 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Embedding of Semantic Similarity in Control Policies via Entangled Bisimulation
Jan 28, 2022



Learning generalizeable policies from visual input in the presence of visual distractions is a challenging problem in reinforcement learning. Recently, there has been renewed interest in bisimulation metrics as a tool to address this issue; these metrics can be used to learn representations that are, in principle, invariant to irrelevant distractions by measuring behavioural similarity between states. An accurate, unbiased, and scalable estimation of these metrics has proved elusive in continuous state and action scenarios. We propose entangled bisimulation, a bisimulation metric that allows the specification of the distance function between states, and can be estimated without bias in continuous state and action spaces. We show how entangled bisimulation can meaningfully improve over previous methods on the Distracting Control Suite (DCS), even when added on top of data augmentation techniques.
Robust Robotic Control from Pixels using Contrastive Recurrent State-Space Models
Dec 02, 2021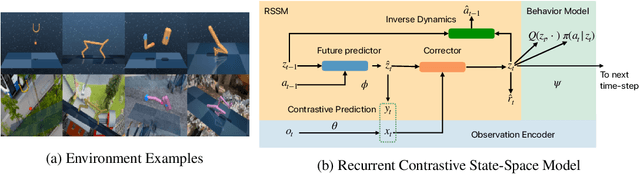
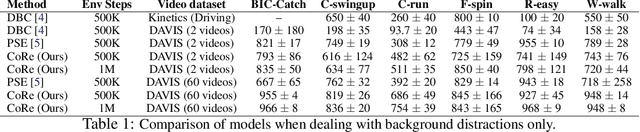


Modeling the world can benefit robot learning by providing a rich training signal for shaping an agent's latent state space. However, learning world models in unconstrained environments over high-dimensional observation spaces such as images is challenging. One source of difficulty is the presence of irrelevant but hard-to-model background distractions, and unimportant visual details of task-relevant entities. We address this issue by learning a recurrent latent dynamics model which contrastively predicts the next observation. This simple model leads to surprisingly robust robotic control even with simultaneous camera, background, and color distractions. We outperform alternatives such as bisimulation methods which impose state-similarity measures derived from divergence in future reward or future optimal actions. We obtain state-of-the-art results on the Distracting Control Suite, a challenging benchmark for pixel-based robotic control.
An Attention Free Transformer
May 28, 2021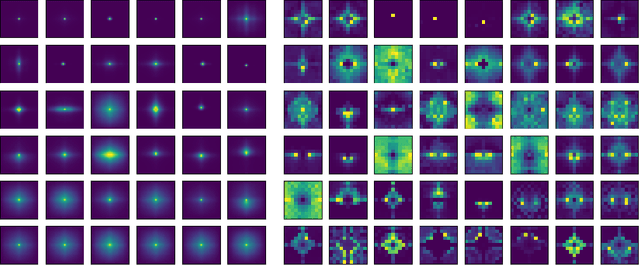

