 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for LLM Function-Calling
Apr 24, 2026Large Language Models (LLMs) are increasingly deployed to autonomously solve real-world tasks. A key ingredient for this is the LLM Function-Calling paradigm, a widely used approach for equipping LLMs with tool-use capabilities. However, an LLM calling functions incorrectly can have severe implications, especially when their effects are irreversible, e.g., transferring money or deleting data. Hence, it is of paramount importance to consider the LLM's confidence that a function call solves the task correctly prior to executing it. Uncertainty Quantification (UQ) methods can be used to quantify this confidence and prevent potentially incorrect function calls. In this work, we present what is, to our knowledge, the first evaluation of UQ methods for LLM Function-Calling (FC). While multi-sample UQ methods, such as Semantic Entropy, show strong performance for natural language Q&A tasks, we find that in the FC setting, it offers no clear advantage over simple single-sample UQ methods. Additionally, we find that the particularities of FC outputs can be leveraged to improve the performance of existing UQ methods in this setting. Specifically, multi-sample UQ methods benefit from clustering FC outputs based on their abstract syntax tree parsing, while single-sample UQ methods can be improved by selecting only semantically meaningful tokens when calculating logit-based uncertainty scores.
The Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
Sparse Autoencoders are Capable LLM Jailbreak Mitigators
Feb 12, 2026Jailbreak attacks remain a persistent threat to large language model safety. We propose Context-Conditioned Delta Steering (CC-Delta), an SAE-based defense that identifies jailbreak-relevant sparse features by comparing token-level representations of the same harmful request with and without jailbreak context. Using paired harmful/jailbreak prompts, CC-Delta selects features via statistical testing and applies inference-time mean-shift steering in SAE latent space. Across four aligned instruction-tuned models and twelve jailbreak attacks, CC-Delta achieves comparable or better safety-utility tradeoffs than baseline defenses operating in dense latent space. In particular, our method clearly outperforms dense mean-shift steering on all four models, and particularly against out-of-distribution attacks, showing that steering in sparse SAE feature space offers advantages over steering in dense activation space for jailbreak mitigation. Our results suggest off-the-shelf SAEs trained for interpretability can be repurposed as practical jailbreak defenses without task-specific training.
GenCtrl -- A Formal Controllability Toolkit for Generative Models
Jan 09, 2026As generative models become ubiquitous, there is a critical need for fine-grained control over the generation process. Yet, while controlled generation methods from prompting to fine-tuning proliferate, a fundamental question remains unanswered: are these models truly controllable in the first place? In this work, we provide a theoretical framework to formally answer this question. Framing human-model interaction as a control process, we propose a novel algorithm to estimate the controllable sets of models in a dialogue setting. Notably, we provide formal guarantees on the estimation error as a function of sample complexity: we derive probably-approximately correct bounds for controllable set estimates that are distribution-free, employ no assumptions except for output boundedness, and work for any black-box nonlinear control system (i.e., any generative model). We empirically demonstrate the theoretical framework on different tasks in controlling dialogue processes, for both language models and text-to-image generation. Our results show that model controllability is surprisingly fragile and highly dependent on the experimental setting. This highlights the need for rigorous controllability analysis, shifting the focus from simply attempting control to first understanding its fundamental limits.
Self-reflective Uncertainties: Do LLMs Know Their Internal Answer Distribution?
