 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgexbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025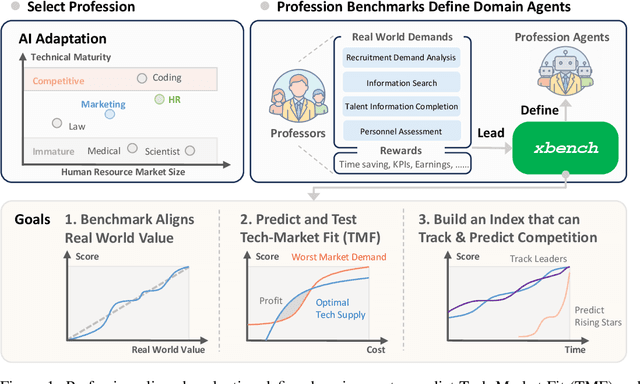

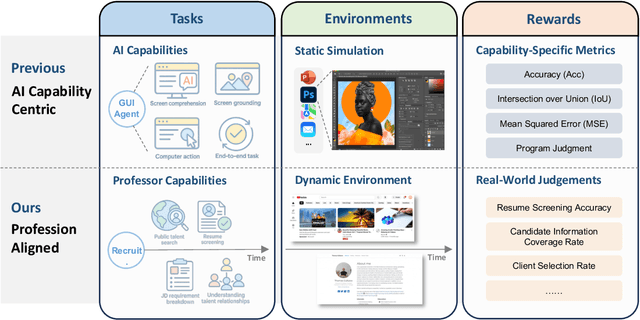
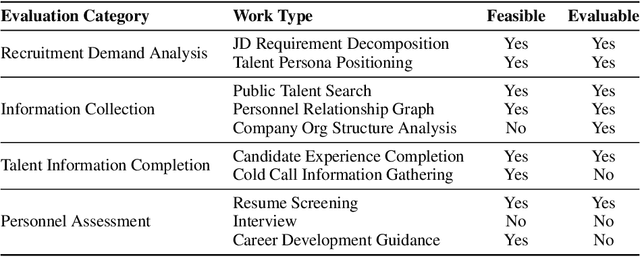
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
JudgeRank: Leveraging Large Language Models for Reasoning-Intensive Reranking
Oct 31, 2024



Accurate document retrieval is crucial for the success of retrieval-augmented generation (RAG) applications, including open-domain question answering and code completion. While large language models (LLMs) have been employed as dense encoders or listwise rerankers in RAG systems, they often struggle with reasoning-intensive tasks because they lack nuanced analysis when judging document relevance. To address this limitation, we introduce JudgeRank, a novel agentic reranker that emulates human cognitive processes when assessing document relevance. Our approach consists of three key steps: (1) query analysis to identify the core problem, (2) document analysis to extract a query-aware summary, and (3) relevance judgment to provide a concise assessment of document relevance. We evaluate JudgeRank on the reasoning-intensive BRIGHT benchmark, demonstrating substantial performance improvements over first-stage retrieval methods and outperforming other popular reranking approaches. In addition, JudgeRank performs on par with fine-tuned state-of-the-art rerankers on the popular BEIR benchmark, validating its zero-shot generalization capability. Through comprehensive ablation studies, we demonstrate that JudgeRank's performance generalizes well across LLMs of various sizes while ensembling them yields even more accurate reranking than individual models.
Improving LLM Reasoning through Scaling Inference Computation with Collaborative Verification
Oct 05, 2024Despite significant advancements in the general capability of large language models (LLMs), they continue to struggle with consistent and accurate reasoning, especially in complex tasks such as mathematical and code reasoning. One key limitation is that LLMs are trained primarily on correct solutions, reducing their ability to detect and learn from errors, which hampers their ability to reliably verify and rank outputs. To address this, we scale up the inference-time computation by generating multiple reasoning paths and employing verifiers to assess and rank the generated outputs by correctness. To facilitate this, we introduce a comprehensive dataset consisting of correct and incorrect solutions for math and code tasks, generated by multiple LLMs. This diverse set of solutions enables verifiers to more effectively distinguish and rank correct answers from erroneous outputs. The training methods for building verifiers were selected based on an extensive comparison of existing approaches. Moreover, to leverage the unique strengths of different reasoning strategies, we propose a novel collaborative method integrating Chain-of-Thought (CoT) and Program-of-Thought (PoT) solutions for verification. CoT provides a clear, step-by-step reasoning process that enhances interpretability, while PoT, being executable, offers a precise and error-sensitive validation mechanism. By taking both of their strengths, our approach significantly improves the accuracy and reliability of reasoning verification. Our verifiers, Math-Rev and Code-Rev, demonstrate substantial performance gains to existing LLMs, achieving state-of-the-art results on benchmarks such as GSM8k and MATH and even outperforming GPT-4o with Qwen-72B-Instruct as the reasoner.
