 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphiNet: A Graph Subdivision Network for Adaptive Bi-ventricle Surface Reconstruction
Dec 14, 2024



Cardiac Magnetic Resonance (CMR) imaging is widely used for heart modelling and digital twin computational analysis due to its ability to visualize soft tissues and capture dynamic functions. However, the anisotropic nature of CMR images, characterized by large inter-slice distances and misalignments from cardiac motion, poses significant challenges to accurate model reconstruction. These limitations result in data loss and measurement inaccuracies, hindering the capture of detailed anatomical structures. This study introduces MorphiNet, a novel network that enhances heart model reconstruction by leveraging high-resolution Computer Tomography (CT) images, unpaired with CMR images, to learn heart anatomy. MorphiNet encodes anatomical structures as gradient fields, transforming template meshes into patient-specific geometries. A multi-layer graph subdivision network refines these geometries while maintaining dense point correspondence. The proposed method achieves high anatomy fidelity, demonstrating approximately 40% higher Dice scores, half the Hausdorff distance, and around 3 mm average surface error compared to state-of-the-art methods. MorphiNet delivers superior results with greater inference efficiency. This approach represents a significant advancement in addressing the challenges of CMR-based heart model reconstruction, potentially improving digital twin computational analyses of cardiac structure and functions.
Fine-tuning -- a Transfer Learning approach
Nov 06, 2024Secondary research use of Electronic Health Records (EHRs) is often hampered by the abundance of missing data in this valuable resource. Missingness in EHRs occurs naturally as a result of the data recording practices during routine clinical care, but handling it is crucial to the precision of medical analysis and the decision-making that follows. The literature contains a variety of imputation methodologies based on deep neural networks. Those aim to overcome the dynamic, heterogeneous and multivariate missingness patterns of EHRs, which cannot be handled by classical and statistical imputation methods. However, all existing deep imputation methods rely on end-to-end pipelines that incorporate both imputation and downstream analyses, e.g. classification. This coupling makes it difficult to assess the quality of imputation and takes away the flexibility of re-using the imputer for a different task. Furthermore, most end-to-end deep architectures tend to use complex networks to perform the downstream task, in addition to the already sophisticated deep imputation network. We, therefore ask if the high performance reported in the literature is due to the imputer or the classifier and further ask if an optimised state-of-the-art imputer is used, a simpler classifier can achieve comparable performance. This paper explores the development of a modular, deep learning-based imputation and classification pipeline, specifically built to leverage the capabilities of state-of-the-art imputation models for downstream classification tasks. Such a modular approach enables a) objective assessment of the quality of the imputer and classifier independently, and b) enables the exploration of the performance of simpler classification architectures using an optimised imputer.
How Deep is your Guess? A Fresh Perspective on Deep Learning for Medical Time-Series Imputation
Jul 11, 2024We introduce a novel classification framework for time-series imputation using deep learning, with a particular focus on clinical data. By identifying conceptual gaps in the literature and existing reviews, we devise a taxonomy grounded on the inductive bias of neural imputation frameworks, resulting in a classification of existing deep imputation strategies based on their suitability for specific imputation scenarios and data-specific properties. Our review further examines the existing methodologies employed to benchmark deep imputation models, evaluating their effectiveness in capturing the missingness scenarios found in clinical data and emphasising the importance of reconciling mathematical abstraction with clinical insights. Our classification aims to serve as a guide for researchers to facilitate the selection of appropriate deep learning imputation techniques tailored to their specific clinical data. Our novel perspective also highlights the significance of bridging the gap between computational methodologies and medical insights to achieve clinically sound imputation models.
