 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs
Jun 28, 2024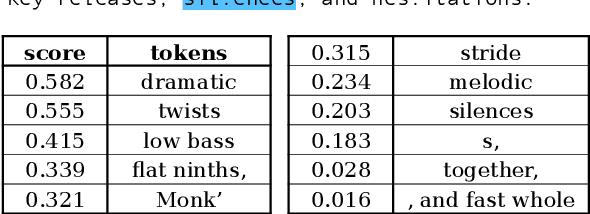
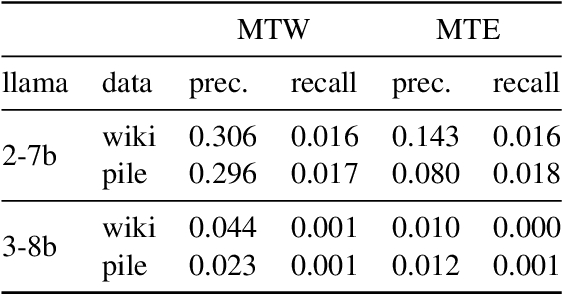
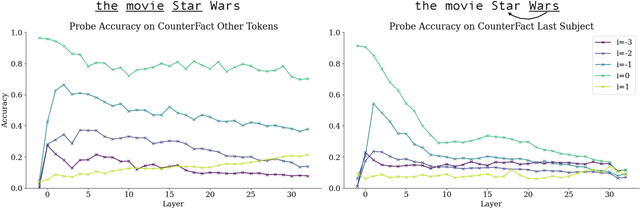
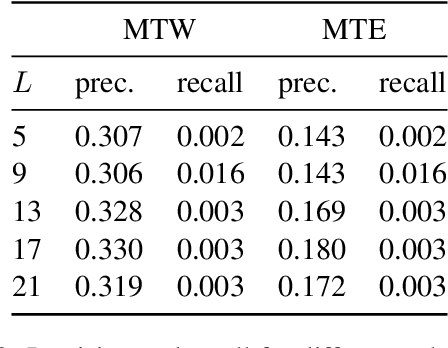
LLMs process text as sequences of tokens that roughly correspond to words, where less common words are represented by multiple tokens. However, individual tokens are often semantically unrelated to the meanings of the words/concepts they comprise. For example, Llama-2-7b's tokenizer splits the word "northeastern" into the tokens ['_n', 'ort', 'he', 'astern'], none of which correspond to semantically meaningful units like "north" or "east." Similarly, the overall meanings of named entities like "Neil Young" and multi-word expressions like "break a leg" cannot be directly inferred from their constituent tokens. Mechanistically, how do LLMs convert such arbitrary groups of tokens into useful higher-level representations? In this work, we find that last token representations of named entities and multi-token words exhibit a pronounced "erasure" effect, where information about previous and current tokens is rapidly forgotten in early layers. Using this observation, we propose a method to "read out" the implicit vocabulary of an autoregressive LLM by examining differences in token representations across layers, and present results of this method for Llama-2-7b and Llama-3-8B. To our knowledge, this is the first attempt to probe the implicit vocabulary of an LLM.
Question answering systems for health professionals at the point of care -- a systematic review
Jan 24, 2024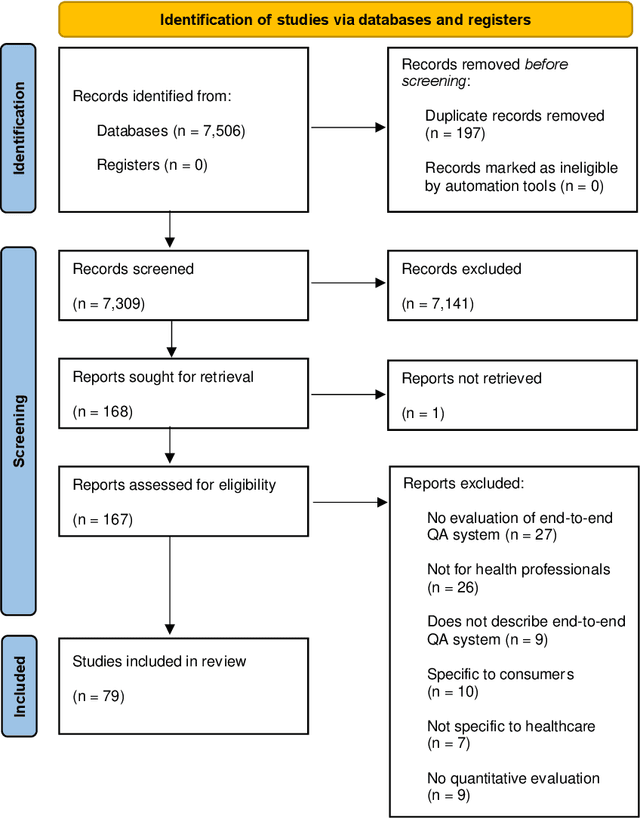
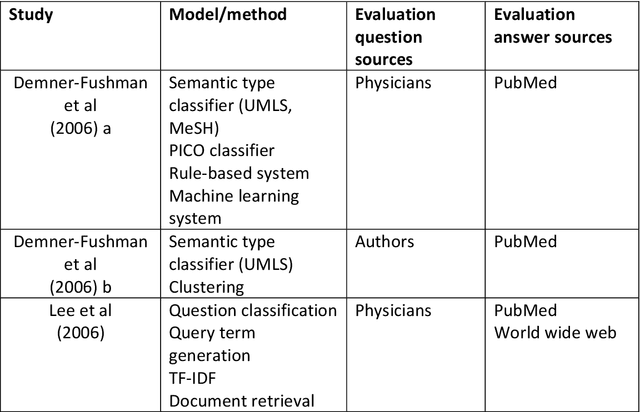
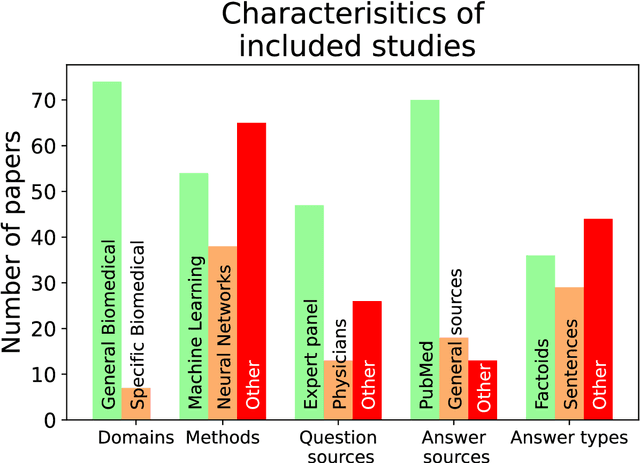

Objective: Question answering (QA) systems have the potential to improve the quality of clinical care by providing health professionals with the latest and most relevant evidence. However, QA systems have not been widely adopted. This systematic review aims to characterize current medical QA systems, assess their suitability for healthcare, and identify areas of improvement. Materials and methods: We searched PubMed, IEEE Xplore, ACM Digital Library, ACL Anthology and forward and backward citations on 7th February 2023. We included peer-reviewed journal and conference papers describing the design and evaluation of biomedical QA systems. Two reviewers screened titles, abstracts, and