 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Energy-based Model Training for Better Calibrated Natural Language Understanding Models
Jan 18, 2021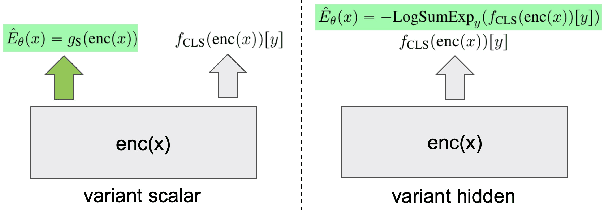
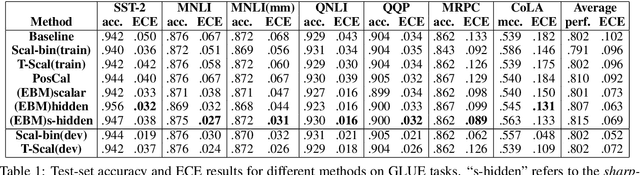
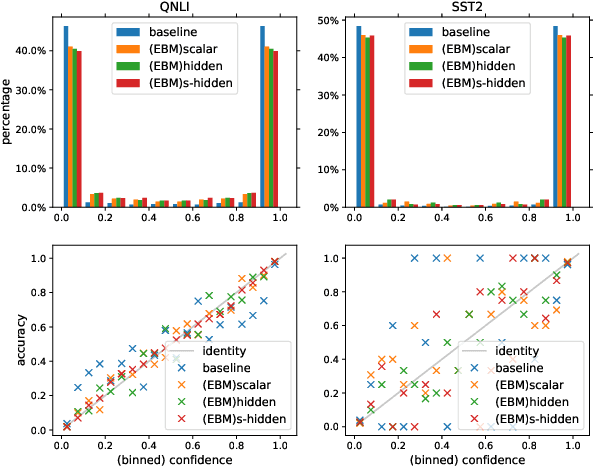
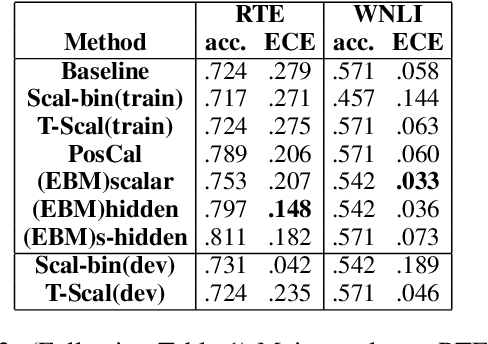
In this work, we explore joint energy-based model (EBM) training during the finetuning of pretrained text encoders (e.g., Roberta) for natural language understanding (NLU) tasks. Our experiments show that EBM training can help the model reach a better calibration that is competitive to strong baselines, with little or no loss in accuracy. We discuss three variants of energy functions (namely scalar, hidden, and sharp-hidden) that can be defined on top of a text encoder, and compare them in experiments. Due to the discreteness of text data, we adopt noise contrastive estimation (NCE) to train the energy-based model. To make NCE training more effective, we train an auto-regressive noise model with the masked language model (MLM) objective.
CTRLsum: Towards Generic Controllable Text Summarization
Dec 08, 2020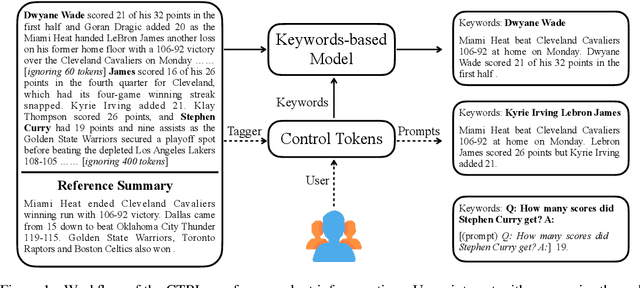
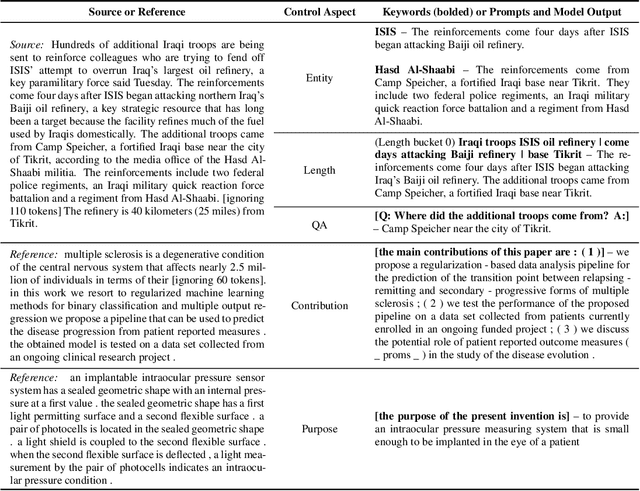
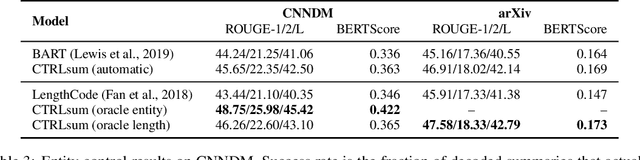
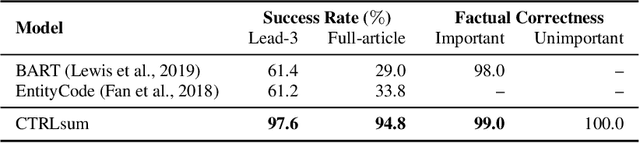
Current summarization systems yield generic summaries that are disconnected from users' preferences and expectations. To address this limitation, we present CTRLsum, a novel framework for controllable summarization. Our approach enables users to control multiple aspects of generated summaries by interacting with the summarization system through textual input in the form of a set of keywords or descriptive prompts. Using a single unified model, CTRLsum is able to achieve a broad scope of summary manipulation at inference time without requiring additional human annotations or pre-defining a set of control aspects during training. We quantitatively demonstrate the