TSI-Bench: Benchmarking Time Series Imputation
Jun 18, 2024Effective imputation is a crucial preprocessing step for time series analysis. Despite the development of numerous deep learning algorithms for time series imputation, the community lacks standardized and comprehensive benchmark platforms to effectively evaluate imputation performance across different settings. Moreover, although many deep learning forecasting algorithms have demonstrated excellent performance, whether their modeling achievements can be transferred to time series imputation tasks remains unexplored. To bridge these gaps, we develop TSI-Bench, the first (to our knowledge) comprehensive benchmark suite for time series imputation utilizing deep learning techniques. The TSI-Bench pipeline standardizes experimental settings to enable fair evaluation of imputation algorithms and identification of meaningful insights into the influence of domain-appropriate missingness ratios and patterns on model performance. Furthermore, TSI-Bench innovatively provides a systematic paradigm to tailor time series forecasting algorithms for imputation purposes. Our extensive study across 34,804 experiments, 28 algorithms, and 8 datasets with diverse missingness scenarios demonstrates TSI-Bench's effectiveness in diverse downstream tasks and potential to unlock future directions in time series imputation research and analysis. The source code and experiment logs are available at https://github.com/WenjieDu/AwesomeImputation.
Unveiling the Secrets: How Masking Strategies Shape Time Series Imputation
May 26, 2024

In this study, we explore the impact of different masking strategies on time series imputation models. We evaluate the effects of pre-masking versus in-mini-batch masking, normalization timing, and the choice between augmenting and overlaying artificial missingness. Using three diverse datasets, we benchmark eleven imputation models with different missing rates. Our results demonstrate that masking strategies significantly influence imputation accuracy, revealing that more sophisticated and data-driven masking designs are essential for robust model evaluation. We advocate for refined experimental designs and comprehensive disclosureto better simulate real-world patterns, enhancing the practical applicability of imputation models.
Question answering systems for health professionals at the point of care -- a systematic review
Jan 24, 2024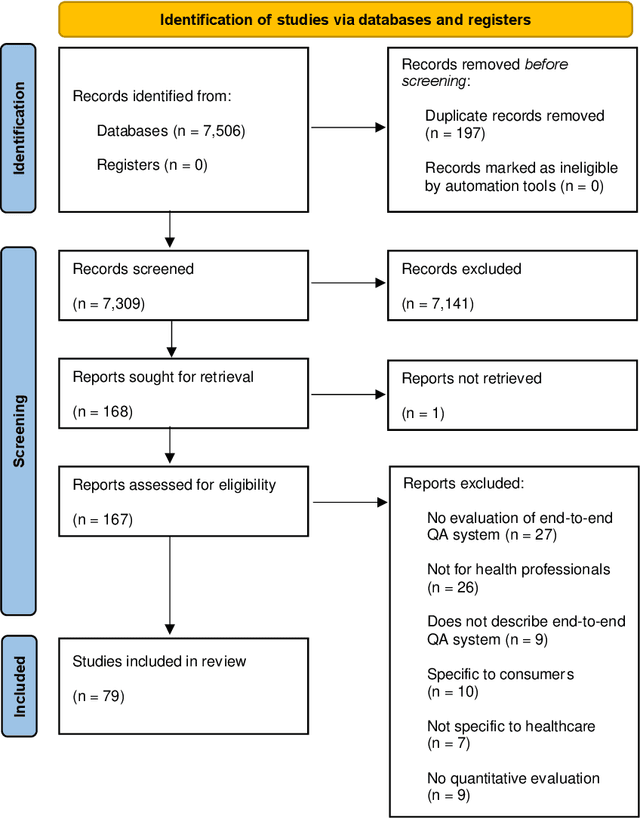
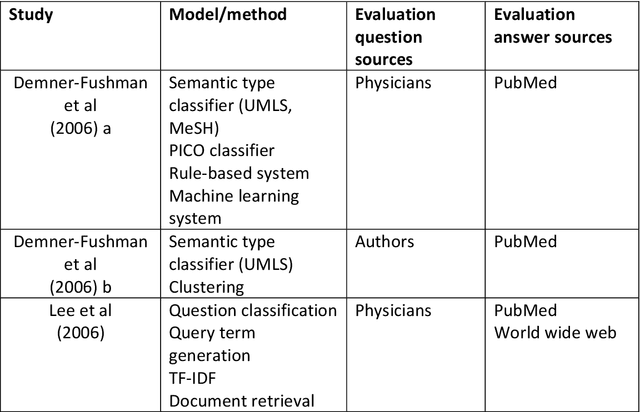
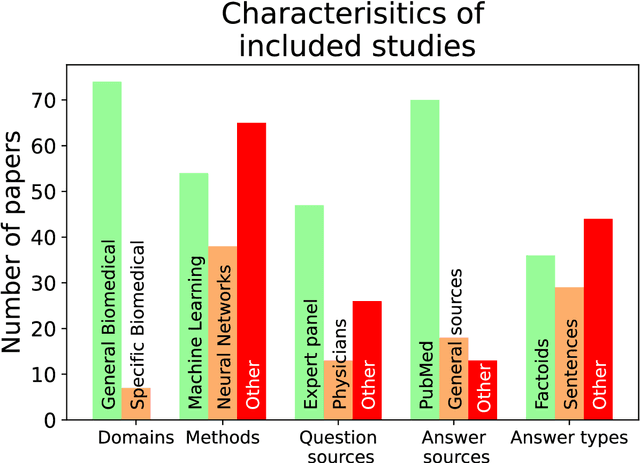

Objective: Question answering (QA) systems have the potential to improve the quality of clinical care by providing health professionals with the latest and most relevant evidence. However, QA systems have not been widely adopted. This systematic review aims to characterize current medical QA systems, assess their suitability for healthcare, and identify areas of improvement. Materials and methods: We searched PubMed, IEEE Xplore, ACM Digital Library, ACL Anthology and forward and backward citations on 7th February 2023. We included peer-reviewed journal and conference papers describing the design and evaluation of biomedical QA systems. Two reviewers screened titles, abstracts, and full-text articles. We conducted a narrative synthesis and risk of bias assessment for each study. We assessed the utility