 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025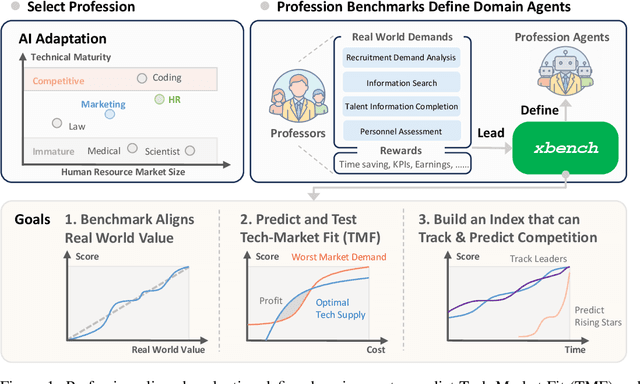

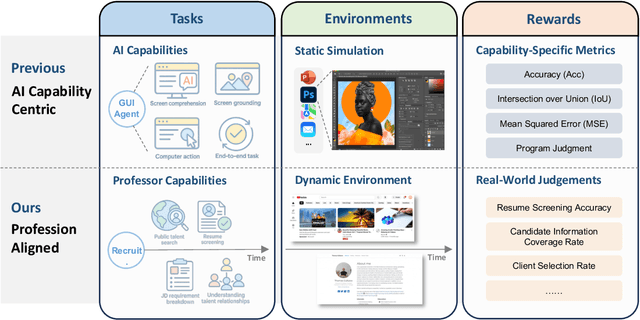
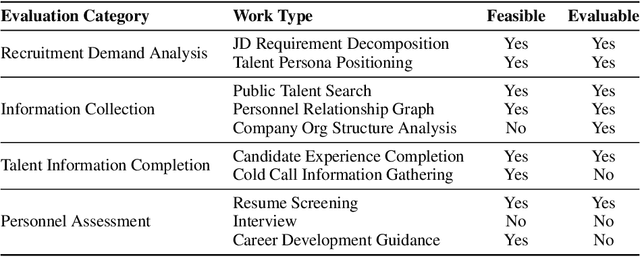
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

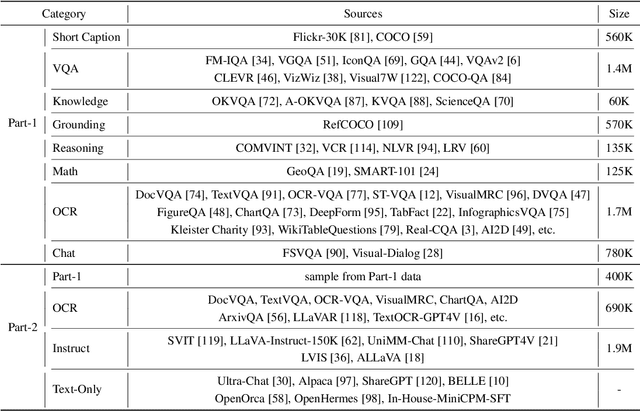
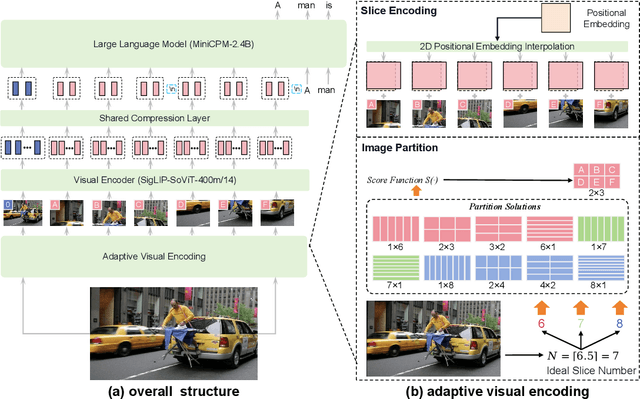
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
May 27, 2024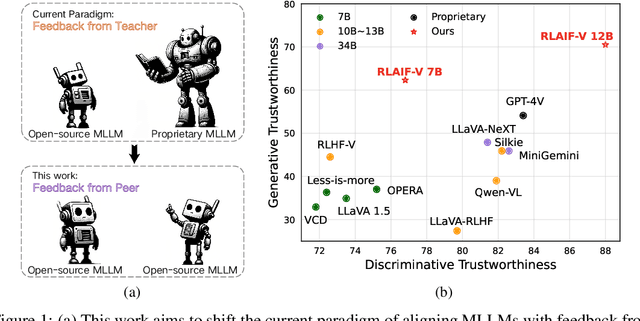
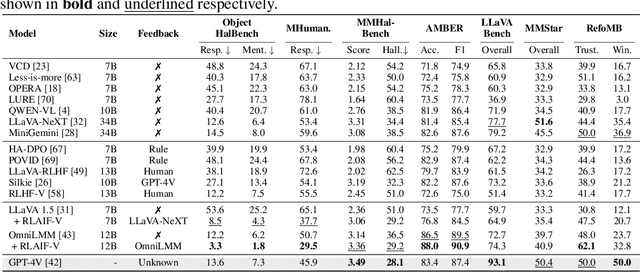
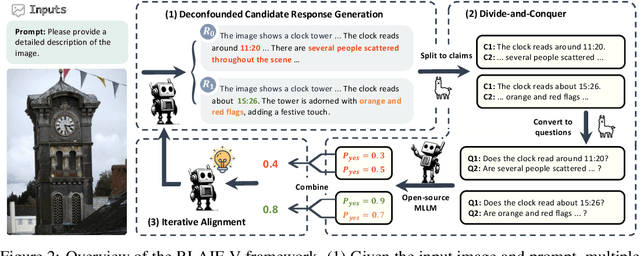
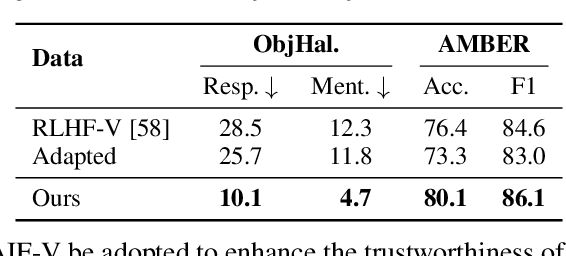
Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues. Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap. As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability. In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm. Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks. Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9\% and overall hallucination by 42.1\%, outperforming the labeler model. Remarkably, RLAIF-V also reveals the