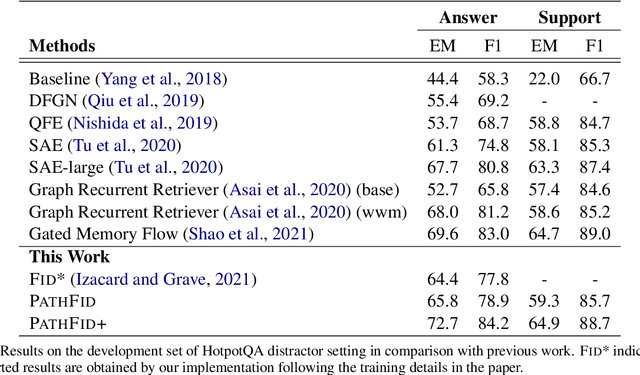
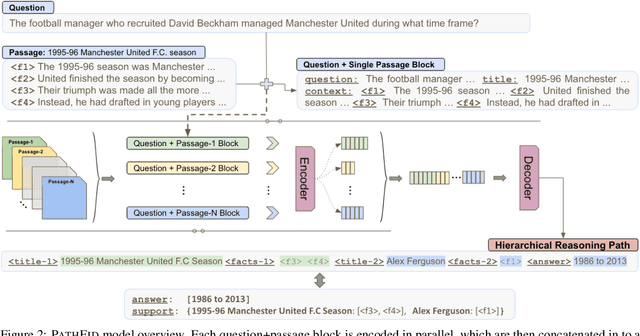
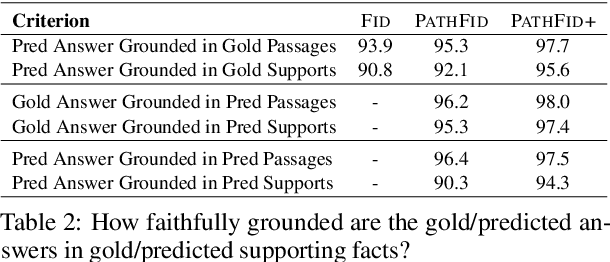
Fusion-in-decoder (Fid) (Izacard and Grave, 2020) is a generative question answering (QA) model that leverages passage retrieval with a pre-trained transformer and pushed the state of the art on single-hop QA. However, the complexity of multi-hop QA hinders the effectiveness of the generative QA approach. In this work, we propose a simple generative approach (PathFid) that extends the task beyond just answer generation by explicitly modeling the reasoning process to resolve the answer for multi-hop questions. By linearizing the hierarchical reasoning path of supporting passages, their key sentences, and finally the factoid answer, we cast the problem as a single sequence prediction task. To facilitate complex reasoning with multiple clues, we further extend the unified flat representation of multiple input documents by encoding cross-passage interactions. Our extensive experiments demonstrate that PathFid leads to strong performance gains on two multi-hop QA datasets: HotpotQA and IIRC. Besides the performance gains, PathFid is more interpretable, which in turn yields answers that are more faithfully grounded to the supporting passages and facts compared to the baseline Fid model.
Combining Data-driven Supervision with Human-in-the-loop Feedback for Entity Resolution
Nov 20, 2021

The distribution gap between training datasets and data encountered in production is well acknowledged. Training datasets are often constructed over a fixed period of time and by carefully curating the data to be labeled. Thus, training datasets may not contain all possible variations of data that could be encountered in real-world production environments. Tasked with building an entity resolution system - a model that identifies and consolidates data points that represent the same person - our first model exhibited a clear training-production performance gap. In this case study, we discuss our human-in-the-loop enabled, data-centric solution to closing the training-production performance divergence. We conclude with takeaways that apply to data-centric learning at large.
