 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIonCast: A Deep Learning Framework for Forecasting Ionospheric Dynamics
Nov 19, 2025The ionosphere is a critical component of near-Earth space, shaping GNSS accuracy, high-frequency communications, and aviation operations. For these reasons, accurate forecasting and modeling of ionospheric variability has become increasingly relevant. To address this gap, we present IonCast, a suite of deep learning models that include a GraphCast-inspired model tailored for ionospheric dynamics. IonCast leverages spatiotemporal learning to forecast global Total Electron Content (TEC), integrating diverse physical drivers and observational datasets. Validating on held-out storm-time and quiet conditions highlights improved skill compared to persistence. By unifying heterogeneous data with scalable graph-based spatiotemporal learning, IonCast demonstrates how machine learning can augment physical understanding of ionospheric variability and advance operational space weather resilience.
Question answering systems for health professionals at the point of care -- a systematic review
Jan 24, 2024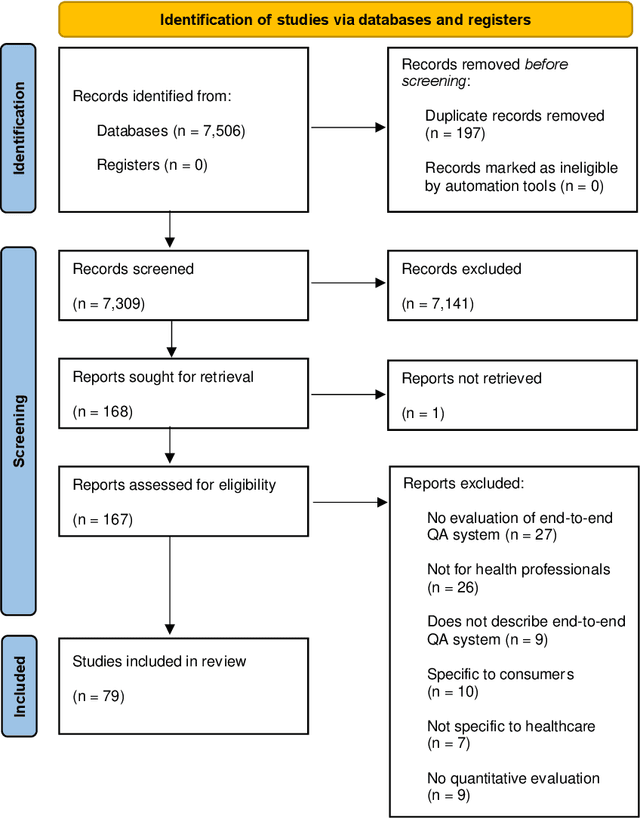
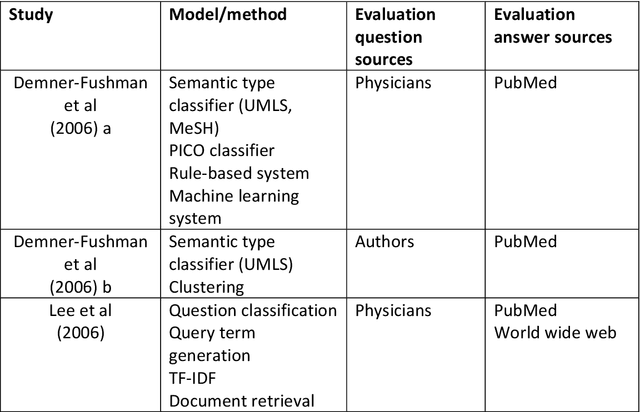
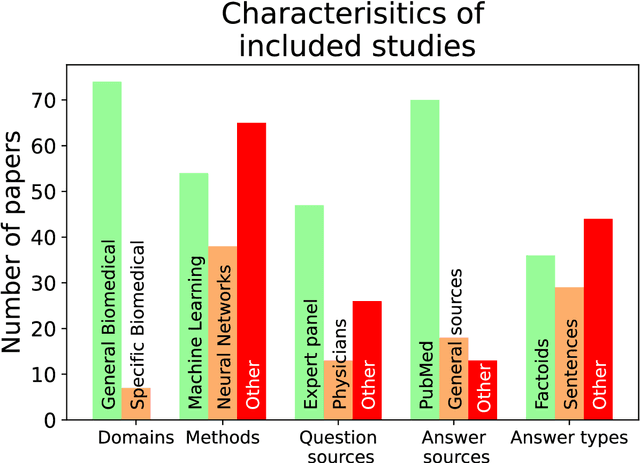

Objective: Question answering (QA) systems have the potential to improve the quality of clinical care by providing health professionals with the latest and most relevant evidence. However, QA systems have not been widely adopted. This systematic review aims