self-alignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5\% overall hallucination rate, surpassing GPT-4V (45.9\%) by a large margin. The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs.
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback
Dec 01, 2023
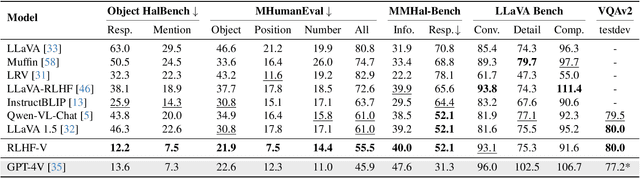
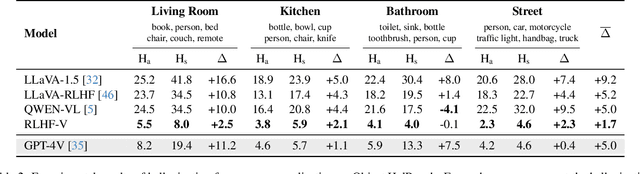
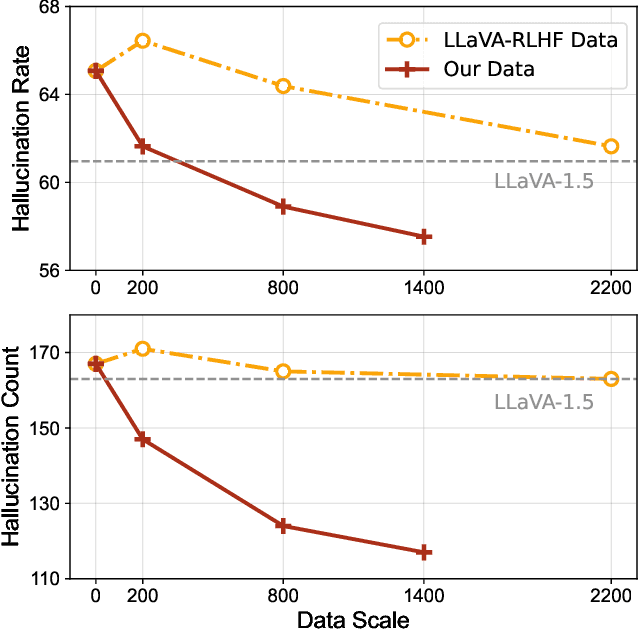
Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in multimodal understanding, reasoning, and interaction. However, existing MLLMs prevalently suffer from serious hallucination problems, generating text that is not factually grounded in associated images. The problem makes existing MLLMs untrustworthy and thus impractical in real-world (especially high-stakes) applications. To address the challenge, we present RLHF-V, which enhances MLLM trustworthiness via behavior alignment from fine-grained correctional human feedback. Specifically, RLHF-V collects human preference in the form of segment-level corrections on hallucinations, and performs