effectiveness of our approach on three domains of summarization datasets and five control aspects: 1) entity-centric and 2) length-controllable summarization, 3) contribution summarization on scientific papers, 4) invention purpose summarization on patent filings, and 5) question-guided summarization on news articles in a reading comprehension setting. Moreover, when used in a standard, uncontrolled summarization setting, CTRLsum achieves state-of-the-art results on the CNN/DailyMail dataset. Code and model checkpoints are available at https://github.com/salesforce/ctrl-sum
What's New? Summarizing Contributions in Scientific Literature
Nov 09, 2020
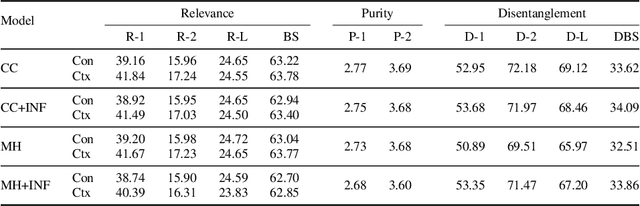

With thousands of academic articles shared on a daily basis, it has become increasingly difficult to keep up with the latest scientific findings. To overcome this problem, we introduce a new task of disentangled paper summarization, which seeks to generate separate summaries for the paper contributions and the context of the work, making it easier to identify the key findings shared in articles. For this purpose, we extend the S2ORC corpus of academic articles, which spans a diverse set of domains ranging from economics to psychology, by adding disentangled "contribution" and "context" reference labels. Together with the dataset, we introduce and analyze three baseline approaches: 1) a unified model controlled by input code prefixes, 2) a model with separate generation heads specialized in generating the disentangled outputs, and 3) a training strategy that guides the model using additional supervision coming from inbound and outbound citations. We also propose a comprehensive automatic evaluation protocol which reports the relevance, novelty, and disentanglement of generated outputs. Through a human study involving expert annotators, we show that in 79%, of cases our new task is considered more helpful than traditional scientific paper summarization.