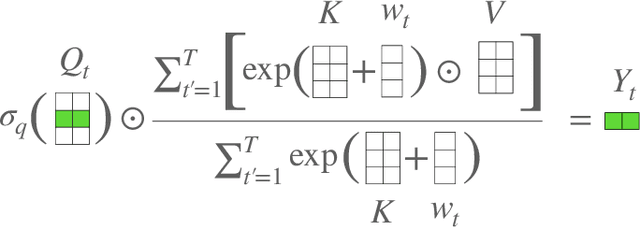
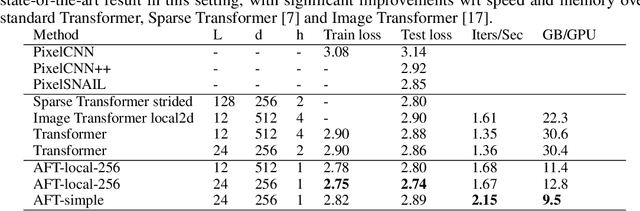
We introduce Attention Free Transformer (AFT), an efficient variant of Transformers that eliminates the need for dot product self attention. In an AFT layer, the key and value are first combined with a set of learned position biases, the result of which is multiplied with the query in an element-wise fashion. This new operation has a memory complexity linear w.r.t. both the context size and the dimension of features, making it compatible to both large input and model sizes. We also introduce AFT-local and AFT-conv, two model variants that take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity. We conduct extensive experiments on two autoregressive modeling tasks (CIFAR10 and Enwik8) as well as an image recognition task (ImageNet-1K classification). We show that AFT demonstrates competitive performance on all the benchmarks, while providing excellent efficiency at the same time.
Uncertainty Weighted Actor-Critic for Offline Reinforcement Learning
May 17, 2021
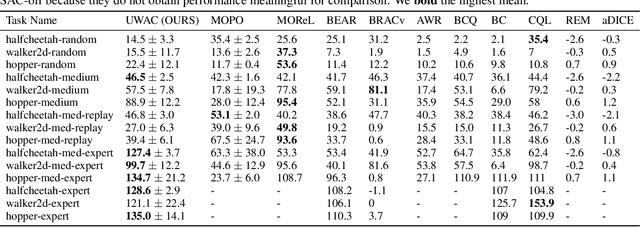
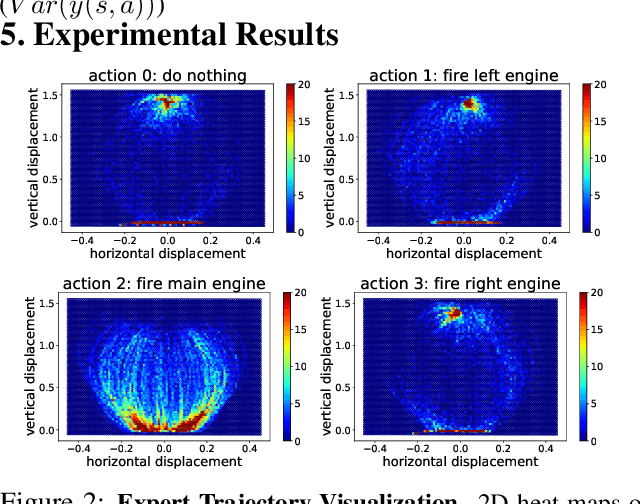

Offline Reinforcement Learning promises to learn effective policies from previously-collected, static datasets without the need for exploration. However, existing Q-learning and actor-critic based off-policy RL algorithms fail when bootstrapping from out-of-distribution (OOD) actions or states. We hypothesize that a key missing ingredient from the existing methods is a proper treatment of uncertainty in the offline setting. We propose Uncertainty Weighted Actor-Critic (UWAC), an algorithm that detects OOD state-action pairs and down-weights their contribution in the training objectives accordingly. Implementation-wise, we adopt a practical and effective dropout-based uncertainty estimation method that introduces very little overhead over existing RL algorithms. Empirically, we observe that UWAC substantially improves model stability during training. In addition, UWAC out-performs existing offline RL methods on a variety of competitive tasks, and achieves significant performance gains over the state-of-the-art baseline on datasets with sparse demonstrations collected from human experts.
Unconstrained Scene Generation with Locally Conditioned Radiance Fields
Apr 01, 2021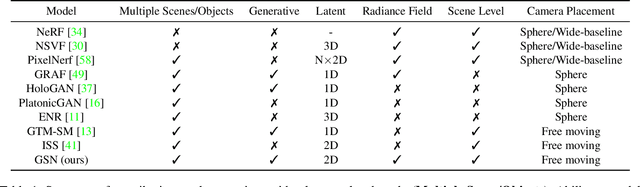
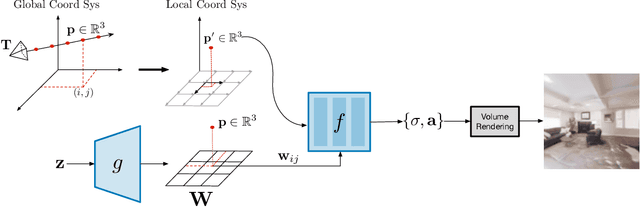