Mixture of Prompt Learning for Vision Language Models
Sep 18, 2024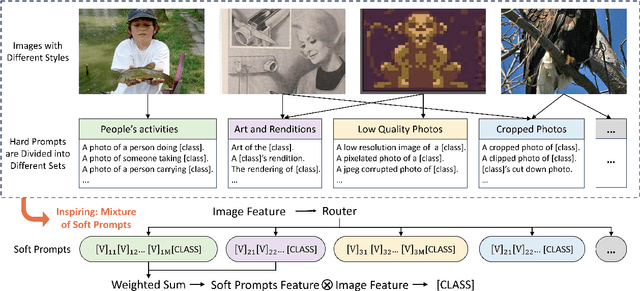
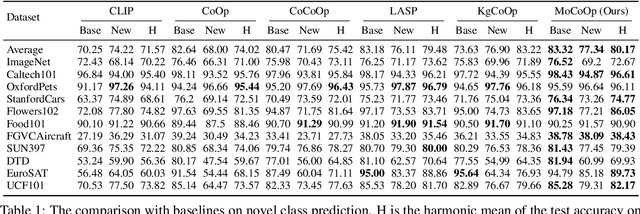
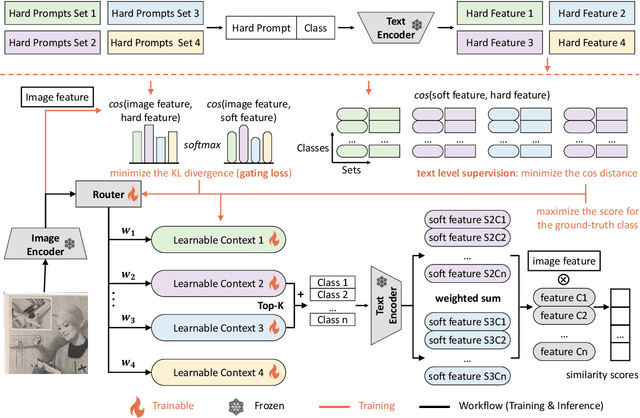
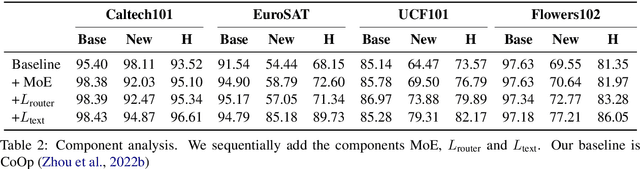
As powerful pre-trained vision-language models (VLMs) like CLIP gain prominence, numerous studies have attempted to combine VLMs for downstream tasks. Among these, prompt learning has been validated as an effective method for adapting to new tasks, which only requiring a small number of parameters. However, current prompt learning methods face two challenges: first, a single soft prompt struggles to capture the diverse styles and patterns within a dataset; second, fine-tuning soft prompts is prone to overfitting. To address these challenges, we propose a mixture of soft prompt learning method incorporating a routing module. This module is able to capture a dataset's varied styles and dynamically selects the most suitable prompts for each instance. Additionally, we introduce a novel gating mechanism to ensure the router selects prompts based on their similarity to hard prompt templates, which both retaining knowledge from hard prompts and improving selection accuracy. We also implement semantically grouped text-level supervision, initializing each soft prompt with the token embeddings of manually designed templates from its group and applied a contrastive loss between the resulted text feature and hard prompt encoded text feature. This supervision ensures that the text features derived from soft prompts remain close to those from their corresponding hard prompts, preserving initial knowledge and mitigating overfitting. Our method has been validated on 11 datasets, demonstrating evident improvements in few-shot learning, domain generalization, and base-to-new generalization scenarios compared to existing baselines. The code will be available at \url{https://anonymous.4open.science/r/mocoop-6387}
Solution-oriented Agent-based Models Generation with Verifier-assisted Iterative In-context Learning
Feb 04, 2024Agent-based models (ABMs) stand as an essential paradigm for proposing and validating hypothetical solutions or policies aimed at addressing challenges posed by complex systems and achieving various objectives. This process demands labor-intensive endeavors and multidisciplinary expertise. Large language models (LLMs) encapsulating cross-domain knowledge and programming proficiency could potentially alleviate the difficulty of this process. However, LLMs excel in handling sequential information, making it challenging for analyzing the intricate interactions and nonlinear dynamics inherent in ABMs. Additionally, due to the lack of self-evaluation capability of LLMs, relying solely on LLMs is insufficient to effectively