 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Encoder Architectures for Fast Real-Time Long Conversational Understanding
Feb 18, 2025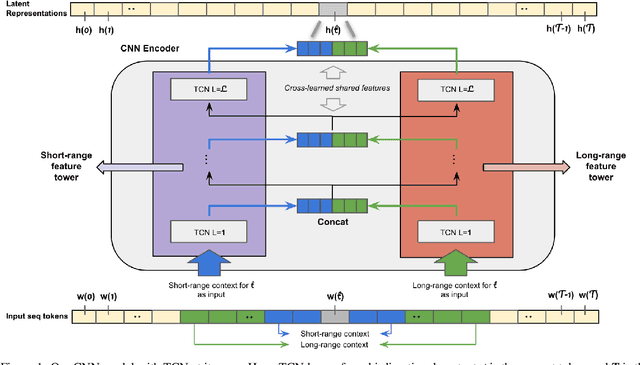
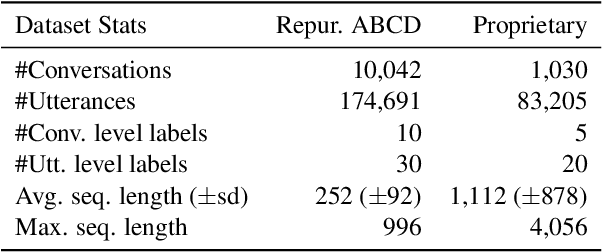
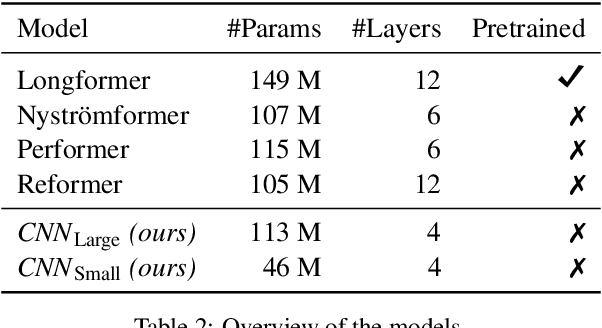
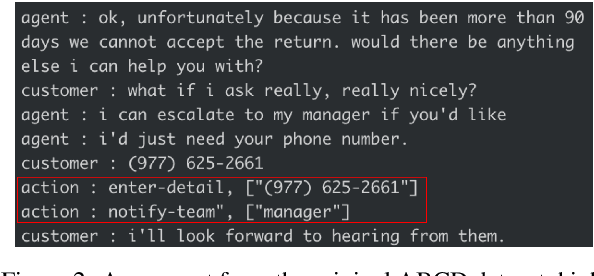
Analyzing long text data such as customer call transcripts is a cost-intensive and tedious task. Machine learning methods, namely Transformers, are leveraged to model agent-customer interactions. Unfortunately, Transformers adhere to fixed-length architectures and their self-attention mechanism scales quadratically with input length. Such limitations make it challenging to leverage traditional Transformers for long sequence tasks, such as conversational understanding, especially in real-time use cases. In this paper we explore and evaluate recently proposed efficient Transformer variants (e.g. Performer, Reformer) and a CNN-based architecture for real-time and near real-time long conversational understanding tasks. We show that CNN-based models are dynamic, ~2.6x faster to train, ~80% faster inference and ~72% more memory efficient compared to Transformers on average. Additionally, we evaluate the CNN model using the Long Range Arena benchmark to demonstrate competitiveness in general long document analysis.
