 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot LoRA Adaptation of a Flow-Matching Foundation Model for Cross-Spectral Object Detection
Jan 07, 2026Foundation models for vision are predominantly trained on RGB data, while many safety-critical applications rely on non-visible modalities such as infrared (IR) and synthetic aperture radar (SAR). We study whether a single flow-matching foundation model pre-trained primarily on RGB images can be repurposed as a cross-spectral translator using only a few co-measured examples, and whether the resulting synthetic data can enhance downstream detection. Starting from FLUX.1 Kontext, we insert low-rank adaptation (LoRA) modules and fine-tune them on just 100 paired images per domain for two settings: RGB to IR on the KAIST dataset and RGB to SAR on the M4-SAR dataset. The adapted model translates RGB images into pixel-aligned IR/SAR, enabling us to reuse existing bounding boxes and train object detection models purely in the target modality. Across a grid of LoRA hyperparameters, we find that LPIPS computed on only 50 held-out pairs is a strong proxy for downstream performance: lower LPIPS consistently predicts higher mAP for YOLOv11n on both IR and SAR, and for DETR on KAIST IR test data. Using the best LPIPS-selected LoRA adapter, synthetic IR from external RGB datasets (LLVIP, FLIR ADAS) improves KAIST IR pedestrian detection, and synthetic SAR significantly boosts infrastructure detection on M4-SAR when combined with limited real SAR. Our results suggest that few-shot LoRA adaptation of flow-matching foundation models is a promising path toward foundation-style support for non-visible modalities.
CausalARC: Abstract Reasoning with Causal World Models
Sep 03, 2025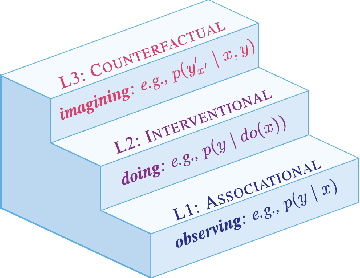


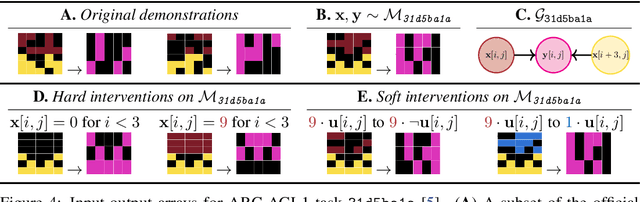