of biomedical QA systems. Results: We included 79 studies and identified themes, including question realism, answer reliability, answer utility, clinical specialism, systems, usability, and evaluation methods. Clinicians' questions used to train and evaluate QA systems were restricted to certain sources, types and complexity levels. No system communicated confidence levels in the answers or sources. Many studies suffered from high risks of bias and applicability concerns. Only 8 studies completely satisfied any criterion for clinical utility, and only 7 reported user evaluations. Most systems were built with limited input from clinicians. Discussion: While machine learning methods have led to increased accuracy, most studies imperfectly reflected real-world healthcare information needs. Key research priorities include developing more realistic healthcare QA datasets and considering the reliability of answer sources, rather than merely focusing on accuracy.
Knowledge Enhanced Conditional Imputation for Healthcare Time-series
Jan 04, 2024This study presents a novel approach to addressing the challenge of missing data in multivariate time series, with a particular focus on the complexities of healthcare data. Our Conditional Self-Attention Imputation (CSAI) model, grounded in a transformer-based framework, introduces a conditional hidden state initialization tailored to the intricacies of medical time series data. This methodology diverges from traditional imputation techniques by specifically targeting the imbalance in missing data distribution, a crucial aspect often overlooked in healthcare datasets. By integrating advanced knowledge embedding and a non-uniform masking strategy, CSAI adeptly adjusts to the distinct patterns of missing data in Electronic Health Records (EHRs).
Uncertainty-Aware Deep Attention Recurrent Neural Network for Heterogeneous Time Series Imputation
Jan 04, 2024Missingness is ubiquitous in multivariate time series and poses an obstacle to reliable downstream analysis. Although recurrent network imputation achieved the SOTA, existing models do not scale to deep architectures that can potentially alleviate issues arising in complex data. Moreover, imputation carries the risk of biased estimations of the ground truth. Yet, confidence in the imputed values is always unmeasured or computed post hoc from model output. We propose DEep Attention Recurrent Imputation (DEARI), which jointly estimates missing values and their associated uncertainty in heterogeneous multivariate time series. By jointly representing feature-wise correlations and temporal dynamics, we adopt a self attention mechanism, along with an effective residual component, to achieve a deep recurrent neural network with good imputation performance and stable convergence. We also leverage self-supervised metric learning to boost performance by optimizing sample similarity. Finally, we transform DEARI into a Bayesian neural network through a novel Bayesian marginalization strategy to produce stochastic DEARI, which outperforms its deterministic equivalent. Experiments show that DEARI surpasses the SOTA in diverse imputation tasks using real-world datasets, namely air quality control, healthcare and traffic.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Sep 05, 2023



Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.