Kronecker Factorization for Preventing Catastrophic Forgetting in Large-scale Medical Entity Linking
Nov 11, 2021
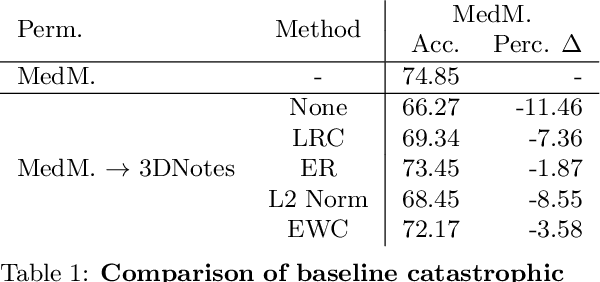

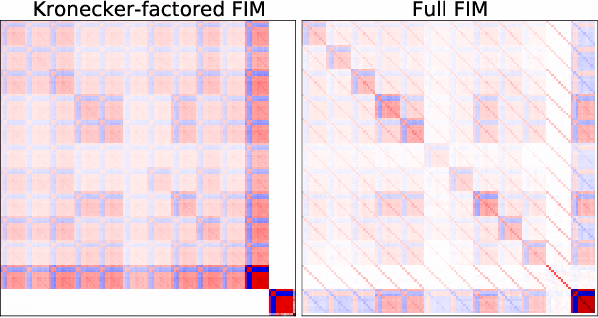
Multi-task learning is useful in NLP because it is often practically desirable to have a single model that works across a range of tasks. In the medical domain, sequential training on tasks may sometimes be the only way to train models, either because access to the original (potentially sensitive) data is no longer available, or simply owing to the computational costs inherent to joint retraining. A major issue inherent to sequential learning, however, is catastrophic forgetting, i.e., a substantial drop in accuracy on prior tasks when a model is updated for a new task. Elastic Weight Consolidation is a recently proposed method to address this issue, but scaling this approach to the modern large models used in practice requires making strong independence assumptions about model parameters, limiting its effectiveness. In this work, we apply Kronecker Factorization--a recent approach that relaxes independence assumptions--to prevent catastrophic forgetting in convolutional and Transformer-based neural networks at scale. We show the effectiveness of this technique on the important and illustrative task of medical entity linking across three datasets, demonstrating the capability of the technique to be used to make efficient updates to existing methods as new medical data becomes available. On average, the proposed method reduces catastrophic forgetting by 51% when using a BERT-based model, compared to a 27% reduction using standard Elastic Weight Consolidation, while maintaining spatial complexity proportional to the number of model parameters.
An Empirical Investigation Towards Efficient Multi-Domain Language Model Pre-training
Oct 01, 2020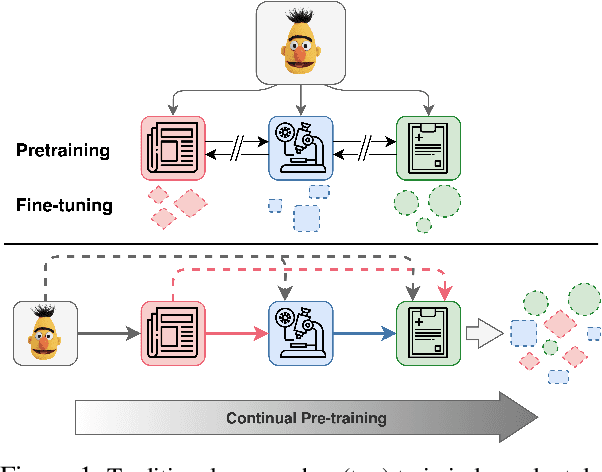
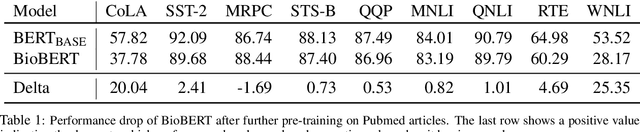
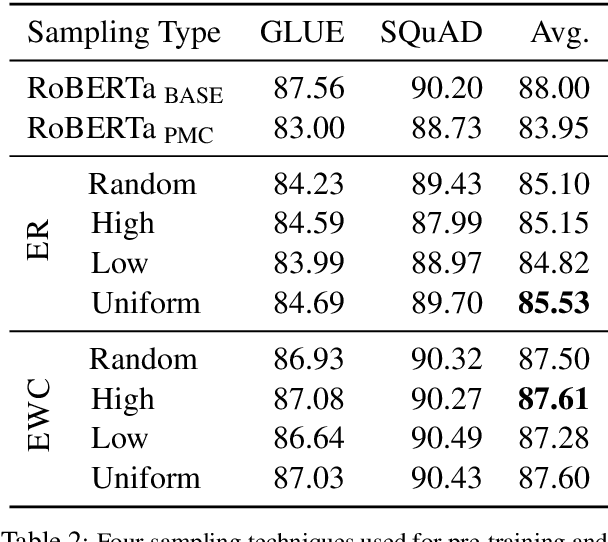
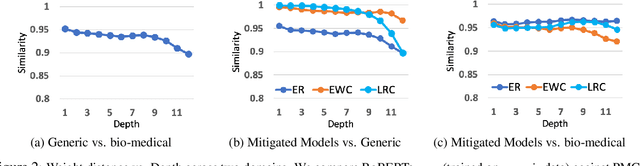
Pre-training large language models has become a standard in the natural language processing community. Such models are pre-trained on generic data (e.g. BookCorpus and English Wikipedia) and often fine-tuned on tasks in the same domain. However, in order to achieve state-of-the-art performance on out of domain tasks such as clinical named entity recognition and relation extraction, additional in domain pre-training is required. In practice, staged multi-domain pre-training presents performance deterioration in the form of catastrophic forgetting (CF) when evaluated on a generic benchmark such as GLUE. In this paper we conduct an empirical investigation into known methods to mitigate CF. We find that elastic weight consolidation provides best overall scores yielding only a 0.33% drop in performance across seven generic tasks while remaining competitive in bio-medical tasks. Furthermore, we explore gradient and latent clustering based data selection techniques to improve coverage when using elastic weight consolidation and experience replay methods.
