 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileCLIP2: Improving Multi-Modal Reinforced Training
Aug 28, 2025Foundation image-text models such as CLIP with zero-shot capabilities enable a wide array of applications. MobileCLIP is a recent family of image-text models at 3-15ms latency and 50-150M parameters with state-of-the-art zero-shot accuracy. The main ingredients in MobileCLIP were its low-latency and light architectures and a novel multi-modal reinforced training that made knowledge distillation from multiple caption-generators and CLIP teachers efficient, scalable, and reproducible. In this paper, we improve the multi-modal reinforced training of MobileCLIP through: 1) better CLIP teacher ensembles trained on the DFN dataset, 2) improved captioner teachers trained on the DFN dataset and fine-tuned on a diverse selection of high-quality image-caption datasets. We discover new insights through ablations such as the importance of temperature tuning in contrastive knowledge distillation, the effectiveness of caption-generator fine-tuning for caption diversity, and the additive improvement from combining synthetic captions generated by multiple models. We train a new family of models called MobileCLIP2 and achieve state-of-the-art ImageNet-1k zero-shot accuracies at low latencies. In particular, we observe 2.2% improvement in ImageNet-1k accuracy for MobileCLIP2-B compared with MobileCLIP-B architecture. Notably, MobileCLIP2-S4 matches the zero-shot accuracy of SigLIP-SO400M/14 on ImageNet-1k while being 2$\times$ smaller and improves on DFN ViT-L/14 at 2.5$\times$ lower latency. We release our pretrained models (https://github.com/apple/ml-mobileclip) and the data generation code (https://github.com/apple/ml-mobileclip-dr). The data generation code makes it easy to create new reinforced datasets with arbitrary teachers using distributed scalable processing.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
Datasets, Documents, and Repetitions: The Practicalities of Unequal Data Quality
Mar 10, 2025Data filtering has become a powerful tool for improving model performance while reducing computational cost. However, as large language model compute budgets continue to grow, the limited data volume provided by heavily filtered and deduplicated datasets will become a practical constraint. In efforts to better understand how to proceed, we study model performance at various compute budgets and across multiple pre-training datasets created through data filtering and deduplication. We find that, given appropriate modifications to the training recipe, repeating existing aggressively filtered datasets for up to ten epochs can outperform training on the ten times larger superset for a single epoch across multiple compute budget orders of magnitude. While this finding relies on repeating the dataset for many epochs, we also investigate repeats within these datasets at the document level. We find that not all documents within a dataset are equal, and we can create better datasets relative to a token budget by explicitly manipulating the counts of individual documents. We conclude by arguing that even as large language models scale, data filtering remains an important direction of research.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum
May 21, 2024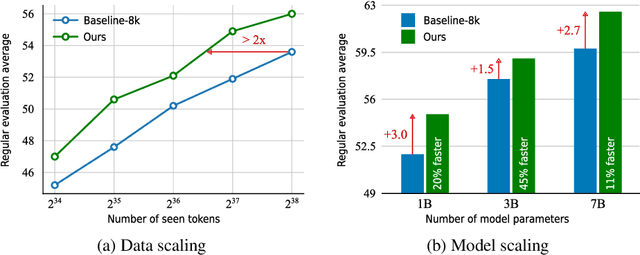
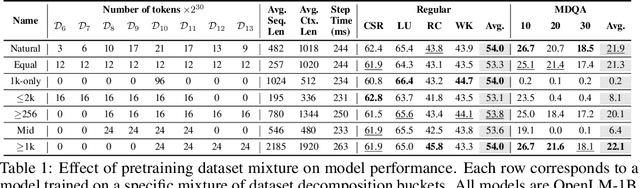
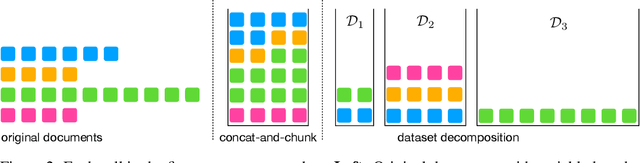
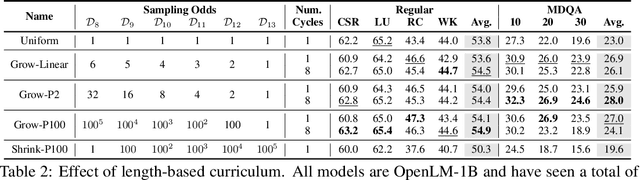
Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length. However, this method of concatenation can lead to cross-document attention within a sequence, which is neither a desirable learning signal nor computationally efficient. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a penalty proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy 3x faster compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Scalable Pre-training of Large Autoregressive Image Models
Jan 16, 2024



This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
Pre-trained Language Models Do Not Help Auto-regressive Text-to-Image Generation
Nov 27, 2023



Recent advances in image tokenizers, such as VQ-VAE, have enabled text-to-image generation using auto-regressive methods, similar to language modeling. However, these methods have yet to leverage pre-trained language models, despite their adaptability to various downstream tasks. In this work, we explore this gap by adapting a pre-trained language model for auto-regressive text-to-image generation, and find that pre-trained language models offer limited help. We provide a two-fold explanation by analyzing tokens from each modality. First, we demonstrate that image tokens possess significantly different semantics compared to text tokens, rendering pre-trained language models no more effective in modeling them than randomly initialized ones. Second, the text tokens in the image-text datasets are too simple compared to normal language model pre-training data, which causes the catastrophic degradation of language models' capability.