accomplish this process. In this paper, we present SAGE, a general solution-oriented ABM generation framework designed for automatic modeling and generating solutions for targeted problems. Unlike approaches reliant on expert handcrafting or resource-intensive neural network training, SAGE establishes a verifier-assisted iterative in-context learning process employing large language models (LLMs) to leverages their inherent cross-domain knowledge for tackling intricate demands from diverse domain scenarios. In SAGE, we introduce an semi-structured conceptual representation expliciting the intricate structures of ABMs and an objective representation to guide LLMs in modeling scenarios and proposing hypothetical solutions through in-context learning. To ensure the model executability and solution feasibility, SAGE devises a two-level verifier with chain-of-thought prompting tailored to the complex interactions and non-linear dynamics of ABMs, driving the iterative generation optimization. Moreover, we construct an evaluation dataset of solution-oriented ABMs from open sources.It contains practical models across various domains.
General Automatic Solution Generation of Social Problems
Jan 25, 2024Given the escalating intricacy and multifaceted nature of contemporary social systems, manually generating solutions to address pertinent social issues has become a formidable task. In response to this challenge, the rapid development of artificial intelligence has spurred the exploration of computational methodologies aimed at automatically generating solutions. However, current methods for auto-generation of solutions mainly concentrate on local social regulations that pertain to specific scenarios. Here, we report an automatic social operating system (ASOS) designed for general social solution generation, which is built upon agent-based models, enabling both global and local analyses and regulations of social problems across spatial and temporal dimensions. ASOS adopts a hypergraph with extensible social semantics for a comprehensive and structured representation of social dynamics. It also incorporates a generalized protocol for standardized hypergraph operations and a symbolic hybrid framework that delivers interpretable solutions, yielding a balance between regulatory efficacy and function viability. To demonstrate the effectiveness of ASOS, we apply it to the domain of averting extreme events within international oil futures markets. By generating a new trading role supplemented by new mechanisms, ASOS can adeptly discern precarious market conditions and make front-running interventions for non-profit purposes. This study demonstrates that ASOS provides an efficient and systematic approach for generating solutions for enhancing our society.