CALM: Continuous Adaptive Learning for Language Modeling
Apr 08, 2020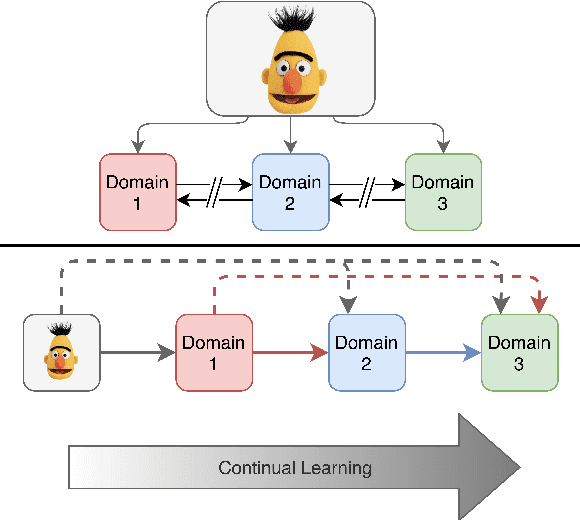

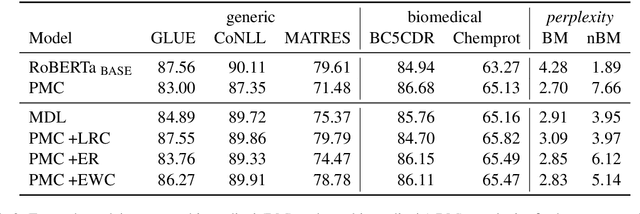
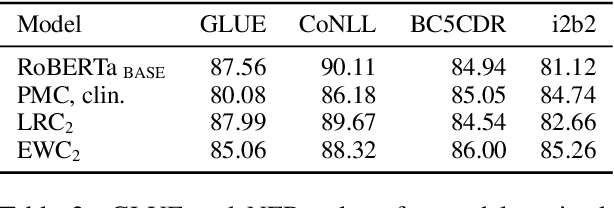
Training large language representation models has become a standard in the natural language processing community. This allows for fine tuning on any number of specific tasks, however, these large high capacity models can continue to train on domain specific unlabeled data to make initialization even more robust for supervised tasks. We demonstrate that in practice these pre-trained models present performance deterioration in the form of catastrophic forgetting when evaluated on tasks from a general domain such as GLUE. In this work we propose CALM, Continuous Adaptive Learning for Language Modeling: techniques to render models which retain knowledge across multiple domains. With these methods, we are able to reduce the performance gap across supervised tasks introduced by task specific models which we demonstrate using a continual learning setting in biomedical and clinical domains.
Towards Annotating and Creating Sub-Sentence Summary Highlights
Oct 17, 2019

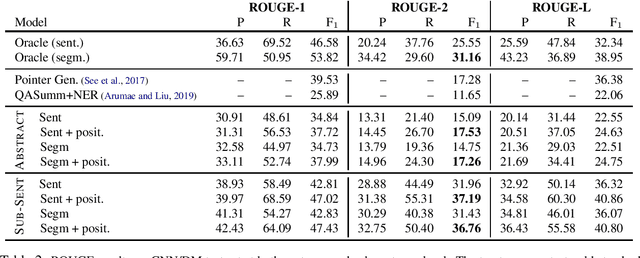
Highlighting is a powerful tool to pick out important content and emphasize. Creating summary highlights at the sub-sentence level is particularly desirable, because sub-sentences are more concise than whole sentences. They are also better suited than individual words and phrases that can potentially lead to disfluent, fragmented summaries. In this paper we seek to generate summary highlights by annotating summary-worthy sub-sentences and teaching classifiers to do the same. We frame the task as jointly selecting important sentences and identifying a single most informative textual unit from each sentence. This formulation dramatically reduces the task complexity involved in sentence compression. Our study provides new benchmarks and baselines for generating highlights at the sub-sentence level.