full-text articles. We conducted a narrative synthesis and risk of bias assessment for each study. We assessed the utility of biomedical QA systems. Results: We included 79 studies and identified themes, including question realism, answer reliability, answer utility, clinical specialism, systems, usability, and evaluation methods. Clinicians' questions used to train and evaluate QA systems were restricted to certain sources, types and complexity levels. No system communicated confidence levels in the answers or sources. Many studies suffered from high risks of bias and applicability concerns. Only 8 studies completely satisfied any criterion for clinical utility, and only 7 reported user evaluations. Most systems were built with limited input from clinicians. Discussion: While machine learning methods have led to increased accuracy, most studies imperfectly reflected real-world healthcare information needs. Key research priorities include developing more realistic healthcare QA datasets and considering the reliability of answer sources, rather than merely focusing on accuracy.
That's the Wrong Lung! Evaluating and Improving the Interpretability of Unsupervised Multimodal Encoders for Medical Data
Oct 12, 2022



Pretraining multimodal models on Electronic Health Records (EHRs) provides a means of learning representations that can transfer to downstream tasks with minimal supervision. Recent multimodal models induce soft local alignments between image regions and sentences. This is of particular interest in the medical domain, where alignments might highlight regions in an image relevant to specific phenomena described in free-text. While past work has suggested that attention "heatmaps" can be interpreted in this manner, there has been little evaluation of such alignments. We compare alignments from a state-of-the-art multimodal (image and text) model for EHR with human annotations that link image regions to sentences. Our main finding is that the text has an often weak or unintuitive influence on attention; alignments do not consistently reflect basic anatomical information. Moreover, synthetic modifications -- such as substituting "left" for "right" -- do not substantially influence highlights. Simple techniques such as allowing the model to opt out of attending to the image and few-shot finetuning show promise in terms of their ability to improve alignments with very little or no supervision.