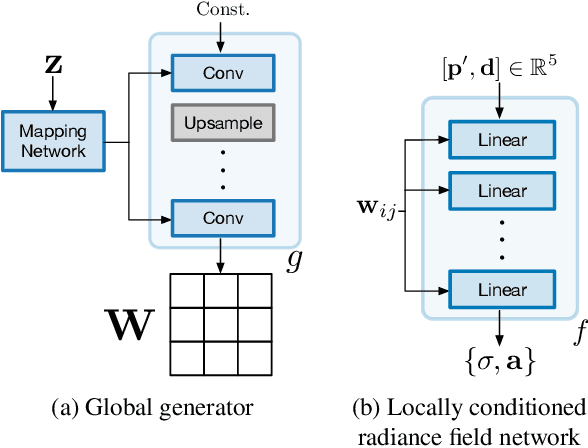
We tackle the challenge of learning a distribution over complex, realistic, indoor scenes. In this paper, we introduce Generative Scene Networks (GSN), which learns to decompose scenes into a collection of many local radiance fields that can be rendered from a free moving camera. Our model can be used as a prior to generate new scenes, or to complete a scene given only sparse 2D observations. Recent work has shown that generative models of radiance fields can capture properties such as multi-view consistency and view-dependent lighting. However, these models are specialized for constrained viewing of single objects, such as cars or faces. Due to the size and complexity of realistic indoor environments, existing models lack the representational capacity to adequately capture them. Our decomposition scheme scales to larger and more complex scenes while preserving details and diversity, and the learned prior enables high-quality rendering from viewpoints that are significantly different from observed viewpoints. When compared to existing models, GSN produces quantitatively higher-quality scene renderings across several different scene datasets.
On the generalization of learning-based 3D reconstruction
Jun 27, 2020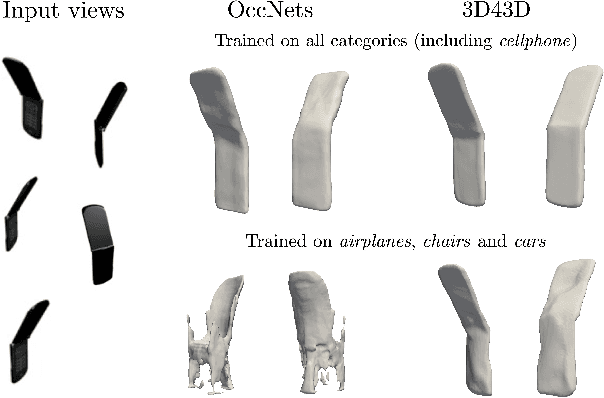


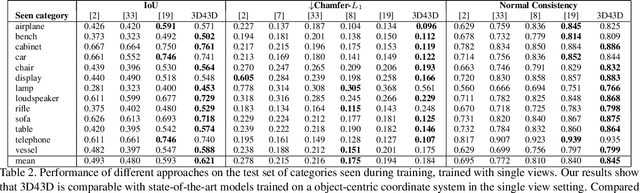
State-of-the-art learning-based monocular 3D reconstruction methods learn priors over object categories on the training set, and as a result struggle to achieve reasonable generalization to object categories unseen during training. In this paper we study the inductive biases encoded in the model architecture that impact the generalization of learning-based 3D reconstruction methods. We find that 3 inductive biases impact performance: the spatial extent of the encoder, the use of the underlying geometry of the scene to describe point features, and the mechanism to aggregate information from multiple views. Additionally, we propose mechanisms to enforce those inductive biases: a point representation that is aware of camera position, and a variance cost to aggregate information across views. Our model achieves state-of-the-art results on the standard ShapeNet 3D reconstruction benchmark in various settings.
Capsules with Inverted Dot-Product Attention Routing
Feb 26, 2020



We introduce a new routing algorithm for capsule networks, in which a child capsule is routed to a parent based only on agreement between the parent's state and the child's vote. The new mechanism 1) designs routing via inverted dot-product attention; 2) imposes Layer Normalization as normalization; and 3) replaces sequential iterative routing with concurrent iterative routing. When compared to previously proposed routing algorithms, our method improves performance on benchmark datasets such as CIFAR-10 and CIFAR-100, and it performs at-par with a powerful CNN (ResNet-18) with 4x fewer parameters. On a different task of recognizing digits from overlayed digit images, the proposed capsule model performs favorably against CNNs given the same number of layers and neurons per layer. We believe that our work raises the possibility of applying capsule networks to complex real-world tasks. Our code is publicly available at: https://github.com/apple/ml-capsules-inverted-attention-routing An alternative implementation is available at: https://github.com/yaohungt/Capsules-Inverted-Attention-Routing/blob/master/README.md
Geometric Capsule Autoencoders for 3D Point Clouds
Dec 06, 2019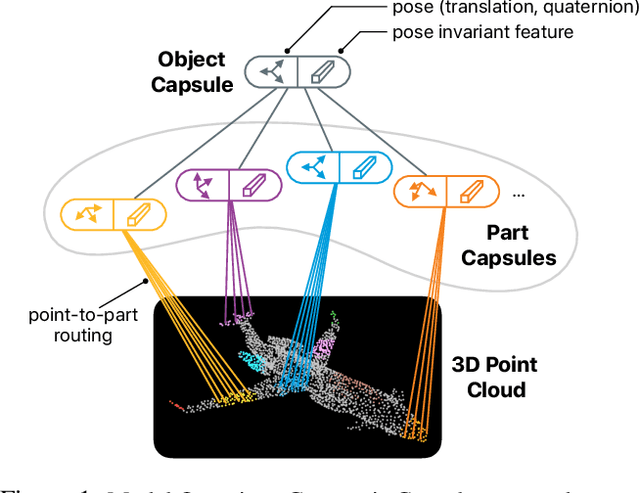


