 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKronecker Factorization for Preventing Catastrophic Forgetting in Large-scale Medical Entity Linking
Paper and Code
Nov 11, 2021
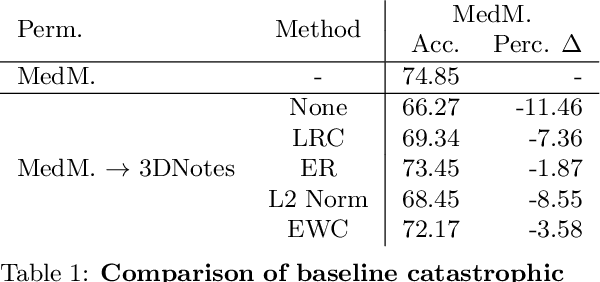

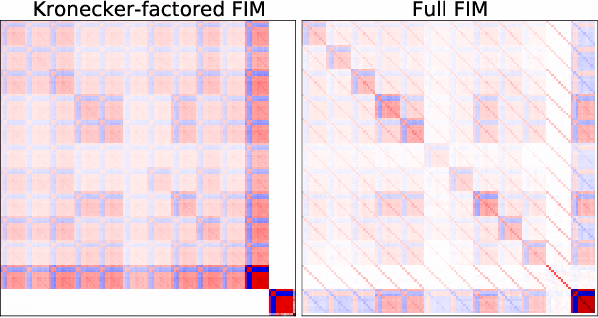
Multi-task learning is useful in NLP because it is often practically desirable to have a single model that works across a range of tasks. In the medical domain, sequential training on tasks may sometimes be the only way to train models, either because access to the original (potentially sensitive) data is no longer available, or simply owing to the computational costs inherent to joint retraining. A major issue inherent to sequential learning, however, is catastrophic forgetting, i.e., a substantial drop in accuracy on prior tasks when a model is updated for a new task. Elastic Weight Consolidation is a recently proposed method to address this issue, but scaling this approach to the modern large models used in practice requires making strong independence assumptions about model parameters, limiting its effectiveness. In this work, we apply Kronecker Factorization--a recent approach that relaxes independence assumptions--to prevent catastrophic forgetting in convolutional and Transformer-based neural networks at scale. We show the effectiveness of this technique on the important and illustrative task of medical entity linking across three datasets, demonstrating the capability of the technique to be used to make efficient updates to existing methods as new medical data becomes available. On average, the proposed method reduces catastrophic forgetting by 51% when using a BERT-based model, compared to a 27% reduction using standard Elastic Weight Consolidation, while maintaining spatial complexity proportional to the number of model parameters.