Char2Subword: Extending the Subword Embedding Space from Pre-trained Models Using Robust Character Compositionality
Oct 24, 2020

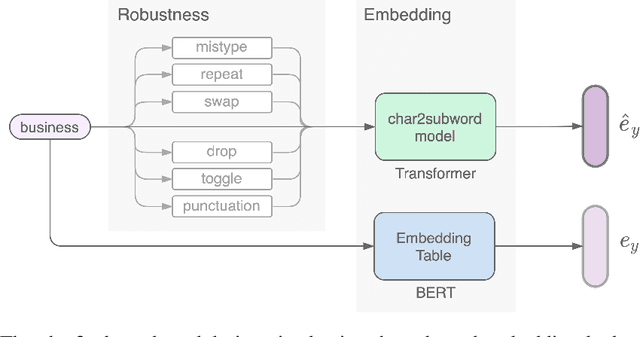
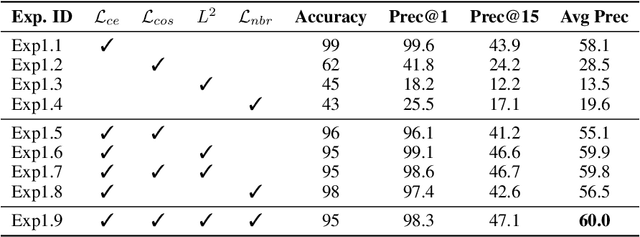
Byte-pair encoding (BPE) is a ubiquitous algorithm in the subword tokenization process of language models. BPE provides multiple benefits, such as handling the out-of-vocabulary problem and reducing vocabulary sparsity. However, this process is defined from the pre-training data statistics, making the tokenization on different domains susceptible to infrequent spelling sequences (e.g., misspellings as in social media or character-level adversarial attacks). On the other hand, pure character-level models, though robust to misspellings, often lead to unreasonably large sequence lengths and make it harder for the model to learn meaningful contiguous characters. To alleviate these challenges, we propose a character-based subword transformer module (char2subword) that learns the subword embedding table in pre-trained models like BERT. Our char2subword module builds representations from characters out of the subword vocabulary, and it can be used as a drop-in replacement of the subword embedding table. The module is robust to character-level alterations such as misspellings, word inflection, casing, and punctuation. We integrate it further with BERT through pre-training while keeping BERT transformer parameters fixed. We show our method's effectiveness by outperforming a vanilla multilingual BERT on the linguistic code-switching evaluation (LinCE) benchmark.
GeDi: Generative Discriminator Guided Sequence Generation
Sep 14, 2020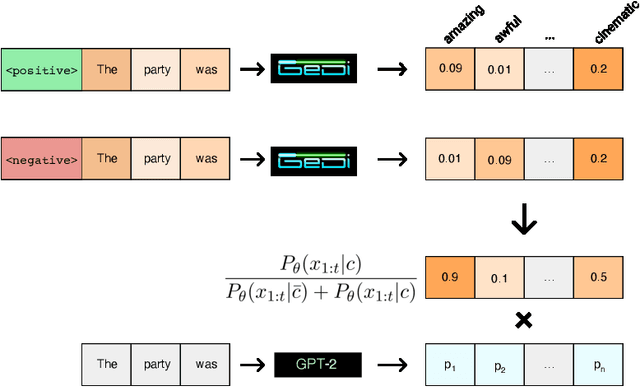
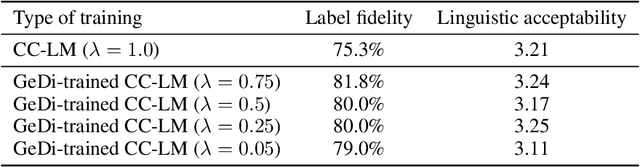
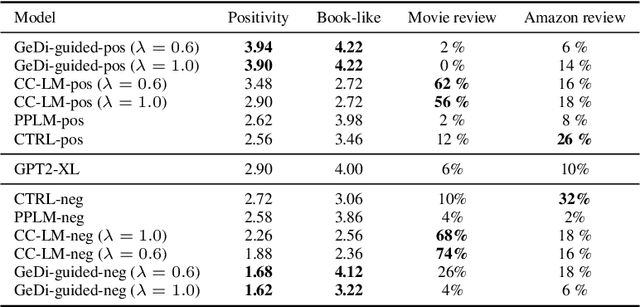
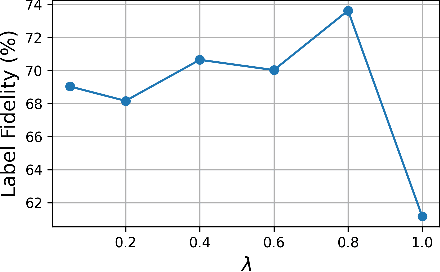
Class-conditional language models (CC-LMs) can be used to generate natural language with specific attributes, such as style or sentiment, by conditioning on an attribute label, or control code. However, we find that these models struggle to control generation when applied to out-of-domain prompts or unseen control codes. To overcome these limitations, we propose generative discriminator (GeDi) guided contrastive generation, which uses CC-LMs as generative discriminators (GeDis) to efficiently guide generation from a (potentially much larger) LM towards a desired attribute. In our human evaluation experiments, we show that GeDis trained for sentiment control on movie reviews are able to control the tone of book text. We also demonstrate that GeDis are able to detoxify generation and control topic while maintaining the same level of linguistic acceptability as direct generation from GPT-2 (1.5B parameters). Lastly, we show that a GeDi trained on only 4 topics can generalize to new control codes from word embeddings, allowing it to guide generation towards wide array of topics.