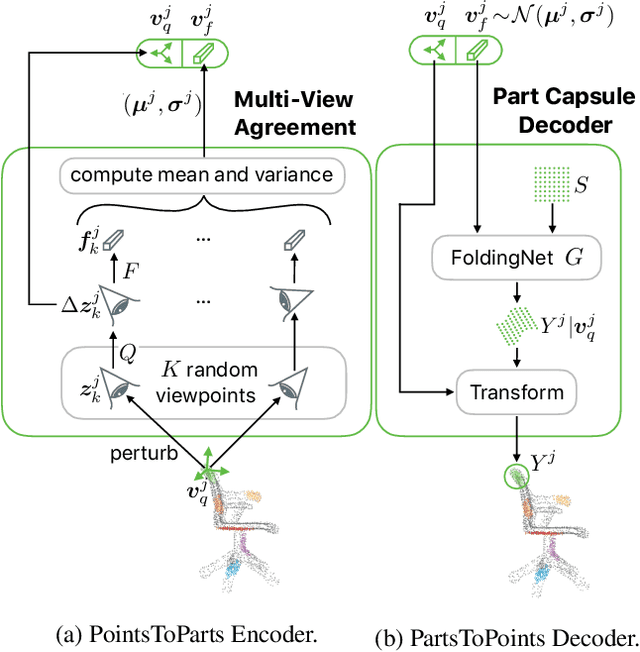
We propose a method to learn object representations from 3D point clouds using bundles of geometrically interpretable hidden units, which we call geometric capsules. Each geometric capsule represents a visual entity, such as an object or a part, and consists of two components: a pose and a feature. The pose encodes where the entity is, while the feature encodes what it is. We use these capsules to construct a Geometric Capsule Autoencoder that learns to group 3D points into parts (small local surfaces), and these parts into the whole object, in an unsupervised manner. Our novel Multi-View Agreement voting mechanism is used to discover an object's canonical pose and its pose-invariant feature vector. Using the ShapeNet and ModelNet40 datasets, we analyze the properties of the learned representations and show the benefits of having multiple votes agree. We perform alignment and retrieval of arbitrarily rotated objects -- tasks that evaluate our model's object identification and canonical pose recovery capabilities -- and obtained insightful results.
Unsupervised Learning of Video Representations using LSTMs
Jan 04, 2016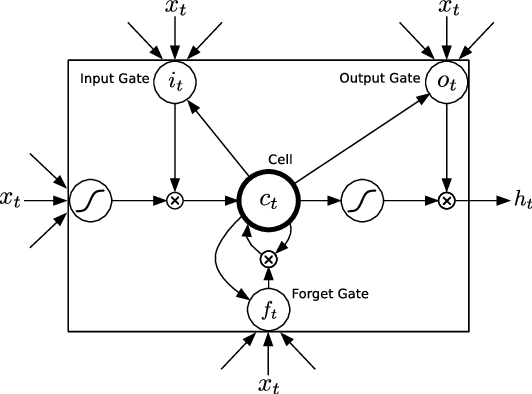