dense direct preference optimization over the human feedback. Comprehensive experiments on five benchmarks in both automatic and human evaluation show that, RLHF-V can enable substantially more trustworthy MLLM behaviors with promising data and computation efficiency. Remarkably, using 1.4k annotated data samples, RLHF-V significantly reduces the hallucination rate of the base MLLM by 34.8%, outperforming the concurrent LLaVA-RLHF trained on 10k annotated data. The final model achieves state-of-the-art performance in trustworthiness among open-source MLLMs, and shows better robustness than GPT-4V in preventing hallucinations aroused from over-generalization. We open-source our code, model, and data at https://github.com/RLHF-V/RLHF-V.
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023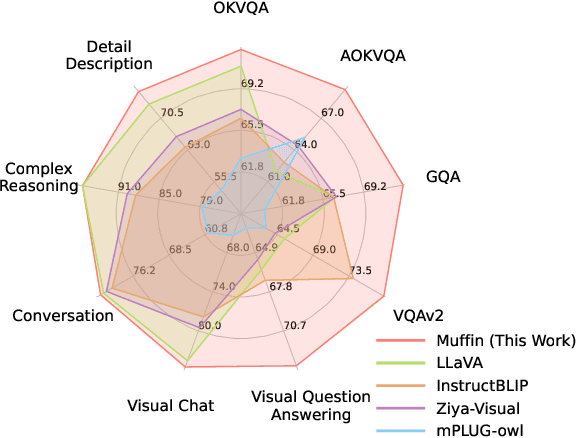
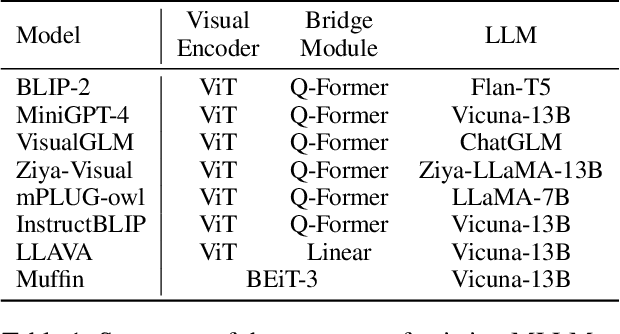
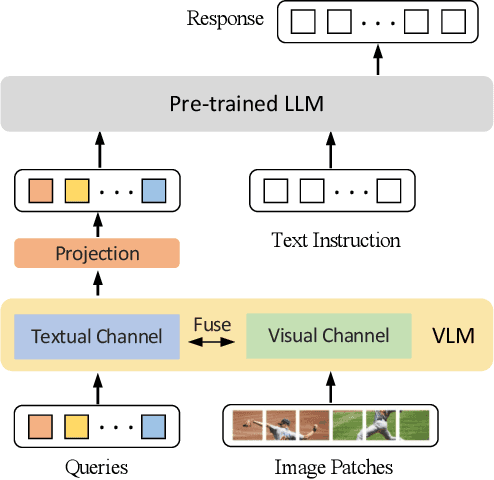
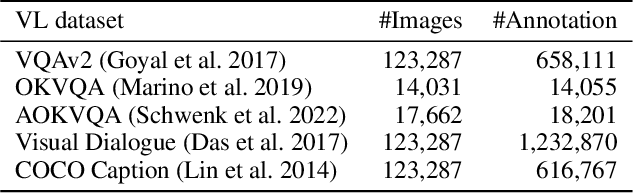
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.