SummEval: Re-evaluating Summarization Evaluation
Jul 31, 2020



The scarcity of comprehensive up-to-date studies on evaluation metrics for text summarization and the lack of consensus regarding evaluation protocols continues to inhibit progress. We address the existing shortcomings of summarization evaluation methods along five dimensions: 1) we re-evaluate 12 automatic evaluation metrics in a comprehensive and consistent fashion using neural summarization model outputs along with expert and crowd-sourced human annotations, 2) we consistently benchmark 23 recent summarization models using the aforementioned automatic evaluation metrics, 3) we assemble the largest collection of summaries generated by models trained on the CNN/DailyMail news dataset and share it in a unified format, 4) we implement and share a toolkit that provides an extensible and unified API for evaluating summarization models across a broad range of automatic metrics, 5) we assemble and share the largest and most diverse, in terms of model types, collection of human judgments of model-generated summaries on the CNN/Daily Mail dataset annotated by both expert judges and crowd source workers. We hope that this work will help promote a more complete evaluation protocol for text summarization as well as advance research in developing evaluation metrics that better correlate with human judgements.
A Simple Language Model for Task-Oriented Dialogue
May 25, 2020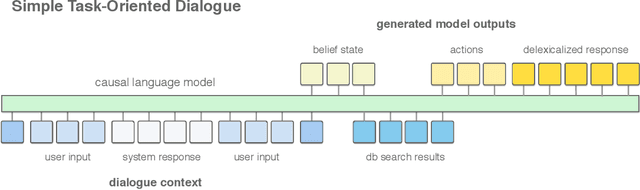


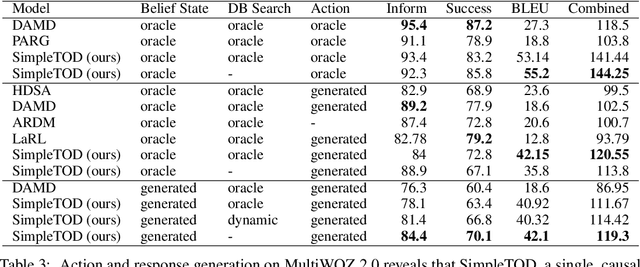
Task-oriented dialogue is often decomposed into three tasks: understanding user input, deciding actions, and generating a response. While such decomposition might suggest a dedicated model for each sub-task, we find a simple, unified approach leads to state-of-the-art performance on the MultiWOZ dataset. SimpleTOD is a simple approach to task-oriented dialogue that uses a single causal language model trained on all sub-tasks recast as a single sequence prediction problem. This allows SimpleTOD to fully leverage transfer learning from pre-trained, open domain, causal language models such as GPT-2. SimpleTOD improves over the prior state-of-the-art by 0.49 points in joint goal accuracy for dialogue state tracking. More impressively, SimpleTOD also improves the main metrics used to evaluate action decisions and response generation in an end-to-end setting for task-oriented dialog systems: inform rate by 8.1 points, success rate by 9.7 points, and combined score by 7.2 points.
Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
May 03, 2020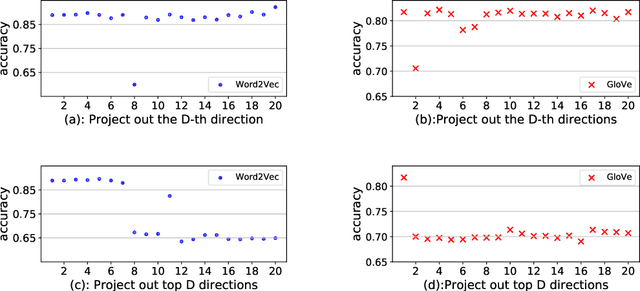
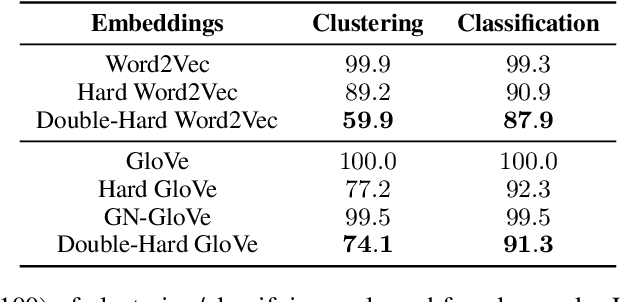
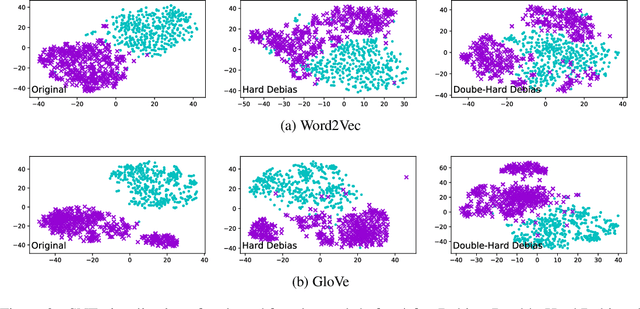
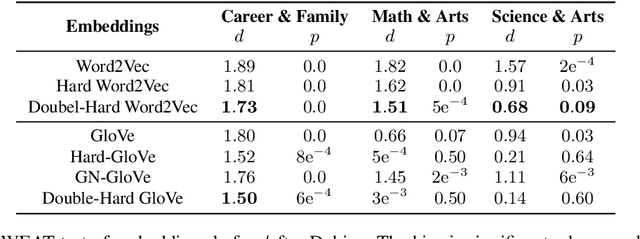
Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. Some commonly adopted debiasing approaches, including the seminal Hard Debias algorithm, apply post-processing procedures that project pre-trained word embeddings into a subspace orthogonal to an inferred gender subspace. We discover that semantic-agnostic corpus regularities such as word frequency captured by the word embeddings negatively impact the performance of these algorithms. We propose a simple but effective technique, Double Hard Debias, which purifies the word embeddings against such corpus regularities prior to inferring and removing the gender subspace. Experiments on three bias mitigation benchmarks show that our approach preserves the distributional semantics of the pre-trained word embeddings while reducing gender bias to a significantly larger degree than prior approaches.
ProGen: Language Modeling for Protein Generation
Mar 08, 2020Generative modeling for protein engineering is key to solving fundamental problems in synthetic biology, medicine, and material science. We pose protein engineering as an unsupervised sequence generation problem in order to leverage the exponentially growing set of proteins that lack costly, structural annotations. We train a 1.2B-parameter language model, ProGen, on ~280M protein sequences conditioned on taxonomic and keyword tags such as molecular function and cellular component. This provides ProGen with an unprecedented range of evolutionary sequence diversity and allows it to generate with fine-grained control as demonstrated by metrics based on primary sequence similarity, secondary structure accuracy, and conformational energy.
Evaluating the Factual Consistency of Abstractive Text Summarization
Oct 28, 2019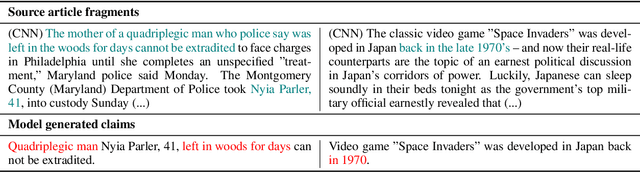


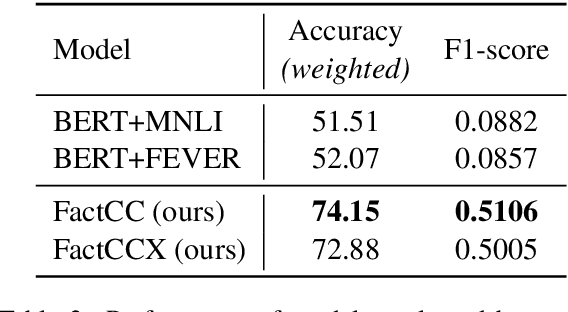
Currently used metrics for assessing summarization algorithms do not account for whether summaries are factually consistent with source documents. We propose a weakly-supervised, model-based approach for verifying factual consistency and identifying conflicts between source documents and a generated summary. Training data is generated by applying a series of rule-based transformations to the sentences of source documents. The factual consistency model is then trained jointly for three tasks: 1) identify whether sentences remain factually consistent after transformation, 2) extract a span in the source documents to support the consistency prediction, 3) extract a span in the summary sentence that is inconsistent if one exists. Transferring this model to summaries generated by several state-of-the art models reveals that this highly scalable approach substantially outperforms previous models, including those trained with strong supervision using standard datasets for natural language inference and fact checking. Additionally, human evaluation shows that the auxiliary span extraction tasks provide useful assistance in the process of verifying factual consistency.