RedHOT: A Corpus of Annotated Medical Questions, Experiences, and Claims on Social Media
Oct 12, 2022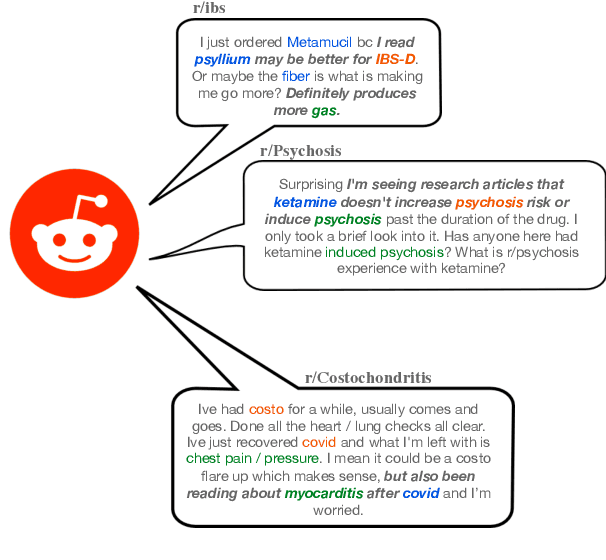
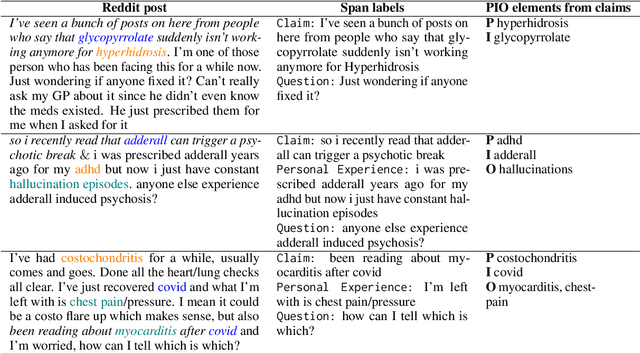
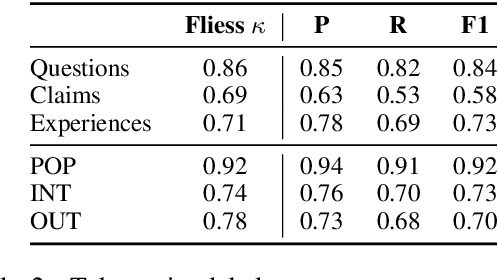
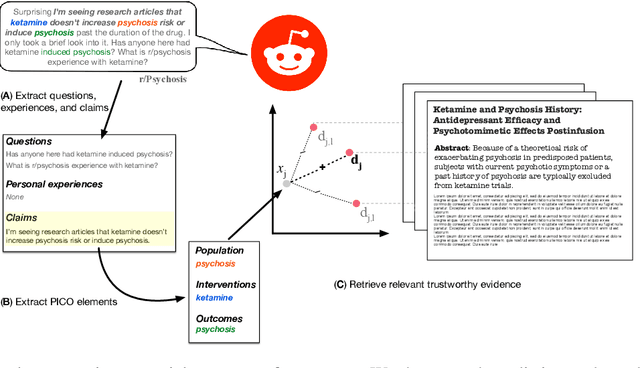
We present Reddit Health Online Talk (RedHOT), a corpus of 22,000 richly annotated social media posts from Reddit spanning 24 health conditions. Annotations include demarcations of spans corresponding to medical claims, personal experiences, and questions. We collect additional granular annotations on identified claims. Specifically, we mark snippets that describe patient Populations, Interventions, and Outcomes (PIO elements) within these. Using this corpus, we introduce the task of retrieving trustworthy evidence relevant to a given claim made on social media. We propose a new method to automatically derive (noisy) supervision for this task which we use to train a dense retrieval model; this outperforms baseline models. Manual evaluation of retrieval results performed by medical doctors indicate that while our system performance is promising, there is considerable room for improvement. Collected annotations (and scripts to assemble the dataset), are available at https://github.com/sominw/redhot.