Parameter-Efficient Detoxification with Contrastive Decoding
Jan 13, 2024

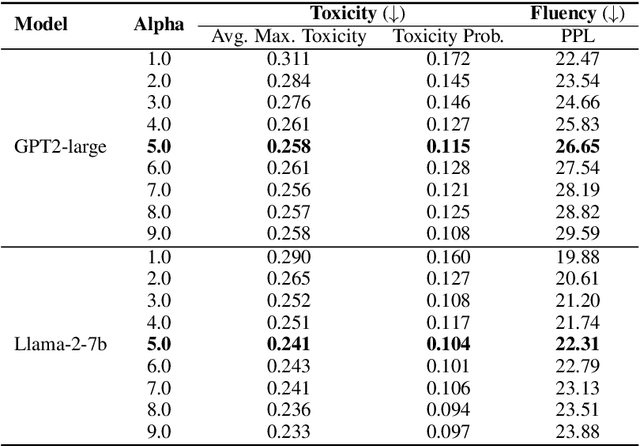

The field of natural language generation has witnessed significant advancements in recent years, including the development of controllable text generation techniques. However, controlling the attributes of the generated text remains a challenge, especially when aiming to avoid undesirable behavior such as toxicity. In this work, we introduce Detoxification Generator (DETOXIGEN), an inference-time algorithm that steers the generation away from unwanted styles. DETOXIGEN is an ensemble of a pre-trained language model (generator) and a detoxifier. The detoxifier is trained intentionally on the toxic data representative of the undesirable attribute, encouraging it to generate text in that style exclusively. During the actual generation, we use the trained detoxifier to produce undesirable tokens for the generator to contrast against at each decoding step. This approach directly informs the generator to avoid generating tokens that the detoxifier considers highly likely. We evaluate DETOXIGEN on the commonly used REALTOXICITYPROMPTS benchmark (Gehman et al., 2020) with various language models as generators. We find that it significantly outperforms previous approaches in detoxification metrics while not compromising on the generation quality. Moreover, the detoxifier is obtained by soft prompt-tuning using the same backbone language model as the generator. Hence, DETOXIGEN requires only a tiny amount of extra weights from the virtual tokens of the detoxifier to be loaded into GPU memory while decoding, making it a promising lightweight, practical, and parameter-efficient detoxification strategy.
DIVKNOWQA: Assessing the Reasoning Ability of LLMs via Open-Domain Question Answering over Knowledge Base and Text
Oct 31, 2023Large Language Models (LLMs) have exhibited impressive generation capabilities, but they suffer from hallucinations when solely relying on their internal knowledge, especially when answering questions that require less commonly known information. Retrieval-augmented LLMs have emerged as a potential solution to ground LLMs in external knowledge. Nonetheless, recent approaches have primarily emphasized retrieval from unstructured text corpora, owing to its seamless integration into prompts. When using structured data such as knowledge graphs, most methods simplify it into natural text, neglecting the underlying structures. Moreover, a significant gap in the current landscape is the absence of a realistic benchmark for evaluating the effectiveness of grounding LLMs on heterogeneous knowledge sources (e.g., knowledge base and text). To fill this gap, we have curated a comprehensive dataset that poses two unique challenges: (1) Two-hop multi-source questions that require retrieving information from both open-domain structured and unstructured knowledge sources; retrieving information from structured knowledge sources is a critical component in correctly answering the questions. (2) The generation of symbolic queries (e.g., SPARQL for Wikidata) is a key requirement, which adds another layer of challenge. Our dataset is created using a combination of automatic generation through predefined reasoning chains and human annotation. We also introduce a novel approach that leverages multiple retrieval tools, including text passage retrieval and symbolic language-assisted retrieval. Our model outperforms previous approaches by a significant margin, demonstrating its effectiveness in addressing the above-mentioned reasoning challenges.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Attention-based 3D CNN with Multi-layer Features for Alzheimer's Disease Diagnosis using Brain Images
Aug 10, 2023Structural MRI and PET imaging play an important role in the diagnosis of Alzheimer's disease (AD), showing the morphological changes and glucose metabolism changes in the brain respectively. The manifestations in the brain image of some cognitive impairment patients are relatively inconspicuous, for example, it still has difficulties in achieving accurate diagnosis through sMRI in clinical practice. With the emergence of deep learning, convolutional neural network (CNN) has become a valuable method in AD-aided diagnosis, but some CNN methods cannot effectively learn the features of brain image, making the diagnosis of AD still presents some challenges. In this work, we propose an end-to-end 3D CNN framework for AD diagnosis based on ResNet, which integrates multi-layer features obtained under the effect of the attention mechanism to better capture subtle differences in brain images. The attention maps showed our model can focus on key brain regions related to the disease diagnosis. Our method was verified in ablation experiments with two modality images on 792 subjects from the ADNI database, where AD diagnostic accuracies of 89.71% and 91.18% were achieved based on sMRI and PET respectively, and also outperformed some state-of-the-art methods.
* 4 pages, 4 figures