to characterize current medical QA systems, assess their suitability for healthcare, and identify areas of improvement. Materials and methods: We searched PubMed, IEEE Xplore, ACM Digital Library, ACL Anthology and forward and backward citations on 7th February 2023. We included peer-reviewed journal and conference papers describing the design and evaluation of biomedical QA systems. Two reviewers screened titles, abstracts, and full-text articles. We conducted a narrative synthesis and risk of bias assessment for each study. We assessed the utility of biomedical QA systems. Results: We included 79 studies and identified themes, including question realism, answer reliability, answer utility, clinical specialism, systems, usability, and evaluation methods. Clinicians' questions used to train and evaluate QA systems were restricted to certain sources, types and complexity levels. No system communicated confidence levels in the answers or sources. Many studies suffered from high risks of bias and applicability concerns. Only 8 studies completely satisfied any criterion for clinical utility, and only 7 reported user evaluations. Most systems were built with limited input from clinicians. Discussion: While machine learning methods have led to increased accuracy, most studies imperfectly reflected real-world healthcare information needs. Key research priorities include developing more realistic healthcare QA datasets and considering the reliability of answer sources, rather than merely focusing on accuracy.
Beyond Low Earth Orbit: Biomonitoring, Artificial Intelligence, and Precision Space Health
Dec 22, 2021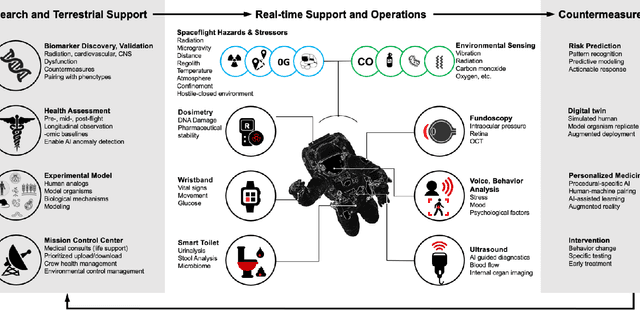
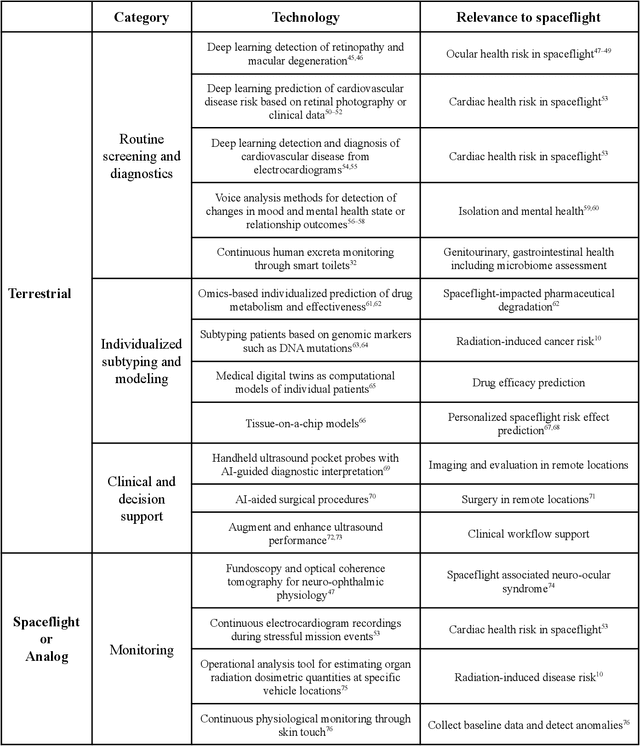
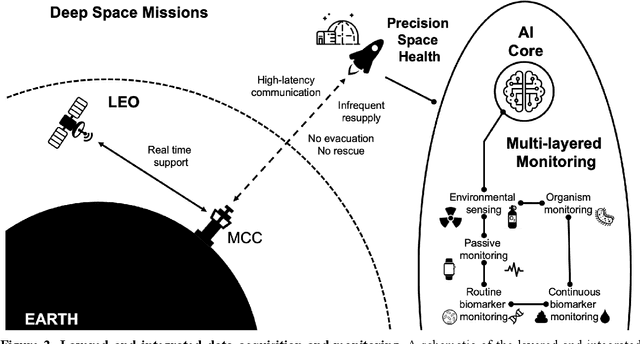
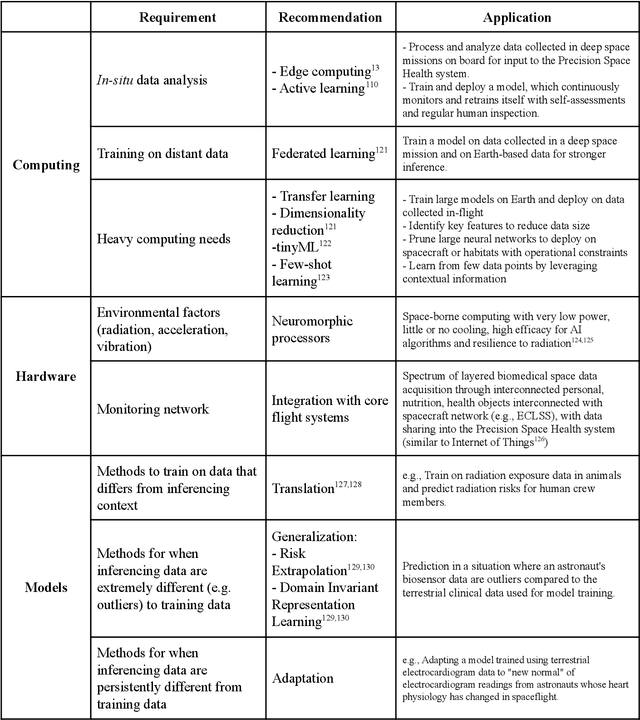
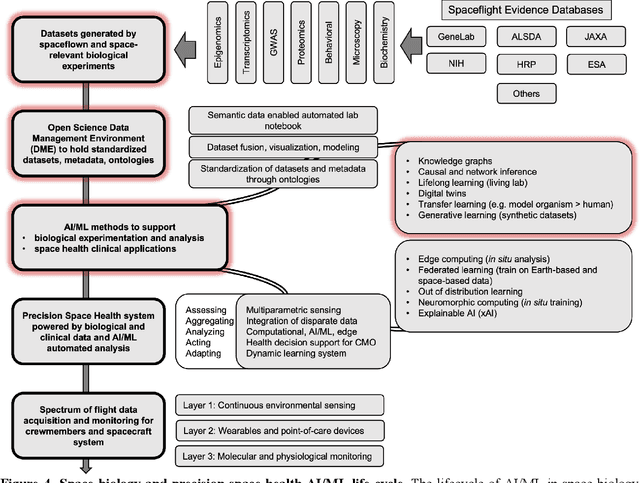
Human space exploration beyond low Earth orbit will involve missions of significant distance and duration. To effectively mitigate myriad space health hazards, paradigm shifts in data and space health systems are necessary to enable Earth-independence, rather than Earth-reliance. Promising developments in the fields of artificial intelligence and machine learning for biology and health can address these needs. We propose an appropriately autonomous and intelligent Precision Space Health system that will monitor, aggregate, and assess biomedical statuses; analyze and predict personalized adverse health outcomes; adapt and respond to newly accumulated data; and provide preventive, actionable, and timely insights to individual deep space crew members and iterative decision support to their crew medical officer. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration, on future applications of artificial intelligence in space biology and health. In the next decade, biomonitoring technology, biomarker science, spacecraft hardware, intelligent software, and streamlined data management must mature and be woven together into a Precision Space Health system to enable humanity to thrive in deep space.