Reasoning requires adaptation to novel problem settings under limited data and distribution shift. This work introduces CausalARC: an experimental testbed for AI reasoning in low-data and out-of-distribution regimes, modeled after the Abstraction and Reasoning Corpus (ARC). Each CausalARC reasoning task is sampled from a fully specified causal world model, formally expressed as a structural causal model. Principled data augmentations provide observational, interventional, and counterfactual feedback about the world model in the form of few-shot, in-context learning demonstrations. As a proof-of-concept, we illustrate the use of CausalARC for four language model evaluation settings: (1) abstract reasoning with test-time training, (2) counterfactual reasoning with in-context learning, (3) program synthesis, and (4) causal discovery with logical reasoning.
Beyond Low Earth Orbit: Biomonitoring, Artificial Intelligence, and Precision Space Health
Dec 22, 2021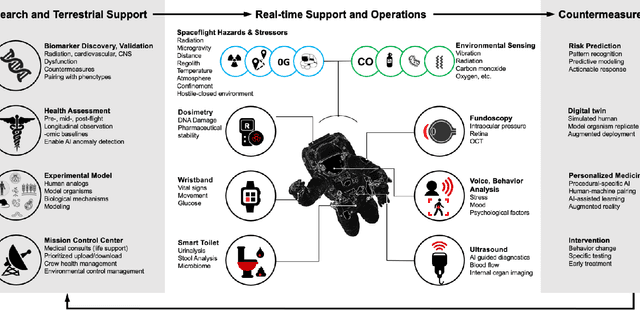
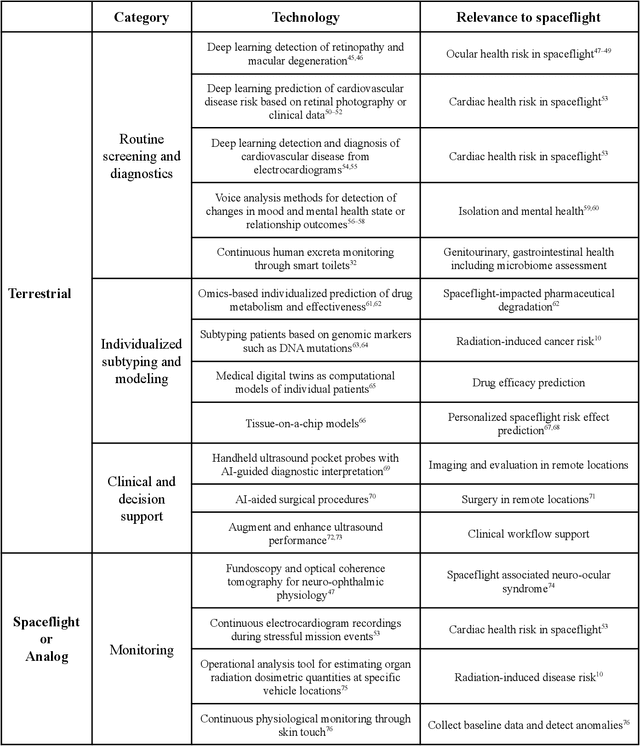
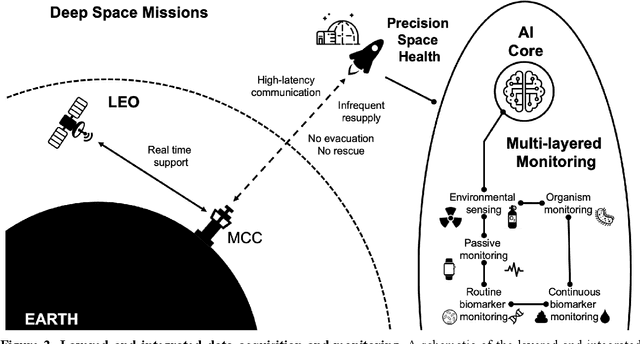
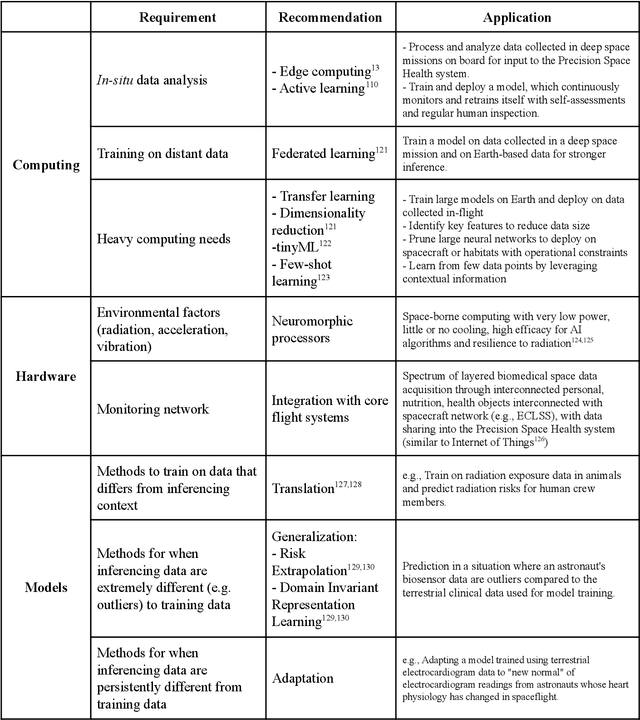
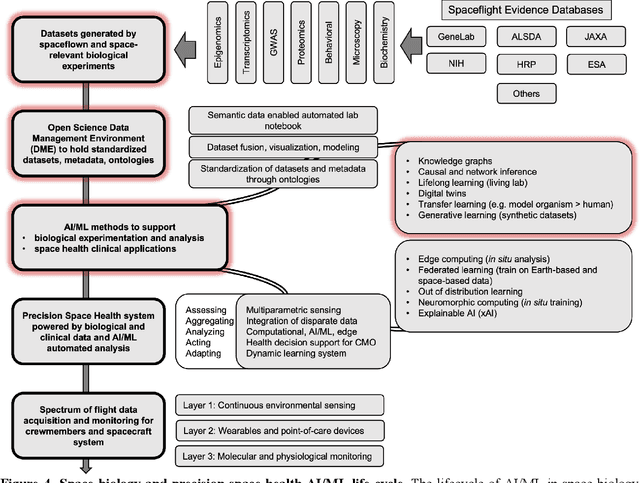
Human space exploration beyond low Earth orbit will involve missions of significant distance and duration. To effectively mitigate myriad space health hazards, paradigm shifts in data and space health systems are necessary to enable Earth-independence, rather than Earth-reliance. Promising developments in the fields of artificial intelligence and machine learning for biology and health can address these needs. We propose an appropriately autonomous and intelligent Precision Space Health system that will monitor, aggregate, and assess biomedical statuses; analyze and predict personalized adverse health outcomes; adapt and respond to newly accumulated data; and provide preventive, actionable, and timely insights to individual deep space crew members and iterative decision support to their crew medical officer. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration, on future applications of artificial intelligence in space biology and health. In the next decade, biomonitoring technology, biomarker science, spacecraft hardware, intelligent software, and streamlined data management must mature and be woven together into a Precision Space Health system to enable humanity to thrive in deep space.