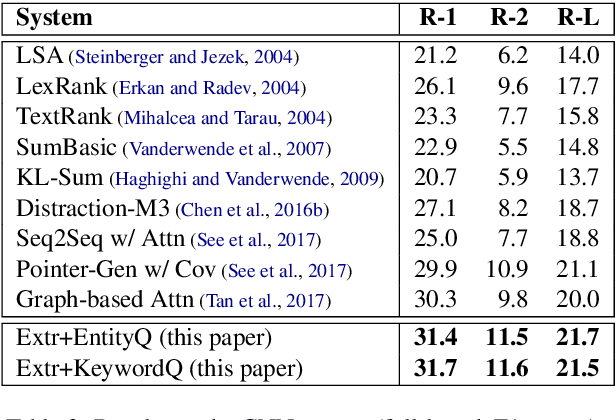
Guiding Extractive Summarization with Question-Answering Rewards
Apr 04, 2019
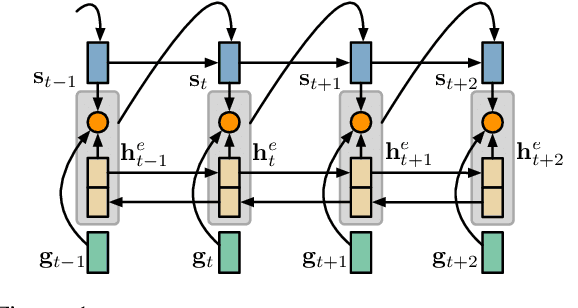
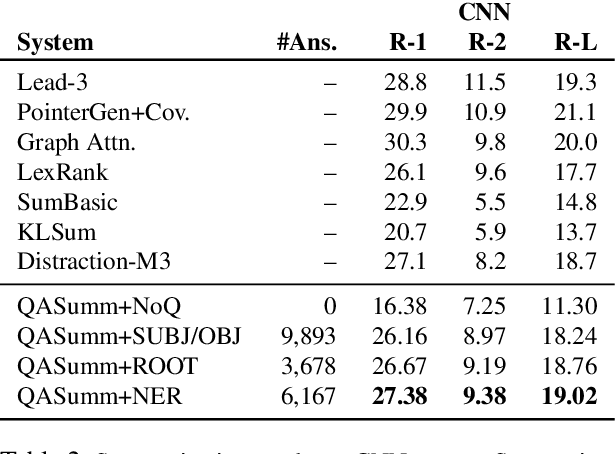

Highlighting while reading is a natural behavior for people to track salient content of a document. It would be desirable to teach an extractive summarizer to do the same. However, a major obstacle to the development of a supervised summarizer is the lack of ground-truth. Manual annotation of extraction units is cost-prohibitive, whereas acquiring labels by automatically aligning human abstracts and source documents can yield inferior results. In this paper we describe a novel framework to guide a supervised, extractive summarization system with question-answering rewards. We argue that quality summaries should serve as a document surrogate to answer important questions, and such question-answer pairs can be conveniently obtained from human abstracts. The system learns to promote summaries that are informative, fluent, and perform competitively on question-answering. Our results compare favorably with those reported by strong summarization baselines as evaluated by automatic metrics and human assessors.
