 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024


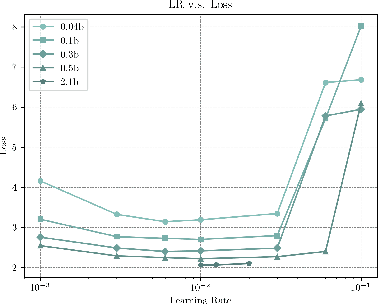
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023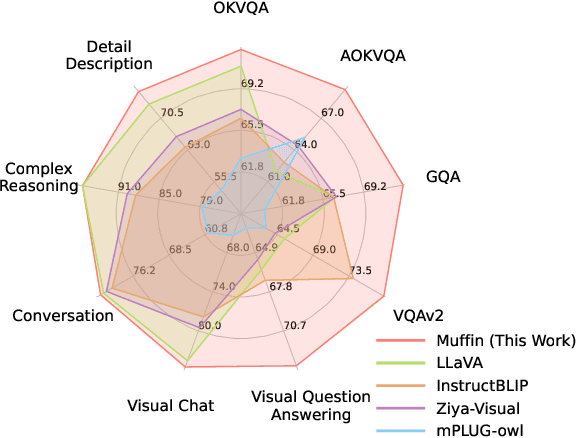
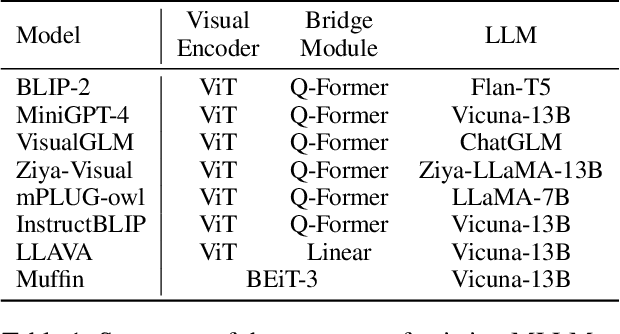
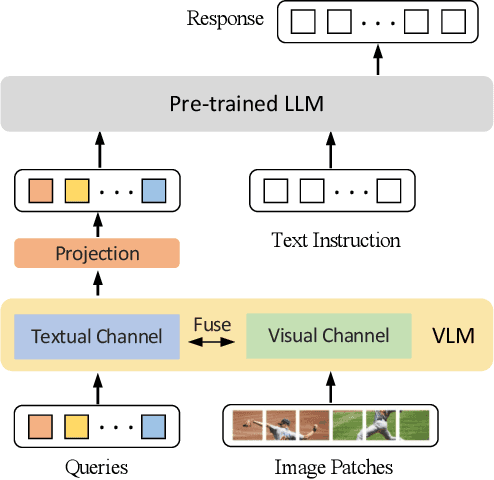
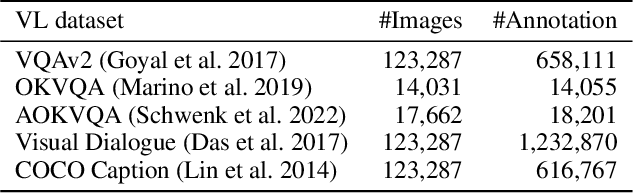
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.