Beyond Low Earth Orbit: Biological Research, Artificial Intelligence, and Self-Driving Labs
Dec 22, 2021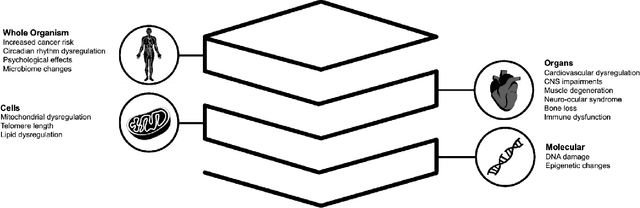
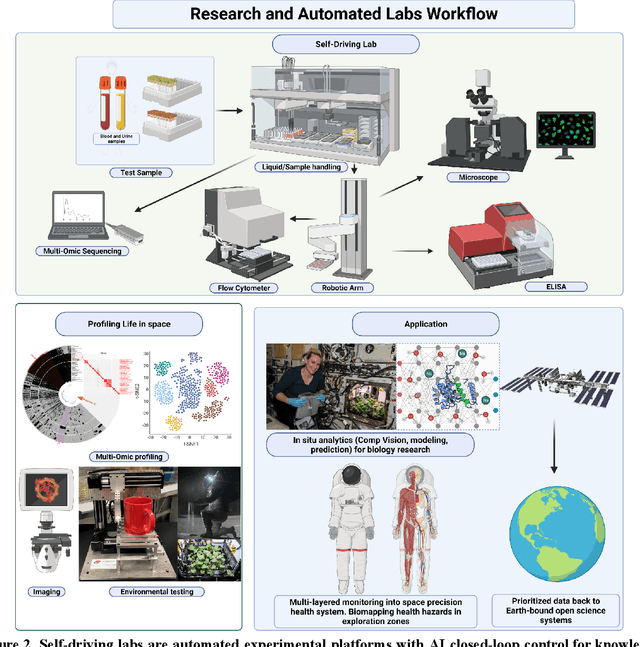
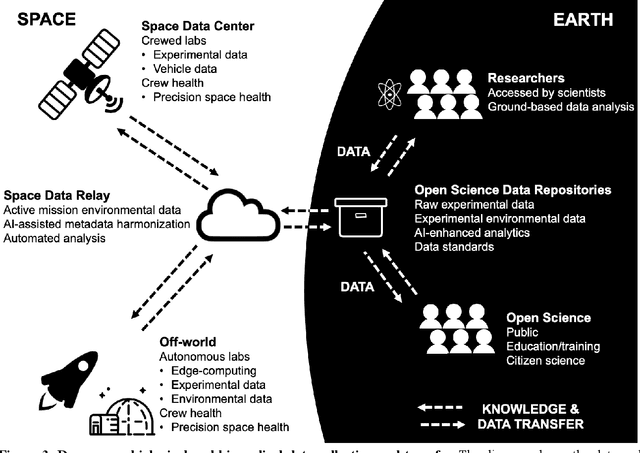
Space biology research aims to understand fundamental effects of spaceflight on organisms, develop foundational knowledge to support deep space exploration, and ultimately bioengineer spacecraft and habitats to stabilize the ecosystem of plants, crops, microbes, animals, and humans for sustained multi-planetary life. To advance these aims, the field leverages experiments, platforms, data, and model organisms from both spaceborne and ground-analog studies. As research is extended beyond low Earth orbit, experiments and platforms must be maximally autonomous, light, agile, and intelligent to expedite knowledge discovery. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration on artificial intelligence, machine learning, and modeling applications which offer key solutions toward these space biology challenges. In the next decade, the synthesis of artificial intelligence into the field of space biology will deepen the biological understanding of spaceflight effects, facilitate predictive modeling and analytics, support maximally autonomous and reproducible experiments, and efficiently manage spaceborne data and metadata, all with the goal to enable life to thrive in deep space.