May 26, 2025To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue that in the output space of LLMs, the space of strings, exist strings expressive enough to summarize the distribution over output strings the LLM deems possible. We lay a foundation for this new avenue of uncertainty explication and present SelfReflect, a theoretically-motivated metric to assess how faithfully a string summarizes an LLM's internal answer distribution. We show that SelfReflect is able to discriminate even subtle differences of candidate summary strings and that it aligns with human judgement, outperforming alternative metrics such as LLM judges and embedding comparisons. With SelfReflect, we investigate a number of self-summarization methods and find that even state-of-the-art reasoning models struggle to explicate their internal uncertainty. But we find that faithful summarizations can be generated by sampling and summarizing. Our metric enables future works towards this universal form of LLM uncertainties.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025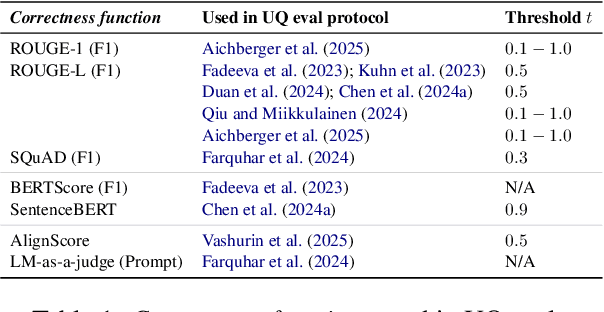
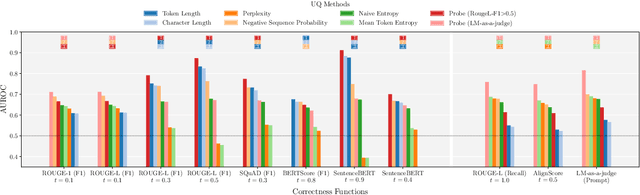
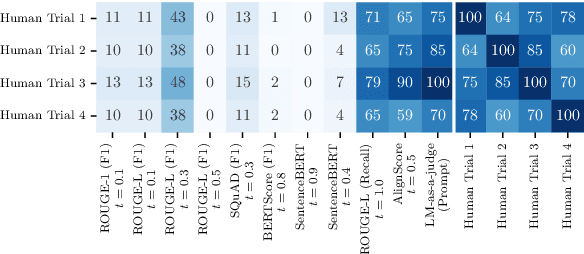
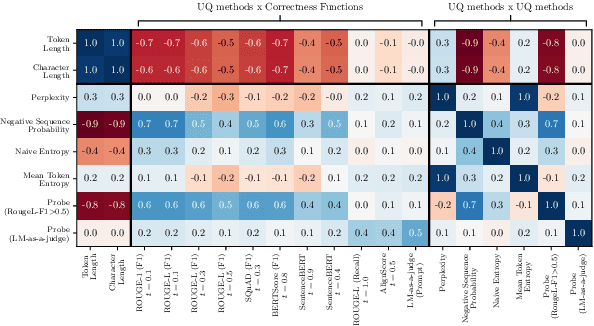
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.
Controlling Language and Diffusion Models by Transporting Activations
Oct 30, 2024



The increasing capabilities of large generative models and their ever more widespread deployment have raised concerns about their reliability, safety, and potential misuse. To address these issues, recent works have proposed to control model generation by steering model activations in order to effectively induce or prevent the emergence of concepts or behaviors in the generated output. In this paper we introduce Activation Transport (AcT), a general framework to steer activations guided by optimal transport theory that generalizes many previous activation-steering works. AcT is modality-agnostic and provides fine-grained control over the model behavior with negligible computational overhead, while minimally impacting model abilities. We experimentally show the effectiveness and versatility of our approach by addressing key challenges in large language models (LLMs) and text-to-image diffusion models (T2Is). For LLMs, we show that AcT can effectively mitigate toxicity, induce arbitrary concepts, and increase their truthfulness. In T2Is, we show how AcT enables fine-grained style control and concept negation.
Considerations for Distribution Shift Robustness of Diagnostic Models in Healthcare
Oct 25, 2024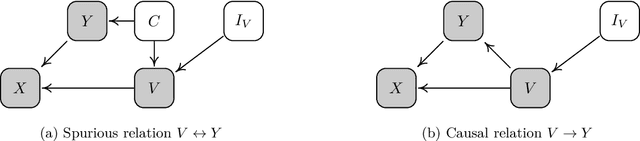
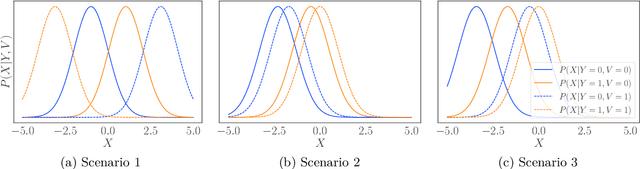
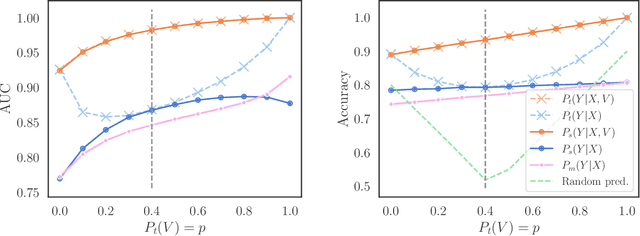
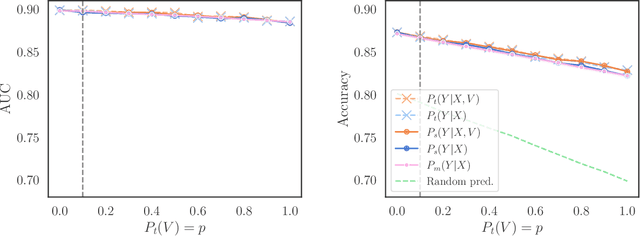
We consider robustness to distribution shifts in the context of diagnostic models in healthcare, where the prediction target $Y$, e.g., the presence of a disease, is causally upstream of the observations $X$, e.g., a biomarker. Distribution shifts may occur, for instance, when the training data is collected in a domain with patients having particular demographic characteristics while the model is deployed on patients from a different demographic group. In the domain of applied ML for health, it is common to predict $Y$ from $X$ without considering further information about the patient. However, beyond the direct influence of the disease $Y$ on biomarker $X$, a predictive model may learn to exploit confounding dependencies (or shortcuts) between $X$ and $Y$ that are unstable under certain distribution shifts. In this work, we highlight a data generating mechanism common to healthcare settings and discuss how recent theoretical results from the causality literature can be applied to build robust predictive models. We theoretically show why ignoring covariates as well as common invariant learning approaches will in general not yield robust predictors in the studied setting, while including certain covariates into the prediction model will. In an extensive simulation study, we showcase the robustness (or lack thereof) of different predictors under various data generating processes. Lastly, we analyze the performance of the different approaches using the PTB-XL dataset, a public dataset of annotated ECG recordings.
