 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Extractive Summarization with Question-Answering Rewards
Paper and Code

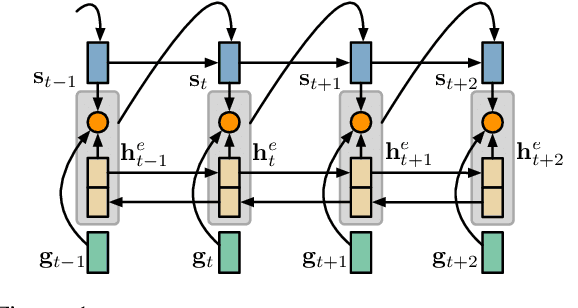
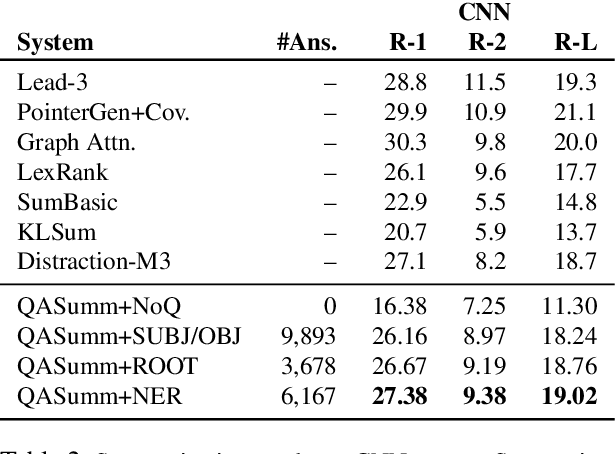

Highlighting while reading is a natural behavior for people to track salient content of a document. It would be desirable to teach an extractive summarizer to do the same. However, a major obstacle to the development of a supervised summarizer is the lack of ground-truth. Manual annotation of extraction units is cost-prohibitive, whereas acquiring labels by automatically aligning human abstracts and source documents can yield inferior results. In this paper we describe a novel framework to guide a supervised, extractive summarization system with question-answering rewards. We argue that quality summaries should serve as a document surrogate to answer important questions, and such question-answer pairs can be conveniently obtained from human abstracts. The system learns to promote summaries that are informative, fluent, and perform competitively on question-answering. Our results compare favorably with those reported by strong summarization baselines as evaluated by automatic metrics and human assessors.