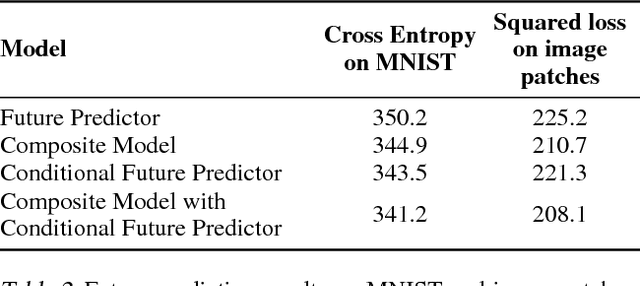
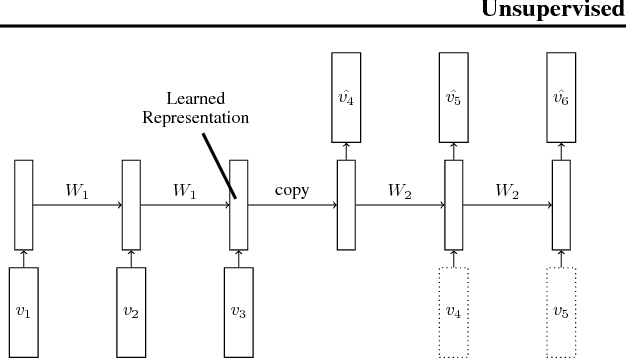
We use multilayer Long Short Term Memory (LSTM) networks to learn representations of video sequences. Our model uses an encoder LSTM to map an input sequence into a fixed length representation. This representation is decoded using single or multiple decoder LSTMs to perform different tasks, such as reconstructing the input sequence, or predicting the future sequence. We experiment with two kinds of input sequences - patches of image pixels and high-level representations ("percepts") of video frames extracted using a pretrained convolutional net. We explore different design choices such as whether the decoder LSTMs should condition on the generated output. We analyze the outputs of the model qualitatively to see how well the model can extrapolate the learned video representation into the future and into the past. We try to visualize and interpret the learned features. We stress test the model by running it on longer time scales and on out-of-domain data. We further evaluate the representations by finetuning them for a supervised learning problem - human action recognition on the UCF-101 and HMDB-51 datasets. We show that the representations help improve classification accuracy, especially when there are only a few training examples. Even models pretrained on unrelated datasets (300 hours of YouTube videos) can help action recognition performance.
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification
May 08, 2015
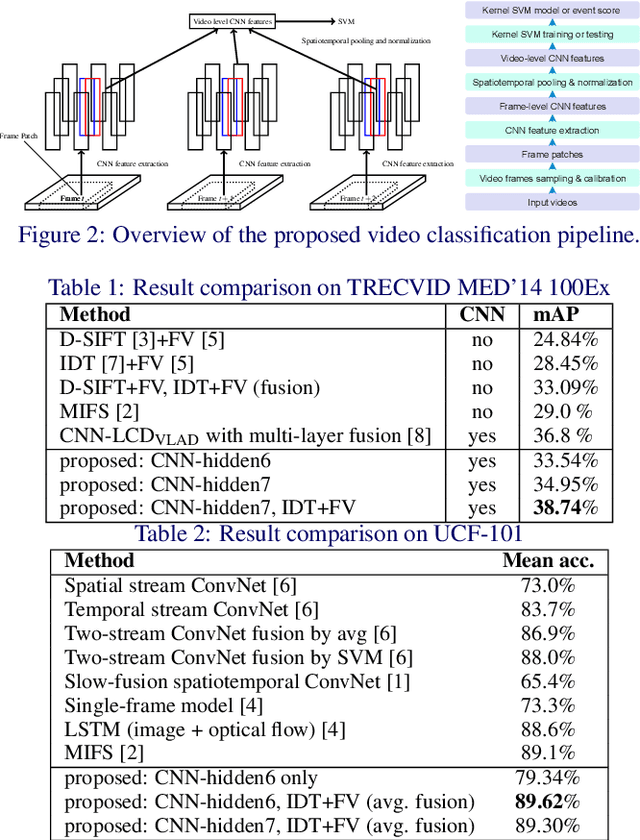
We conduct an in-depth exploration of different strategies for doing event detection in videos using convolutional neural networks (CNNs) trained for image classification. We study different ways of performing spatial and temporal pooling, feature normalization, choice of CNN layers as well as choice of classifiers. Making judicious choices along these dimensions led to a very significant increase in performance over more naive approaches that have been used till now. We evaluate our approach on the challenging TRECVID MED'14 dataset with two popular CNN architectures pretrained on ImageNet. On this MED'14 dataset, our methods, based entirely on image-trained CNN features, can outperform several state-of-the-art non-CNN models. Our proposed late fusion of CNN- and motion-based features can further increase the mean average precision (mAP) on MED'14 from 34.95% to 38.74%. The fusion approach achieves the state-of-the-art classification performance on the challenging UCF-101 dataset.