 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePegasusFlow: Parallel Rolling-Denoising Score Sampling for Robot Diffusion Planner Flow Matching
Sep 10, 2025Diffusion models offer powerful generative capabilities for robot trajectory planning, yet their practical deployment on robots is hindered by a critical bottleneck: a reliance on imitation learning from expert demonstrations. This paradigm is often impractical for specialized robots where data is scarce and creates an inefficient, theoretically suboptimal training pipeline. To overcome this, we introduce PegasusFlow, a hierarchical rolling-denoising framework that enables direct and parallel sampling of trajectory score gradients from environmental interaction, completely bypassing the need for expert data. Our core innovation is a novel sampling algorithm, Weighted Basis Function Optimization (WBFO), which leverages spline basis representations to achieve superior sample efficiency and faster convergence compared to traditional methods like MPPI. The framework is embedded within a scalable, asynchronous parallel simulation architecture that supports massively parallel rollouts for efficient data collection. Extensive experiments on trajectory optimization and robotic navigation tasks demonstrate that our approach, particularly Action-Value WBFO (AVWBFO) combined with a reinforcement learning warm-start, significantly outperforms baselines. In a challenging barrier-crossing task, our method achieved a 100% success rate and was 18% faster than the next-best method, validating its effectiveness for complex terrain locomotion planning. https://masteryip.github.io/pegasusflow.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024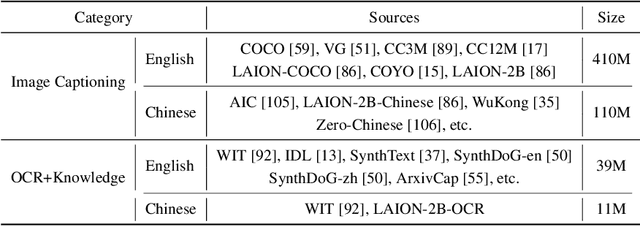

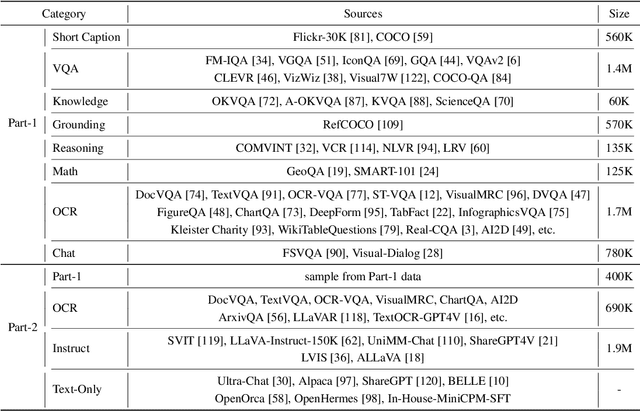
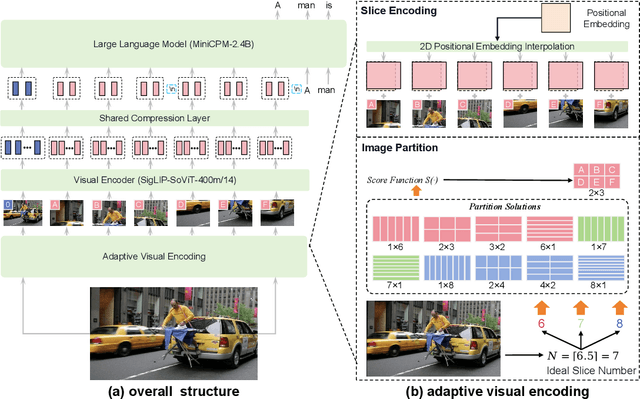
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
Physical formula enhanced multi-task learning for pharmacokinetics prediction
Apr 16, 2024



Artificial intelligence (AI) technology has demonstrated remarkable potential in drug dis-covery, where pharmacokinetics plays a crucial role in determining the dosage, safety, and efficacy of new drugs. A major challenge for AI-driven drug discovery (AIDD) is the scarcity of high-quality data, which often requires extensive wet-lab work. A typical example of this is pharmacokinetic experiments. In this work, we develop a physical formula enhanced mul-ti-task learning (PEMAL) method that predicts four key parameters of pharmacokinetics simultaneously. By incorporating physical formulas into the multi-task framework, PEMAL facilitates effective knowledge sharing and target alignment among the pharmacokinetic parameters, thereby enhancing the accuracy of prediction. Our experiments reveal that PEMAL significantly lowers the data demand, compared to typical Graph Neural Networks. Moreover, we demonstrate that PEMAL enhances the robustness to noise, an advantage that conventional Neural Networks do not possess. Another advantage of PEMAL is its high flexibility, which can be potentially applied to other multi-task machine learning scenarios. Overall, our work illustrates the benefits and potential of using PEMAL in AIDD and other scenarios with data scarcity and noise.
ICMC-ASR: The ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition Challenge
Jan 07, 2024