Beyond Low Earth Orbit: Biological Research, Artificial Intelligence, and Self-Driving Labs
Dec 22, 2021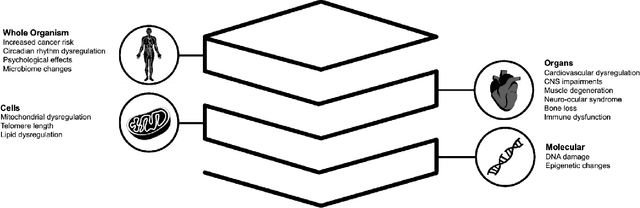
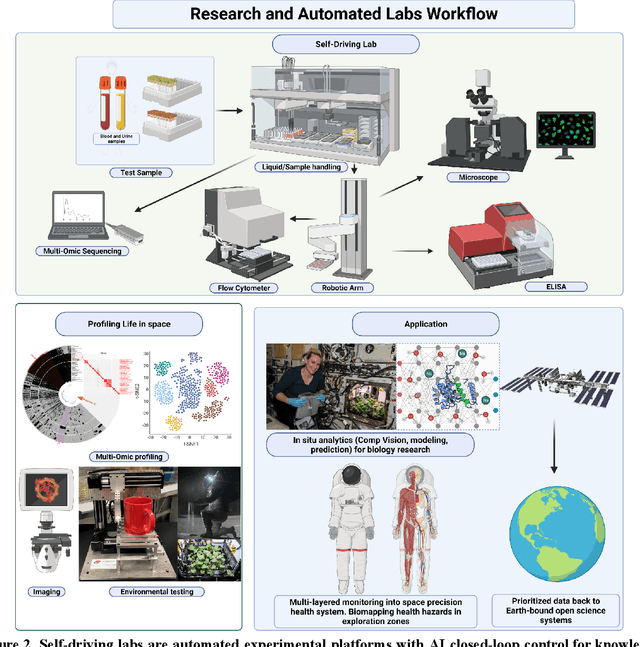
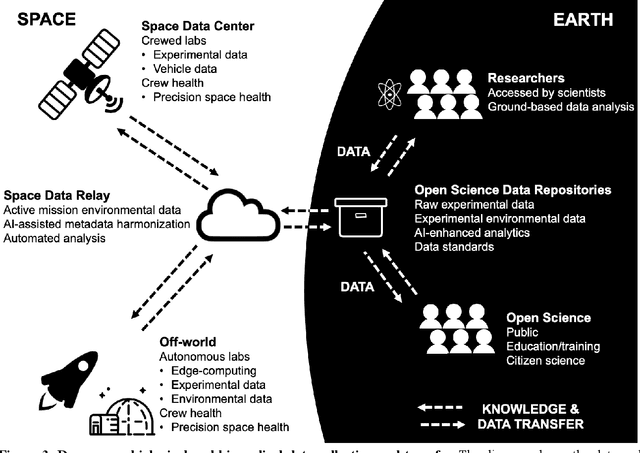
Space biology research aims to understand fundamental effects of spaceflight on organisms, develop foundational knowledge to support deep space exploration, and ultimately bioengineer spacecraft and habitats to stabilize the ecosystem of plants, crops, microbes, animals, and humans for sustained multi-planetary life. To advance these aims, the field leverages experiments, platforms, data, and model organisms from both spaceborne and ground-analog studies. As research is extended beyond low Earth orbit, experiments and platforms must be maximally autonomous, light, agile, and intelligent to expedite knowledge discovery. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration on artificial intelligence, machine learning, and modeling applications which offer key solutions toward these space biology challenges. In the next decade, the synthesis of artificial intelligence into the field of space biology will deepen the biological understanding of spaceflight effects, facilitate predictive modeling and analytics, support maximally autonomous and reproducible experiments, and efficiently manage spaceborne data and metadata, all with the goal to enable life to thrive in deep space.