Invariant Risk Minimisation for Cross-Organism Inference: Substituting Mouse Data for Human Data in Human Risk Factor Discovery
Nov 14, 2021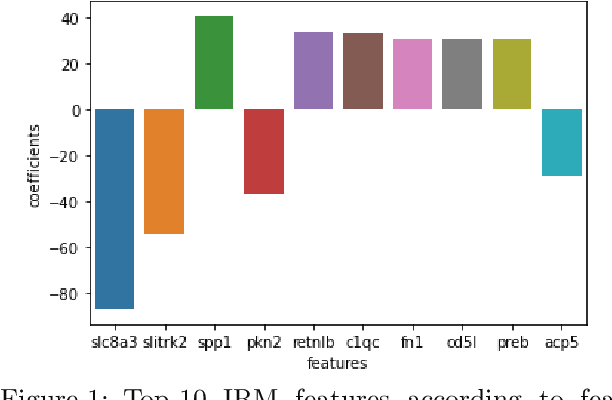
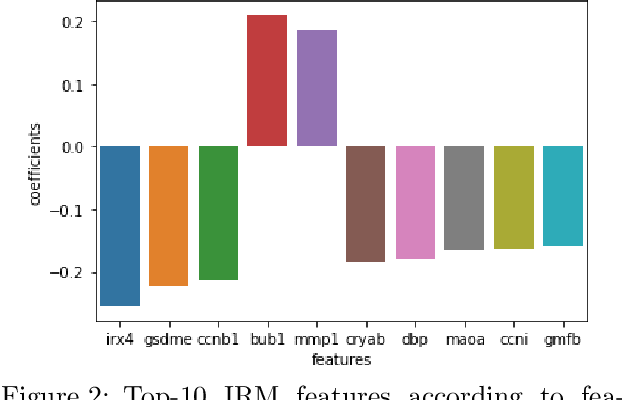
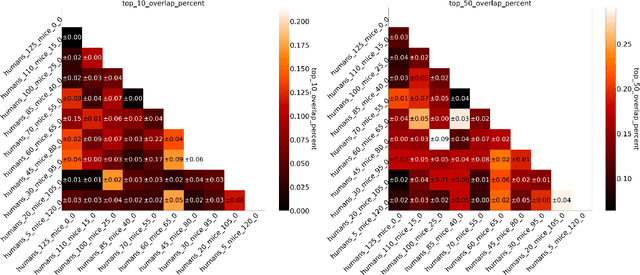
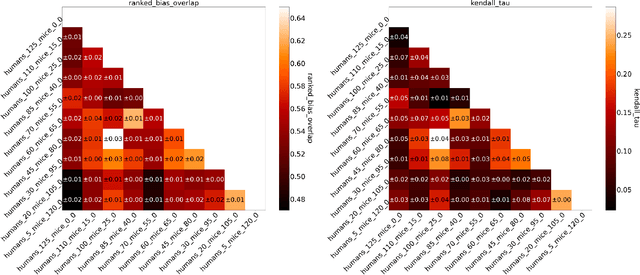
Human medical data can be challenging to obtain due to data privacy concerns, difficulties conducting certain types of experiments, or prohibitive associated costs. In many settings, data from animal models or in-vitro cell lines are available to help augment our understanding of human data. However, this data is known for having low etiological validity in comparison to human data. In this work, we augment small human medical datasets with in-vitro data and animal models. We use Invariant Risk Minimisation (IRM) to elucidate invariant features by considering cross-organism data as belonging to different data-generating environments. Our models identify genes of relevance to human cancer development. We observe a degree of consistency between varying the amounts of human and mouse data used, however, further work is required to obtain conclusive insights. As a secondary contribution, we enhance existing open source datasets and provide two uniformly processed, cross-organism, homologue gene-matched datasets to the community.