Unsupervised Paraphrase Generation via Dynamic Blocking
Oct 24, 2020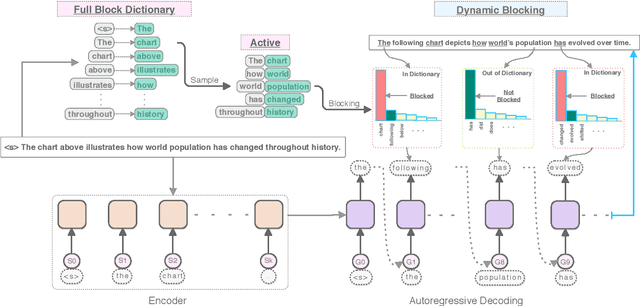
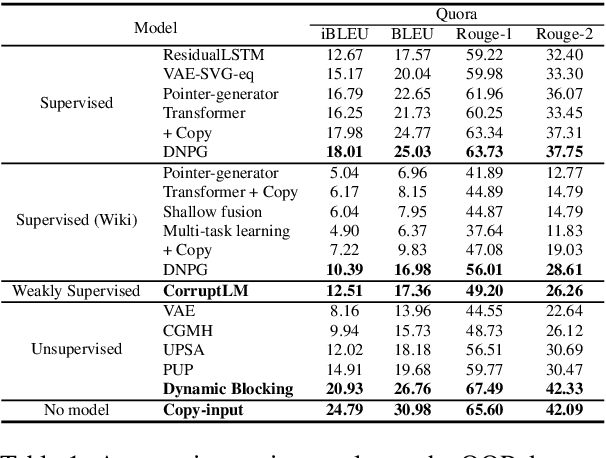
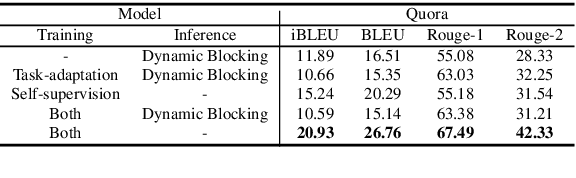
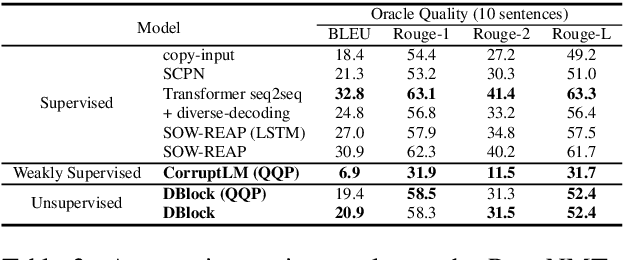
We propose Dynamic Blocking, a decoding algorithm which enables large-scale pretrained autoregressive models (such as BART, T5, GPT-2 and XLNet) to generate high-quality paraphrases in an unsupervised setting. In order to obtain an alternative surface form, whenever the language model emits a token that is present in the source sequence, we prevent the model from generating the subsequent source token for the next time step. We show that our approach achieves state-of-the-art results on benchmark datasets when compared to previous unsupervised approaches, and is even comparable with strong supervised, in-domain models. We also propose a new automatic metric based on self-BLEU and BERTscore which not only discourages the model from copying the input through, but also evaluates text similarity based on distributed representations, hence avoiding reliance on exact keyword matching. In addition, we demonstrate that our model generalizes across languages without any additional training.
GeDi: Generative Discriminator Guided Sequence Generation
Sep 14, 2020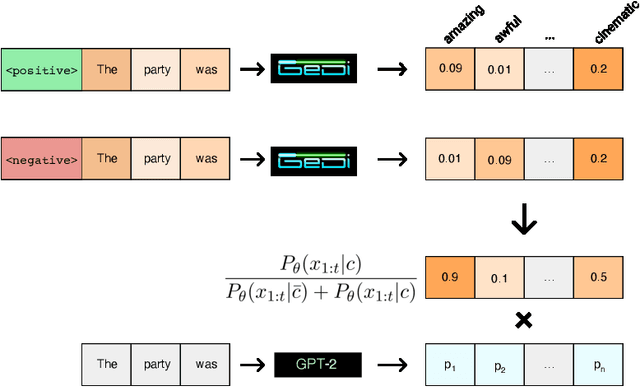
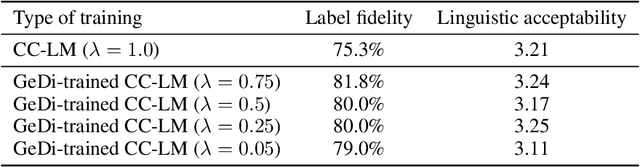
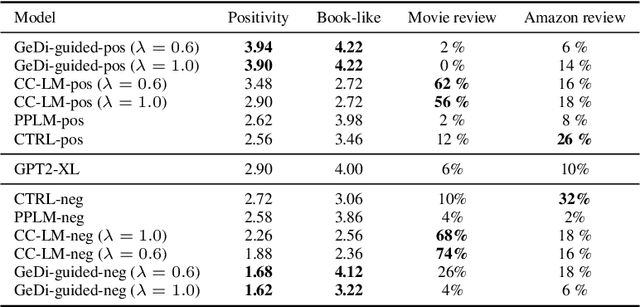
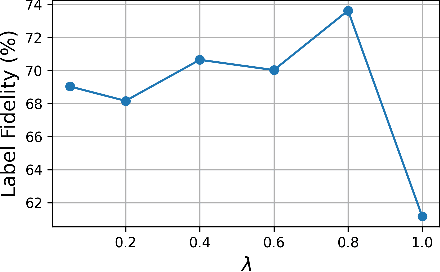
Class-conditional language models (CC-LMs) can be used to generate natural language with specific attributes, such as style or sentiment, by conditioning on an attribute label, or control code. However, we find that these models struggle to control generation when applied to out-of-domain prompts or unseen control codes. To overcome these limitations, we propose generative discriminator (GeDi) guided contrastive generation, which uses CC-LMs as generative discriminators (GeDis) to efficiently guide generation from a (potentially much larger) LM towards a desired attribute. In our human evaluation experiments, we show that GeDis trained for sentiment control on movie reviews are able to control the tone of book text. We also demonstrate that GeDis are able to detoxify generation and control topic while maintaining the same level of linguistic acceptability as direct generation from GPT-2 (1.5B parameters). Lastly, we show that a GeDi trained on only 4 topics can generalize to new control codes from word embeddings, allowing it to guide generation towards wide array of topics.