Kronecker Factorization for Preventing Catastrophic Forgetting in Large-scale Medical Entity Linking
Nov 11, 2021
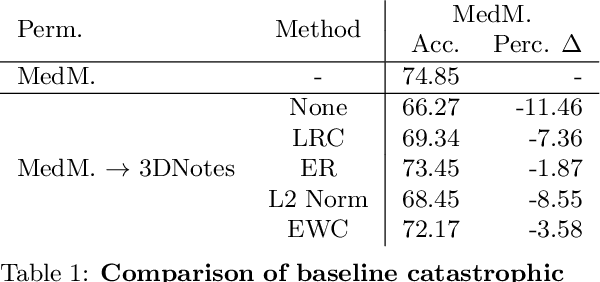

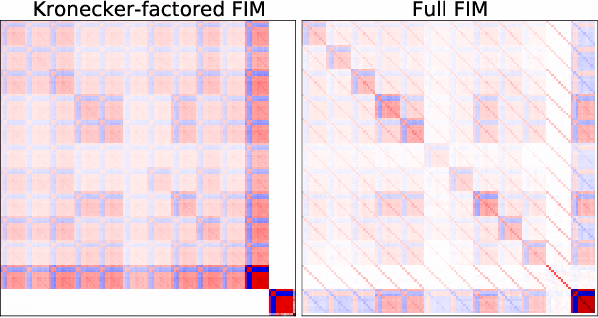
Multi-task learning is useful in NLP because it is often practically desirable to have a single model that works across a range of tasks. In the medical domain, sequential training on tasks may sometimes be the only way to train models, either because access to the original (potentially sensitive) data is no longer available, or simply owing to the computational costs inherent to joint retraining. A major issue inherent to sequential learning, however, is catastrophic forgetting, i.e., a substantial drop in accuracy on prior tasks when a model is updated for a new task. Elastic Weight Consolidation is a recently proposed method to address this issue, but scaling this approach to the modern large models used in practice requires making strong independence assumptions about model parameters, limiting its effectiveness. In this work, we apply Kronecker Factorization--a recent approach that relaxes independence assumptions--to prevent catastrophic forgetting in convolutional and Transformer-based neural networks at scale. We show the effectiveness of this technique on the important and illustrative task of medical entity linking across three datasets, demonstrating the capability of the technique to be used to make efficient updates to existing methods as new medical data becomes available. On average, the proposed method reduces catastrophic forgetting by 51% when using a BERT-based model, compared to a 27% reduction using standard Elastic Weight Consolidation, while maintaining spatial complexity proportional to the number of model parameters.
Syntactic Patterns Improve Information Extraction for Medical Search
Apr 30, 2018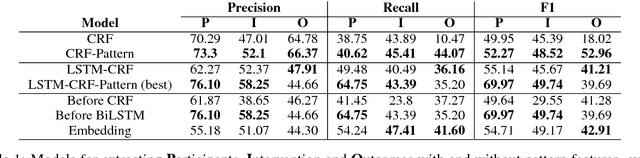
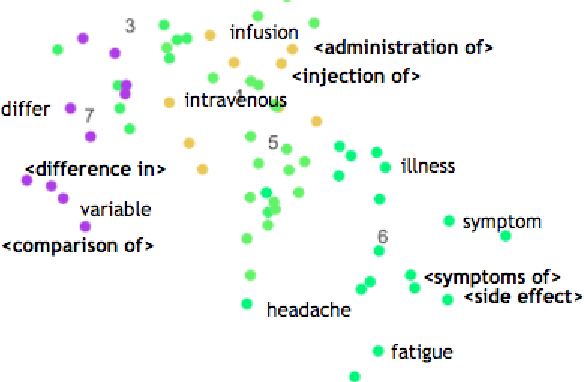


Medical professionals search the published literature by specifying the type of patients, the medical intervention(s) and the outcome measure(s) of interest. In this paper we demonstrate how features encoding syntactic patterns improve the performance of state-of-the-art sequence tagging models (both linear and neural) for information extraction of these medically relevant categories. We present an analysis of the type of patterns exploited, and the semantic space induced for these, i.e., the distributed representations learned for identified multi-token patterns. We show that these learned representations differ substantially from those of the constituent unigrams, suggesting that the patterns capture contextual information that is otherwise lost.