Universally Rank Consistent Ordinal Regression in Neural Networks
Oct 14, 2021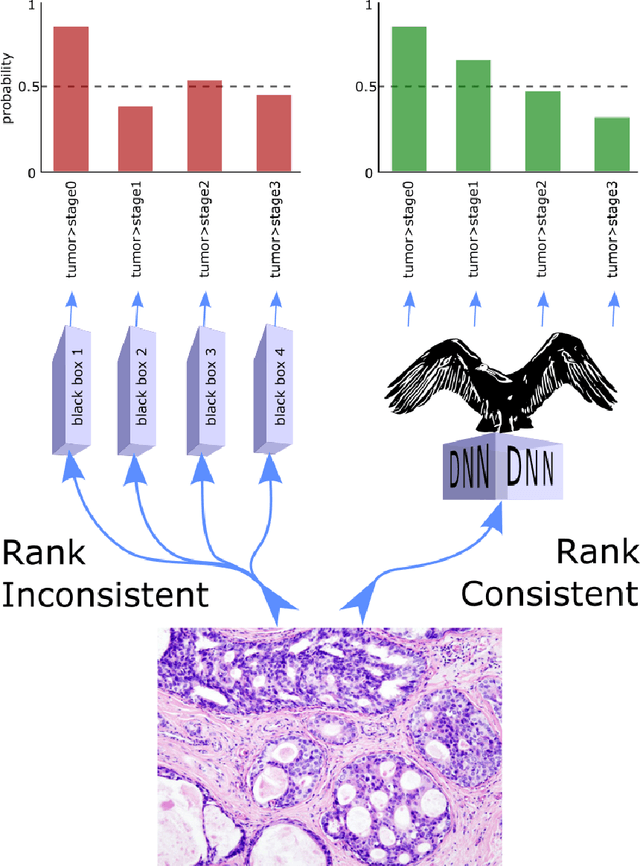


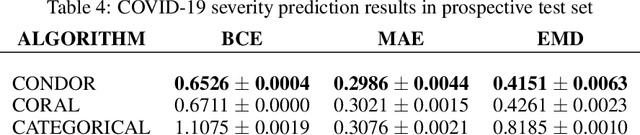
Despite the pervasiveness of ordinal labels in supervised learning, it remains common practice in deep learning to treat such problems as categorical classification using the categorical cross entropy loss. Recent methods attempting to address this issue while respecting the ordinal structure of the labels have resorted to converting ordinal regression into a series of extended binary classification subtasks. However, the adoption of such methods remains inconsistent due to theoretical and practical limitations. Here we address these limitations by demonstrating that the subtask probabilities form a Markov chain. We show how to straightforwardly modify neural network architectures to exploit this fact and thereby constrain predictions to be universally rank consistent. We furthermore prove that all rank consistent solutions can be represented within this formulation. Using diverse benchmarks and the real-world application of a specialized recurrent neural network for COVID-19 prognosis, we demonstrate the practical superiority of this method versus the current state-of-the-art. The method is open sourced as user-friendly PyTorch and TensorFlow packages.
On Invariance Penalties for Risk Minimization
Jun 17, 2021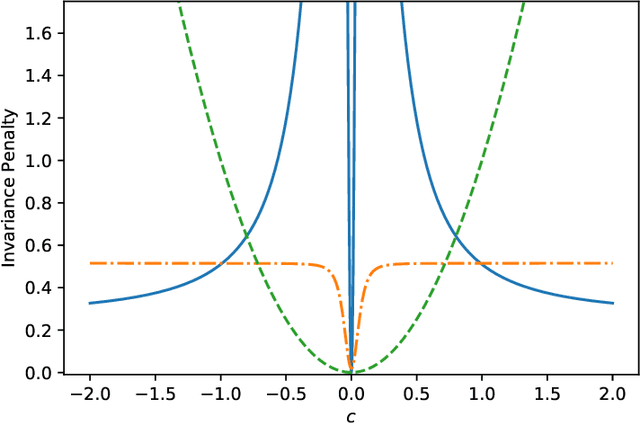

The Invariant Risk Minimization (IRM) principle was first proposed by Arjovsky et al. [2019] to address the domain generalization problem by leveraging data heterogeneity from differing experimental conditions. Specifically, IRM seeks to find a data representation under which an optimal classifier remains invariant across all domains. Despite the conceptual appeal of IRM, the effectiveness of the originally proposed invariance penalty has recently been brought into question. In particular, there exists counterexamples for which that invariance penalty can be arbitrarily small for non-invariant data representations. We propose an alternative invariance penalty by revisiting the Gramian matrix of the data representation. We discuss the role of its eigenvalues in the relationship between the risk and the invariance penalty, and demonstrate that it is ill-conditioned for said counterexamples. The proposed approach is guaranteed to recover an invariant representation for linear settings under mild non-degeneracy conditions. Its effectiveness is substantiated by experiments on DomainBed and InvarianceUnitTest, two extensive test beds for domain generalization.