Invariant Risk Minimisation for Cross-Organism Inference: Substituting Mouse Data for Human Data in Human Risk Factor Discovery
Nov 14, 2021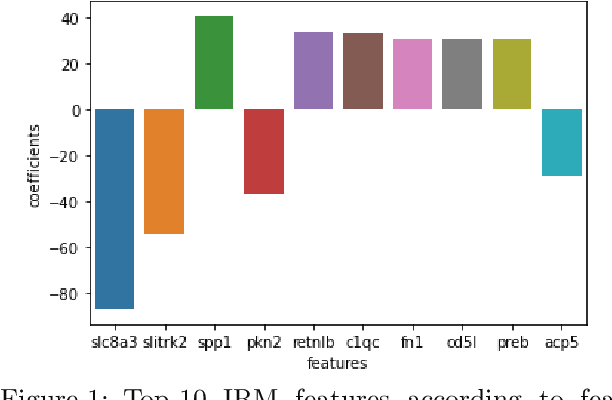
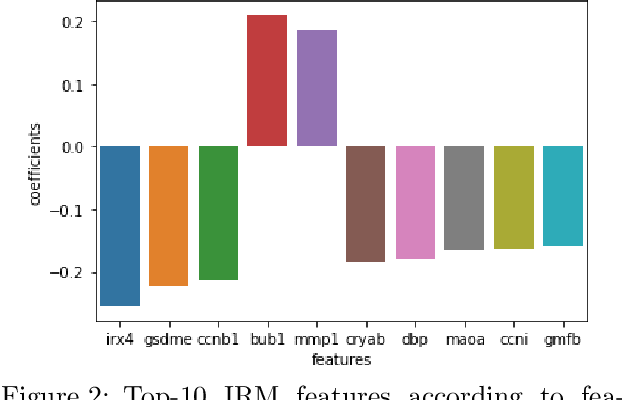
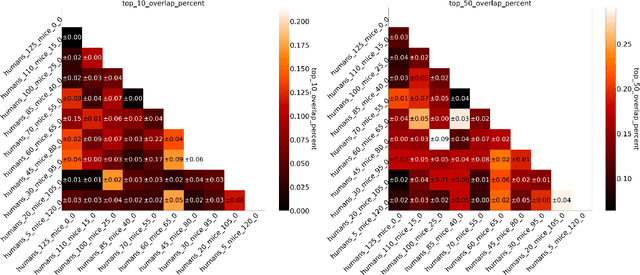
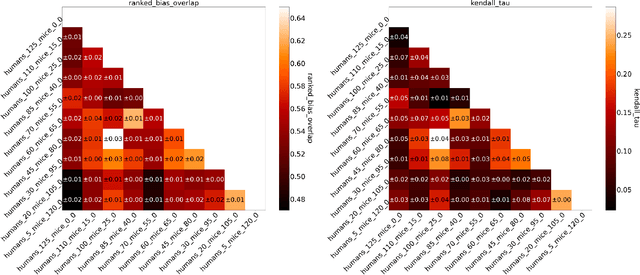
Human medical data can be challenging to obtain due to data privacy concerns, difficulties conducting certain types of experiments, or prohibitive associated costs. In many settings, data from animal models or in-vitro cell lines are available to help augment our understanding of human data. However, this data is known for having low etiological validity in comparison to human data. In this work, we augment small human medical datasets with in-vitro data and animal models. We use Invariant Risk Minimisation (IRM) to elucidate invariant features by considering cross-organism data as belonging to different data-generating environments. Our models identify genes of relevance to human cancer development. We observe a degree of consistency between varying the amounts of human and mouse data used, however, further work is required to obtain conclusive insights. As a secondary contribution, we enhance existing open source datasets and provide two uniformly processed, cross-organism, homologue gene-matched datasets to the community.
On Invariance Penalties for Risk Minimization
Jun 17, 2021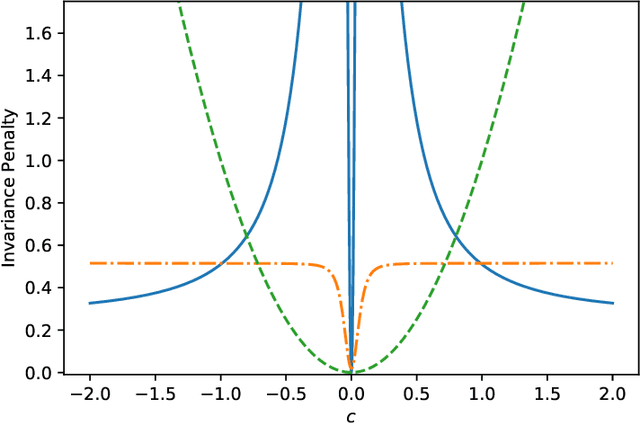
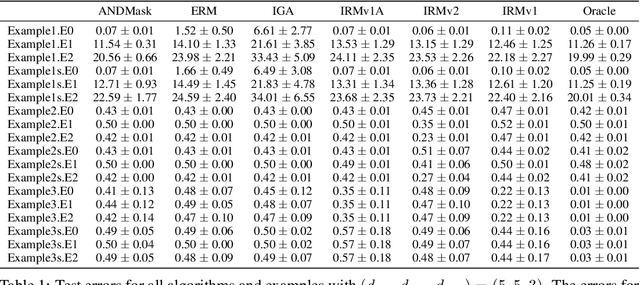

The Invariant Risk Minimization (IRM) principle was first proposed by Arjovsky et al. [2019] to address the domain generalization problem by leveraging data heterogeneity from differing experimental conditions. Specifically, IRM seeks to find a data representation under which an optimal classifier remains invariant across all domains. Despite the conceptual appeal of IRM, the effectiveness of the originally proposed invariance penalty has recently been brought into question. In particular, there exists counterexamples for which that invariance penalty can be arbitrarily small for non-invariant data representations. We propose an alternative invariance penalty by revisiting the Gramian matrix of the data representation. We discuss the role of its eigenvalues in the relationship between the risk and the invariance penalty, and demonstrate that it is ill-conditioned for said counterexamples. The proposed approach is guaranteed to recover an invariant representation for linear settings under mild non-degeneracy conditions. Its effectiveness is substantiated by experiments on DomainBed and InvarianceUnitTest, two extensive test beds for domain generalization.