Mirostat: A Perplexity-Controlled Neural Text Decoding Algorithm
Jul 29, 2020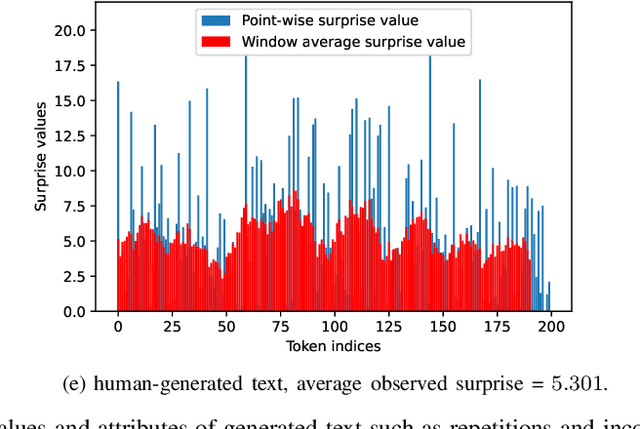
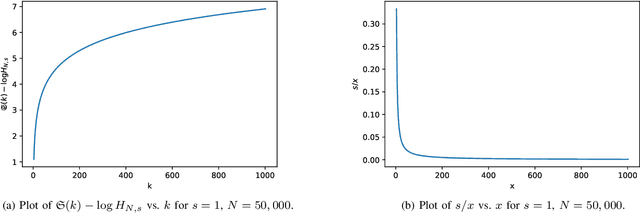
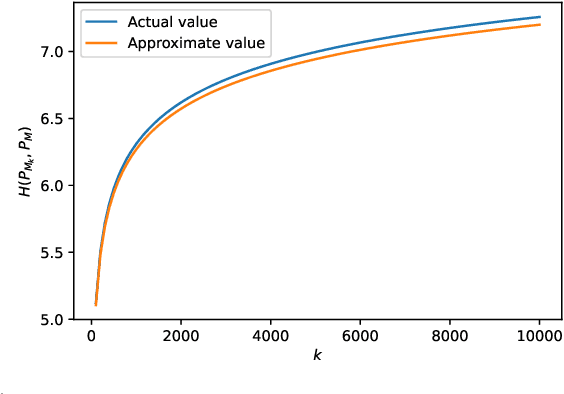
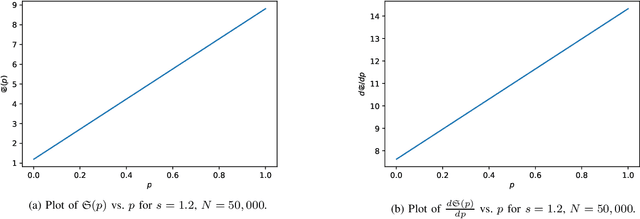
Neural text decoding is important for generating high-quality texts using language models. To generate high-quality text, popular decoding algorithms like top-k, top-p (nucleus), and temperature-based sampling truncate or distort the unreliable low probability tail of the language model. Though these methods generate high-quality text after parameter tuning, they are ad hoc. Not much is known about the control they provide over the statistics of the output, which is important since recent reports show text quality is highest for a specific range of likelihoods. Here, first we provide a theoretical analysis of perplexity in top-k, top-p, and temperature sampling, finding that cross-entropy behaves approximately linearly as a function of p in top-p sampling whereas it is a nonlinear function of k in top-k sampling, under Zipfian statistics. We use this analysis to design a feedback-based adaptive top-k text decoding algorithm called mirostat that generates text (of any length) with a predetermined value of perplexity, and thereby high-quality text without any tuning. Experiments show that for low values of k and p in top-k and top-p sampling, perplexity drops significantly with generated text length, which is also correlated with excessive repetitions in the text (the boredom trap). On the other hand, for large values of k and p, we find that perplexity increases with generated text length, which is correlated with incoherence in the text (confusion trap). Mirostat avoids both traps: experiments show that cross-entropy has a near-linear relation with repetition in generated text. This relation is almost independent of the sampling method but slightly dependent on the model used. Hence, for a given language model, control over perplexity also gives control over repetitions.
ProGen: Language Modeling for Protein Generation