Dynamic Transfer Learning for Named Entity Recognition
Jan 18, 2019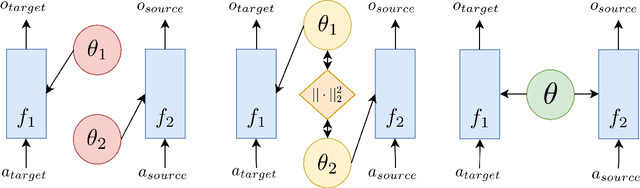
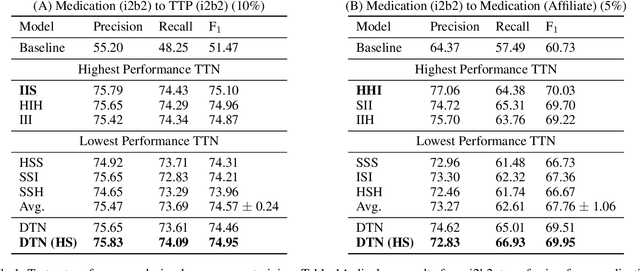
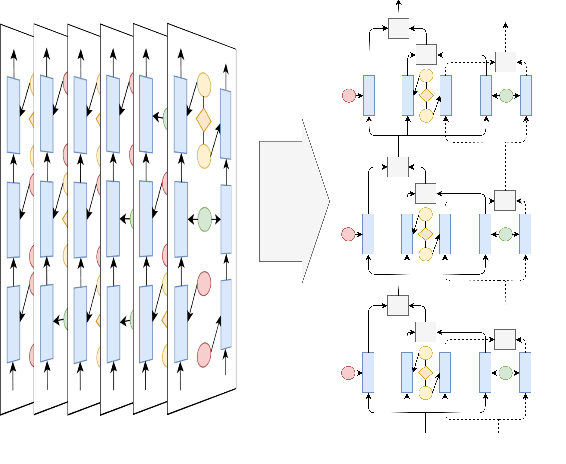
State-of-the-art named entity recognition (NER) systems have been improving continuously using neural architectures over the past several years. However, many tasks including NER require large sets of annotated data to achieve such performance. In particular, we focus on NER from clinical notes, which is one of the most fundamental and critical problems for medical text analysis. Our work centers on effectively adapting these neural architectures towards low-resource settings using parameter transfer methods. We complement a standard hierarchical NER model with a general transfer learning framework consisting of parameter sharing between the source and target tasks, and showcase scores significantly above the baseline architecture. These sharing schemes require an exponential search over tied parameter sets to generate an optimal configuration. To mitigate the problem of exhaustively searching for model optimization, we propose the Dynamic Transfer Networks (DTN), a gated architecture which learns the appropriate parameter sharing scheme between source and target datasets. DTN achieves the improvements of the optimized transfer learning framework with just a single training setting, effectively removing the need for exponential search.
Reinforced Extractive Summarization with Question-Focused Rewards
Jun 21, 2018


We investigate a new training paradigm for extractive summarization. Traditionally, human abstracts are used to derive goldstandard labels for extraction units. However, the labels are often inaccurate, because human abstracts and source documents cannot be easily aligned at the word level. In this paper we convert human abstracts to a set of Cloze-style comprehension questions. System summaries are encouraged to preserve salient source content useful for answering questions and share common words with the abstracts. We use reinforcement learning to explore the space of possible extractive summaries and introduce a question-focused reward function to promote concise, fluent, and informative summaries. Our experiments show that the proposed method is effective. It surpasses state-of-the-art systems on the standard summarization dataset.
A Study of Question Effectiveness Using Reddit "Ask Me Anything" Threads
May 25, 2018
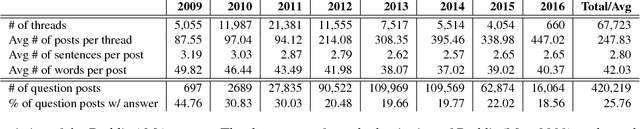
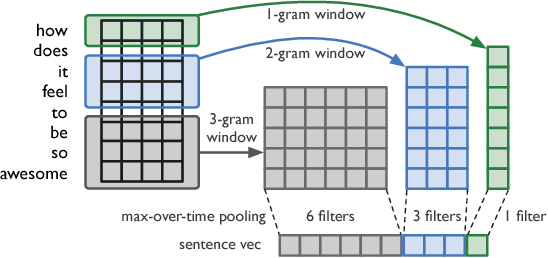
Asking effective questions is a powerful social skill. In this paper we seek to build computational models that learn to discriminate effective questions from ineffective ones. Armed with such a capability, future advanced systems can evaluate the quality of questions and provide suggestions for effective question wording. We create a large-scale, real-world dataset that contains over 400,000 questions collected from Reddit "Ask Me Anything" threads. Each thread resembles an online press conference where questions compete with each other for attention from the host. This dataset enables the development of a class of computational models for predicting whether a question will be answered. We develop a new convolutional neural network architecture with variable-length context and demonstrate the efficacy of the model by comparing it with state-of-the-art baselines and human judges.