Next-Gen Machine Learning Supported Diagnostic Systems for Spacecraft
Jun 10, 2021Future short or long-term space missions require a new generation of monitoring and diagnostic systems due to communication impasses as well as limitations in specialized crew and equipment. Machine learning supported diagnostic systems present a viable solution for medical and technical applications. We discuss challenges and applicability of such systems in light of upcoming missions and outline an example use case for a next-generation medical diagnostic system for future space operations. Additionally, we present approach recommendations and constraints for the successful generation and use of machine learning models aboard a spacecraft.
Generating (Factual?) Narrative Summaries of RCTs: Experiments with Neural Multi-Document Summarization
Aug 25, 2020


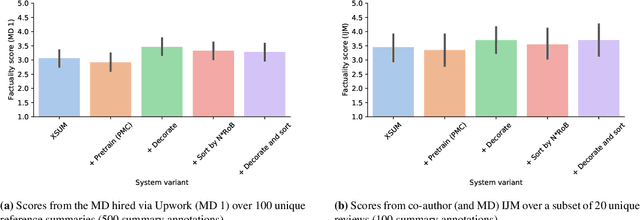
We consider the problem of automatically generating a narrative biomedical evidence summary from multiple trial reports. We evaluate modern neural models for abstractive summarization of relevant article abstracts from systematic reviews previously conducted by members of the Cochrane collaboration, using the authors conclusions section of the review abstract as our target. We enlist medical professionals to evaluate generated summaries, and we find that modern summarization systems yield consistently fluent and relevant synopses, but that they are not always factual. We propose new approaches that capitalize on domain-specific models to inform summarization, e.g., by explicitly demarcating snippets of inputs that convey key findings, and emphasizing the reports of large and high-quality trials. We find that these strategies modestly improve the factual accuracy of generated summaries. Finally, we propose a new method for automatically evaluating the factuality of generated narrative evidence syntheses using models that infer the directionality of reported findings.