A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification
Apr 06, 2016


Convolutional Neural Networks (CNNs) have recently achieved remarkably strong performance on the practically important task of sentence classification (kim 2014, kalchbrenner 2014, johnson 2014). However, these models require practitioners to specify an exact model architecture and set accompanying hyperparameters, including the filter region size, regularization parameters, and so on. It is currently unknown how sensitive model performance is to changes in these configurations for the task of sentence classification. We thus conduct a sensitivity analysis of one-layer CNNs to explore the effect of architecture components on model performance; our aim is to distinguish between important and comparatively inconsequential design decisions for sentence classification. We focus on one-layer CNNs (to the exclusion of more complex models) due to their comparative simplicity and strong empirical performance, which makes it a modern standard baseline method akin to Support Vector Machine (SVMs) and logistic regression. We derive practical advice from our extensive empirical results for those interested in getting the most out of CNNs for sentence classification in real world settings.
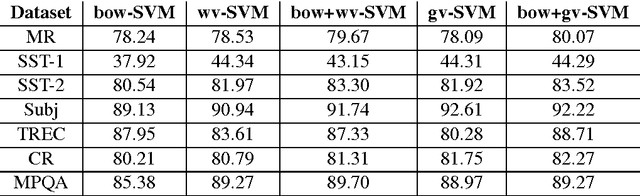
MGNC-CNN: A Simple Approach to Exploiting Multiple Word Embeddings for Sentence Classification
Mar 27, 2016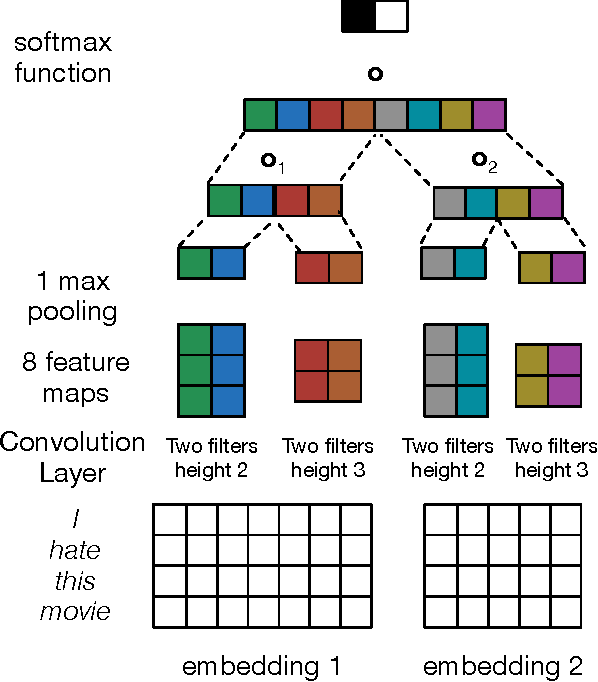

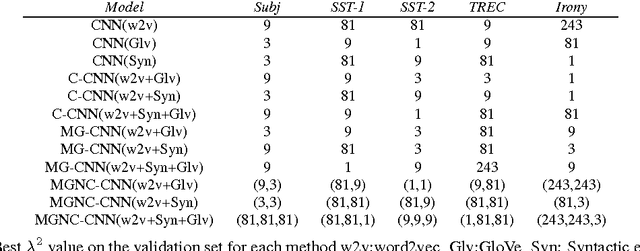
We introduce a novel, simple convolution neural network (CNN) architecture - multi-group norm constraint CNN (MGNC-CNN) that capitalizes on multiple sets of word embeddings for sentence classification. MGNC-CNN extracts features from input embedding sets independently and then joins these at the penultimate layer in the network to form a final feature vector. We then adopt a group regularization strategy that differentially penalizes weights associated with the subcomponents generated from the respective embedding sets. This model is much simpler than comparable alternative architectures and requires substantially less training time. Furthermore, it is flexible in that it does not require input word embeddings to be of the same dimensionality. We show that MGNC-CNN consistently outperforms baseline models.
Graph-Sparse LDA: A Topic Model with Structured Sparsity
Nov 21, 2014



Originally designed to model text, topic modeling has become a powerful tool for uncovering latent structure in domains including medicine, finance, and vision. The goals for the model vary depending on the application: in some cases, the discovered topics may be used for prediction or some other downstream task. In other cases, the content of the topic itself may be of intrinsic scientific interest. Unfortunately, even using modern sparse techniques, the discovered topics are often difficult to interpret due to the high dimensionality of the underlying space. To improve topic interpretability, we introduce Graph-Sparse LDA, a hierarchical topic model that leverages knowledge of relationships between words (e.g., as encoded by an ontology). In our model, topics are summarized by a few latent concept-words from the underlying graph that explain the observed words. Graph-Sparse LDA recovers sparse, interpretable summaries on two real-world biomedical datasets while matching state-of-the-art prediction performance.