 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Pre-training of Large Autoregressive Image Models
Jan 16, 2024



This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
On the generalization of learning-based 3D reconstruction
Jun 27, 2020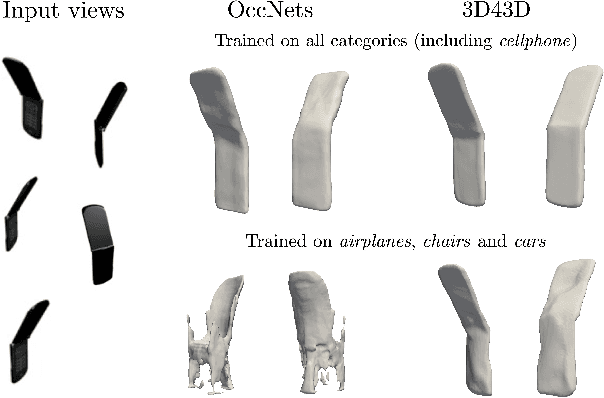


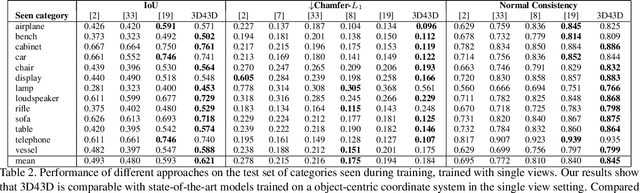
State-of-the-art learning-based monocular 3D reconstruction methods learn priors over object categories on the training set, and as a result struggle to achieve reasonable generalization to object categories unseen during training. In this paper we study the inductive biases encoded in the model architecture that impact the generalization of learning-based 3D reconstruction methods. We find that 3 inductive biases impact performance: the spatial extent of the encoder, the use of the underlying geometry of the scene to describe point features, and the mechanism to aggregate information from multiple views. Additionally, we propose mechanisms to enforce those inductive biases: a point representation that is aware of camera position, and a variance cost to aggregate information across views. Our model achieves state-of-the-art results on the standard ShapeNet 3D reconstruction benchmark in various settings.