An Ensemble of Bayesian Neural Networks for Exoplanetary Atmospheric Retrieval
May 25, 2019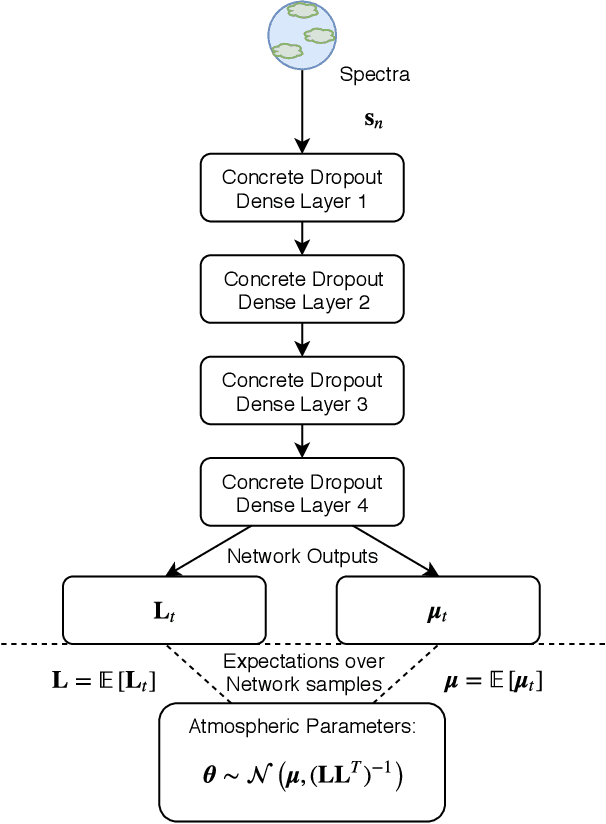
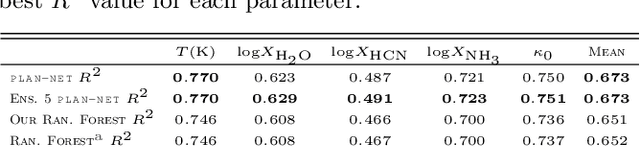
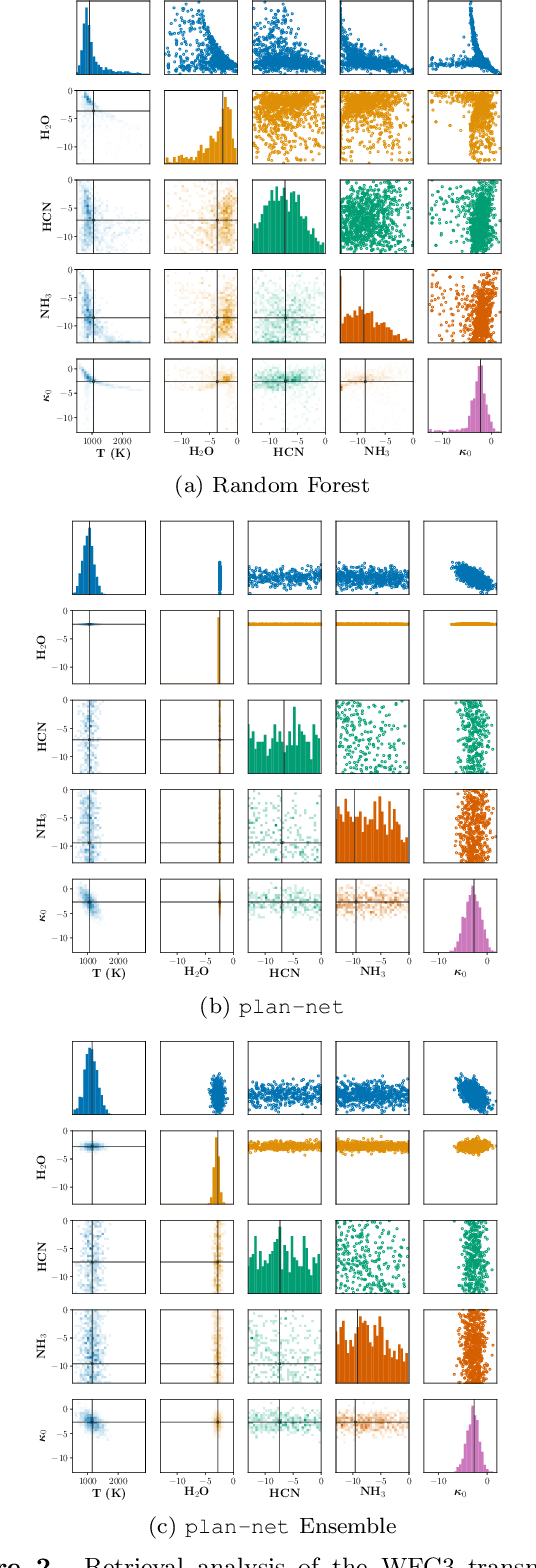

Machine learning is now used in many areas of astrophysics, from detecting exoplanets in Kepler transit signals to removing telescope systematics. Recent work demonstrated the potential of using machine learning algorithms for atmospheric retrieval by implementing a random forest to perform retrievals in seconds that are consistent with the traditional, computationally-expensive nested-sampling retrieval method. We expand upon their approach by presenting a new machine learning model, \texttt{plan-net}, based on an ensemble of Bayesian neural networks that yields more accurate inferences than the random forest for the same data set of synthetic transmission spectra. We demonstrate that an ensemble provides greater accuracy and more robust uncertainties than a single model. In addition to being the first to use Bayesian neural networks for atmospheric retrieval, we also introduce a new loss function for Bayesian neural networks that learns correlations between the model outputs. Importantly, we show that designing machine learning models to explicitly incorporate domain-specific knowledge both improves performance and provides additional insight by inferring the covariance of the retrieved atmospheric parameters. We apply \texttt{plan-net} to the Hubble Space Telescope Wide Field Camera 3 transmission spectrum for WASP-12b and retrieve an isothermal temperature and water abundance consistent with the literature. We highlight that our method is flexible and can be expanded to higher-resolution spectra and a larger number of atmospheric parameters.