Mar 08, 2020Generative modeling for protein engineering is key to solving fundamental problems in synthetic biology, medicine, and material science. We pose protein engineering as an unsupervised sequence generation problem in order to leverage the exponentially growing set of proteins that lack costly, structural annotations. We train a 1.2B-parameter language model, ProGen, on ~280M protein sequences conditioned on taxonomic and keyword tags such as molecular function and cellular component. This provides ProGen with an unprecedented range of evolutionary sequence diversity and allows it to generate with fine-grained control as demonstrated by metrics based on primary sequence similarity, secondary structure accuracy, and conformational energy.
Limits of Detecting Text Generated by Large-Scale Language Models
Feb 09, 2020Some consider large-scale language models that can generate long and coherent pieces of text as dangerous, since they may be used in misinformation campaigns. Here we formulate large-scale language model output detection as a hypothesis testing problem to classify text as genuine or generated. We show that error exponents for particular language models are bounded in terms of their perplexity, a standard measure of language generation performance. Under the assumption that human language is stationary and ergodic, the formulation is extended from considering specific language models to considering maximum likelihood language models, among the class of k-order Markov approximations; error probabilities are characterized. Some discussion of incorporating semantic side information is also given.
Global Capacity Measures for Deep ReLU Networks via Path Sampling
Oct 22, 2019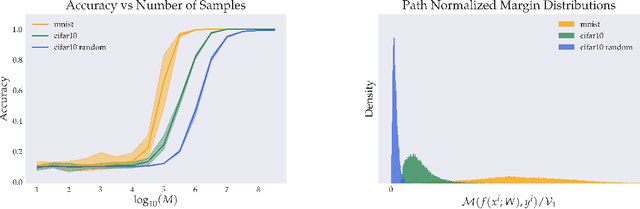
Classical results on the statistical complexity of linear models have commonly identified the norm of the weights $\|w\|$ as a fundamental capacity measure. Generalizations of this measure to the setting of deep networks have been varied, though a frequently identified quantity is the product of weight norms of each layer. In this work, we show that for a large class of networks possessing a positive homogeneity property, similar bounds may be obtained instead in terms of the norm of the product of weights. Our proof technique generalizes a recently proposed sampling argument, which allows us to demonstrate the existence of sparse approximants of positive homogeneous networks. This yields covering number bounds, which can be converted to generalization bounds for multi-class classification that are comparable to, and in certain cases improve upon, existing results in the literature. Finally, we investigate our sampling procedure empirically, which yields results consistent with our theory.