Robust multimodal models have outlier features and encode more concepts
Oct 19, 2023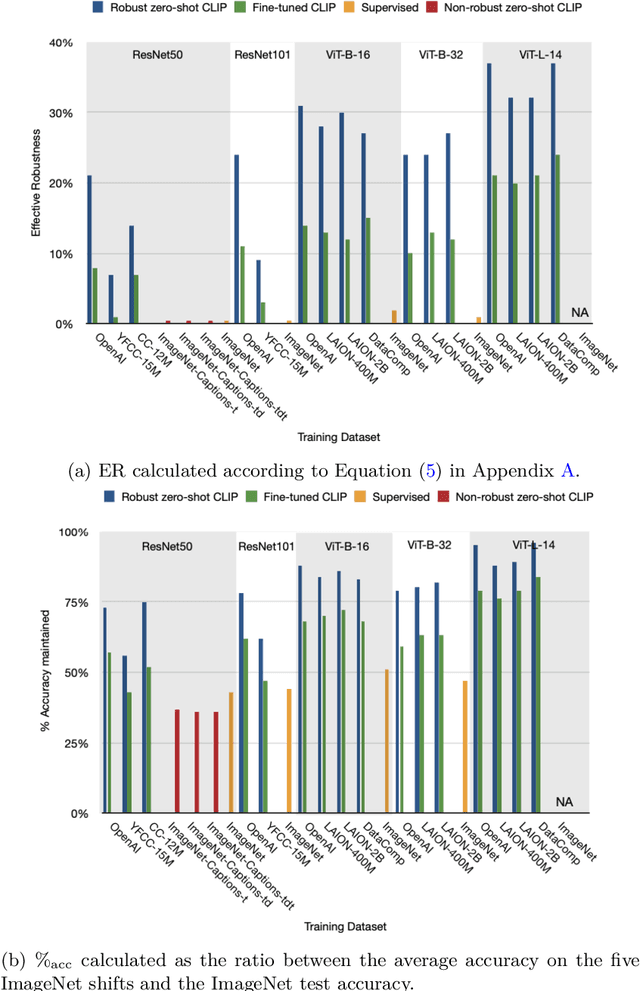
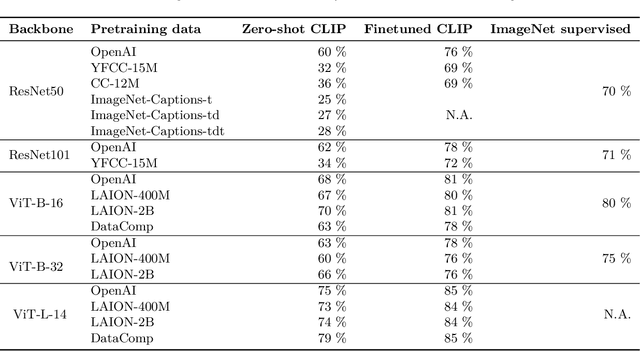
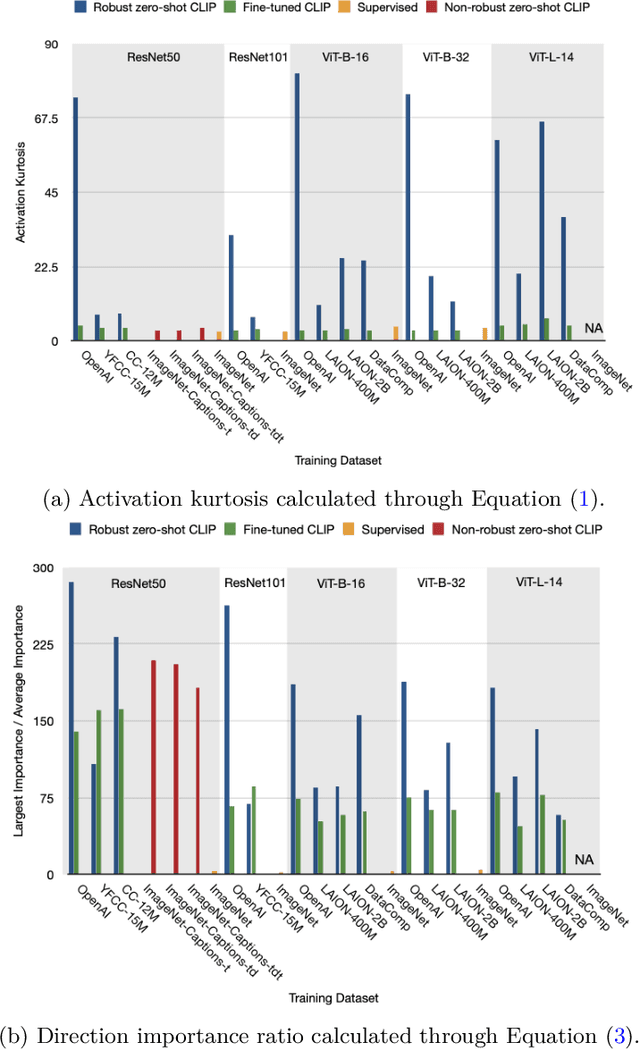
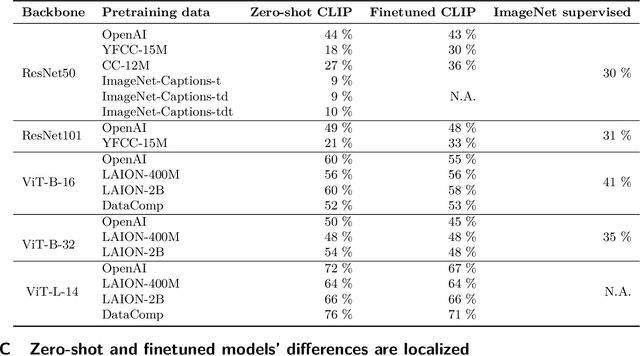
What distinguishes robust models from non-robust ones? This question has gained traction with the appearance of large-scale multimodal models, such as CLIP. These models have demonstrated unprecedented robustness with respect to natural distribution shifts. While it has been shown that such differences in robustness can be traced back to differences in training data, so far it is not known what that translates to in terms of what the model has learned. In this work, we bridge this gap by probing the representation spaces of 12 robust multimodal models with various backbones (ResNets and ViTs) and pretraining sets (OpenAI, LAION-400M, LAION-2B, YFCC15M, CC12M and DataComp). We find two signatures of robustness in the representation spaces of these models: (1) Robust models exhibit outlier features characterized by their activations, with some being several orders of magnitude above average. These outlier features induce privileged directions in the model's representation space. We demonstrate that these privileged directions explain most of the predictive power of the model by pruning up to $80 \%$ of the least important representation space directions without negative impacts on model accuracy and robustness; (2) Robust models encode substantially more concepts in their representation space. While this superposition of concepts allows robust models to store much information, it also results in highly polysemantic features, which makes their interpretation challenging. We discuss how these insights pave the way for future research in various fields, such as model pruning and mechanistic interpretability.
The Role of Entropy and Reconstruction in Multi-View Self-Supervised Learning
Jul 20, 2023



The mechanisms behind the success of multi-view self-supervised learning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied through the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We consider a different lower bound on the MI consisting of an entropy and a reconstruction term (ER), and analyze the main MVSSL families through its lens. Through this ER bound, we show that clustering-based methods such as DeepCluster and SwAV maximize the MI. We also re-interpret the mechanisms of distillation-based approaches such as BYOL and DINO, showing that they explicitly maximize the reconstruction term and implicitly encourage a stable entropy, and we confirm this empirically. We show that replacing the objectives of common MVSSL methods with this ER bound achieves competitive performance, while making them stable when training with smaller batch sizes or smaller exponential moving average (EMA) coefficients. Github repo: https://github.com/apple/ml-entropy-reconstruction.