Bayesian Deep Learning for Exoplanet Atmospheric Retrieval
Dec 02, 2018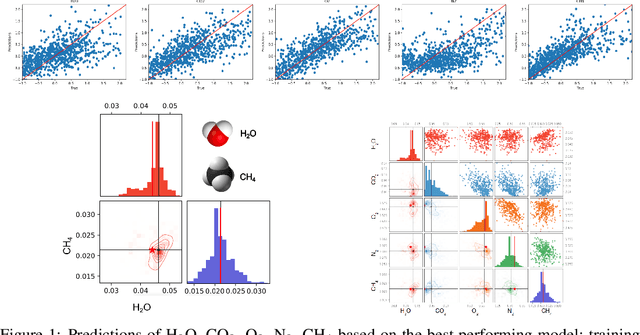

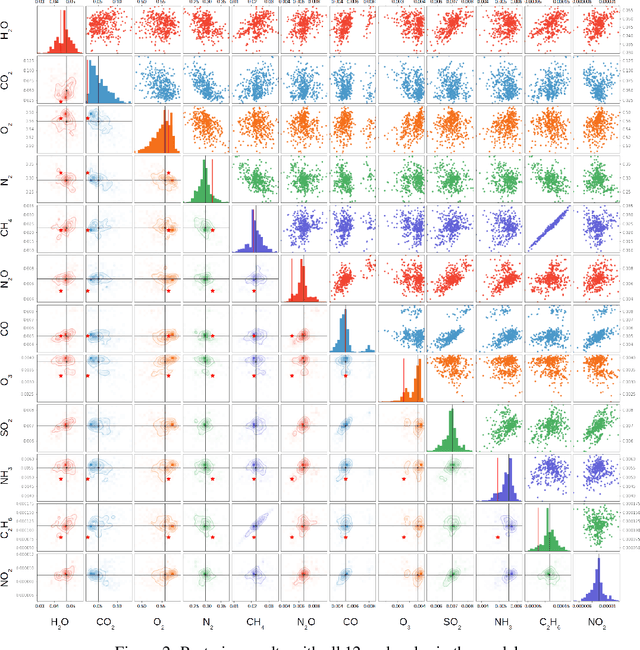
Over the past decade, the study of extrasolar planets has evolved rapidly from plain detection and identification to comprehensive categorization and characterization of exoplanet systems and their atmospheres. Atmospheric retrieval, the inverse modeling technique used to determine an exoplanetary atmosphere's temperature structure and composition from an observed spectrum, is both time-consuming and compute-intensive, requiring complex algorithms that compare thousands to millions of atmospheric models to the observational data to find the most probable values and associated uncertainties for each model parameter. For rocky, terrestrial planets, the retrieved atmospheric composition can give insight into the surface fluxes of gaseous species necessary to maintain the stability of that atmosphere, which may in turn provide insight into the geological and/or biological processes active on the planet. These atmospheres contain many molecules, some of them biosignatures, spectral fingerprints indicative of biological activity, which will become observable with the next generation of telescopes. Runtimes of traditional retrieval models scale with the number of model parameters, so as more molecular species are considered, runtimes can become prohibitively long. Recent advances in machine learning (ML) and computer vision offer new ways to reduce the time to perform a retrieval by orders of magnitude, given a sufficient data set to train with. Here we present an ML-based retrieval framework called Intelligent exoplaNet Atmospheric RetrievAl (INARA) that consists of a Bayesian deep learning model for retrieval and a data set of 3,000,000 synthetic rocky exoplanetary spectra generated using the NASA Planetary Spectrum Generator. Our work represents the first ML retrieval model for rocky, terrestrial exoplanets and the first synthetic data set of terrestrial spectra generated at this scale.