To promote speech processing and recognition research in driving scenarios, we build on the success of the Intelligent Cockpit Speech Recognition Challenge (ICSRC) held at ISCSLP 2022 and launch the ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) Challenge. This challenge collects over 100 hours of multi-channel speech data recorded inside a new energy vehicle and 40 hours of noise for data augmentation. Two tracks, including automatic speech recognition (ASR) and automatic speech diarization and recognition (ASDR) are set up, using character error rate (CER) and concatenated minimum permutation character error rate (cpCER) as evaluation metrics, respectively. Overall, the ICMC-ASR Challenge attracts 98 participating teams and receives 53 valid results in both tracks. In the end, first-place team USTCiflytek achieves a CER of 13.16% in the ASR track and a cpCER of 21.48% in the ASDR track, showing an absolute improvement of 13.08% and 51.4% compared to our challenge baseline, respectively.
Knowledge Enhanced Conditional Imputation for Healthcare Time-series
Jan 04, 2024This study presents a novel approach to addressing the challenge of missing data in multivariate time series, with a particular focus on the complexities of healthcare data. Our Conditional Self-Attention Imputation (CSAI) model, grounded in a transformer-based framework, introduces a conditional hidden state initialization tailored to the intricacies of medical time series data. This methodology diverges from traditional imputation techniques by specifically targeting the imbalance in missing data distribution, a crucial aspect often overlooked in healthcare datasets. By integrating advanced knowledge embedding and a non-uniform masking strategy, CSAI adeptly adjusts to the distinct patterns of missing data in Electronic Health Records (EHRs).
U2-KWS: Unified Two-pass Open-vocabulary Keyword Spotting with Keyword Bias
Dec 15, 2023Open-vocabulary keyword spotting (KWS), which allows users to customize keywords, has attracted increasingly more interest. However, existing methods based on acoustic models and post-processing train the acoustic model with ASR training criteria to model all phonemes, making the acoustic model under-optimized for the KWS task. To solve this problem, we propose a novel unified two-pass open-vocabulary KWS (U2-KWS) framework inspired by the two-pass ASR model U2. Specifically, we employ the CTC branch as the first stage model to detect potential keyword candidates and the decoder branch as the second stage model to validate candidates. In order to enhance any customized keywords, we redesign the U2 training procedure for U2-KWS and add keyword information by audio and text cross-attention into both branches. We perform experiments on our internal dataset and Aishell-1. The results show that U2-KWS can achieve a significant relative wake-up rate improvement of 41% compared to the traditional customized KWS systems when the false alarm rate is fixed to 0.5 times per hour.
NExT-Chat: An LMM for Chat, Detection and Segmentation
Nov 13, 2023



The development of large language models (LLMs) has greatly advanced the field of multimodal understanding, leading to the emergence of large multimodal models (LMMs). In order to enhance the level of visual comprehension, recent studies have equipped LMMs with region-level understanding capabilities by representing object bounding box coordinates as a series of text sequences (pixel2seq). In this paper, we introduce a novel paradigm for object location modeling called pixel2emb method, where we ask the LMM to output the location embeddings and then decoded by different decoders. This paradigm allows for different location formats (such as bounding boxes and masks) to be used in multimodal conversations Furthermore, this kind of embedding based location modeling enables the utilization of existing practices in localization tasks, such as detection and segmentation. In scenarios with limited resources, our pixel2emb demonstrates superior performance compared to existing state-of-the-art (SOTA) approaches in both the location input and output tasks under fair comparison. Leveraging the proposed pixel2emb method, we train an LMM named NExT-Chat and demonstrate its capability of handling multiple tasks like visual grounding, region caption, and grounded reasoning.
Spike-Triggered Contextual Biasing for End-to-End Mandarin Speech Recognition
Oct 07, 2023



The attention-based deep contextual biasing method has been demonstrated to effectively improve the recognition performance of end-to-end automatic speech recognition (ASR) systems on given contextual phrases. However, unlike shallow fusion methods that directly bias the posterior of the ASR model, deep biasing methods implicitly integrate contextual information, making it challenging to control the degree of bias. In this study, we introduce a spike-triggered deep biasing method that simultaneously supports both explicit and implicit bias. Moreover, both bias approaches exhibit significant improvements and can be cascaded with shallow fusion methods for better results. Furthermore, we propose a context sampling enhancement strategy and improve the contextual phrase filtering algorithm. Experiments on the public WenetSpeech Mandarin biased-word dataset show a 32.0% relative CER reduction compared to the baseline model, with an impressively 68.6% relative CER reduction on contextual phrases.