 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the relative composition of EEG signals using pairwise relative shift pretraining
Nov 14, 2025Self-supervised learning (SSL) offers a promising approach for learning electroencephalography (EEG) representations from unlabeled data, reducing the need for expensive annotations for clinical applications like sleep staging and seizure detection. While current EEG SSL methods predominantly use masked reconstruction strategies like masked autoencoders (MAE) that capture local temporal patterns, position prediction pretraining remains underexplored despite its potential to learn long-range dependencies in neural signals. We introduce PAirwise Relative Shift or PARS pretraining, a novel pretext task that predicts relative temporal shifts between randomly sampled EEG window pairs. Unlike reconstruction-based methods that focus on local pattern recovery, PARS encourages encoders to capture relative temporal composition and long-range dependencies inherent in neural signals. Through comprehensive evaluation on various EEG decoding tasks, we demonstrate that PARS-pretrained transformers consistently outperform existing pretraining strategies in label-efficient and transfer learning settings, establishing a new paradigm for self-supervised EEG representation learning.
Overcoming the Pitfalls of Vision-Language Model Finetuning for OOD Generalization
Jan 29, 2024
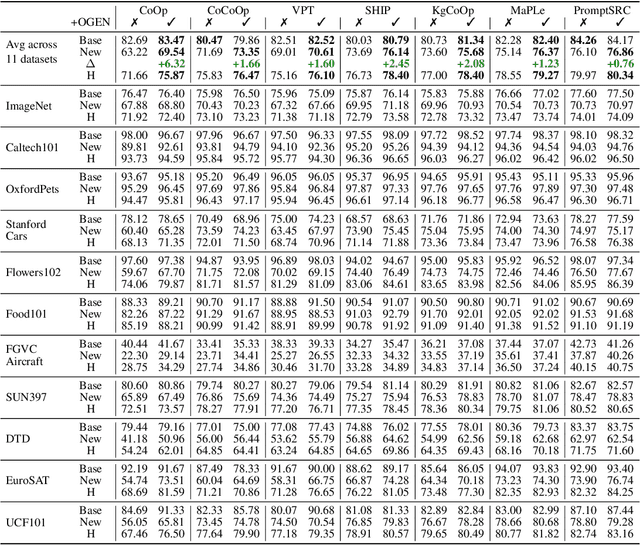

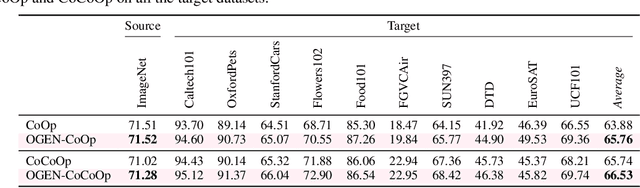
Existing vision-language models exhibit strong generalization on a variety of visual domains and tasks. However, such models mainly perform zero-shot recognition in a closed-set manner, and thus struggle to handle open-domain visual concepts by design. There are recent finetuning methods, such as prompt learning, that not only study the discrimination between in-distribution (ID) and out-of-distribution (OOD) samples, but also show some improvements in both ID and OOD accuracies. In this paper, we first demonstrate that vision-language models, after long enough finetuning but without proper regularization, tend to overfit the known classes in the given dataset, with degraded performance on unknown classes. Then we propose a novel approach OGEN to address this pitfall, with the main focus on improving the OOD GENeralization of finetuned models. Specifically, a class-conditional feature generator is introduced to synthesize OOD features using just the class name of any unknown class. Such synthesized features will provide useful knowledge about unknowns and help regularize the decision boundary between ID and OOD data when optimized jointly. Equally important is our adaptive self-distillation mechanism to regularize our feature generation model during joint optimization, i.e., adaptively transferring knowledge between model states to further prevent overfitting. Experiments validate that our method yields convincing gains in OOD generalization performance in different settings.
LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023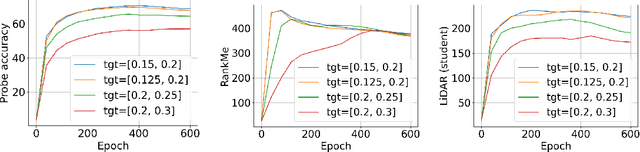
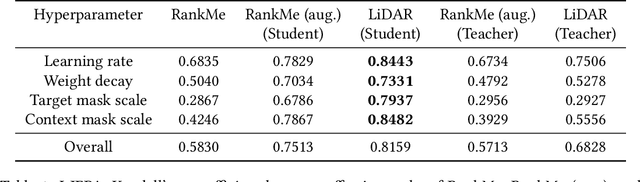

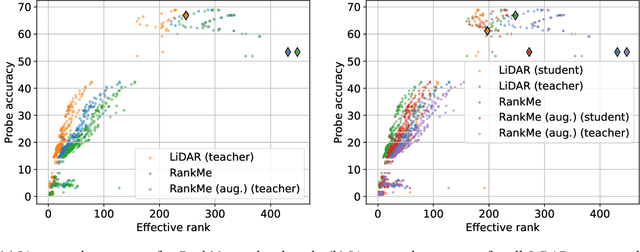
Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Frequency-Aware Masked Autoencoders for Multimodal Pretraining on Biosignals
Sep 12, 2023
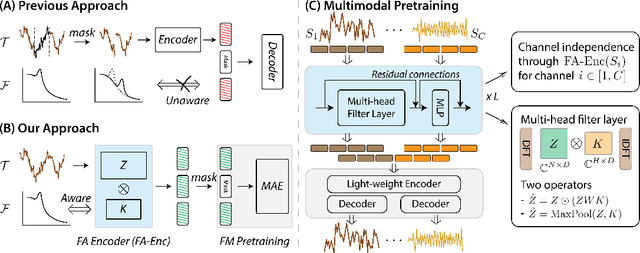
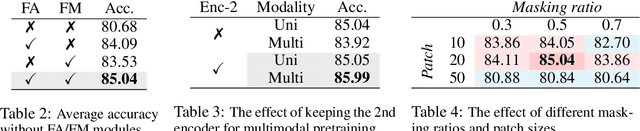
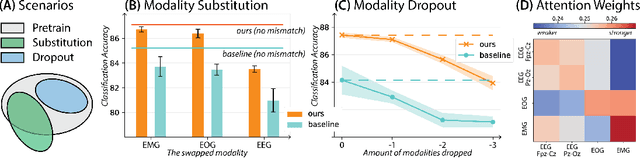
Leveraging multimodal information from biosignals is vital for building a comprehensive representation of people's physical and mental states. However, multimodal biosignals often exhibit substantial distributional shifts between pretraining and inference datasets, stemming from changes in task specification or variations in modality compositions. To achieve effective pretraining in the presence of potential distributional shifts, we propose a frequency-aware masked autoencoder ($\texttt{bio}$FAME) that learns to parameterize the representation of biosignals in the frequency space. $\texttt{bio}$FAME incorporates a frequency-aware transformer, which leverages a fixed-size Fourier-based operator for global token mixing, independent of the length and sampling rate of inputs. To maintain the frequency components within each input channel, we further employ a frequency-maintain pretraining strategy that performs masked autoencoding in the latent space. The resulting architecture effectively utilizes multimodal information during pretraining, and can be seamlessly adapted to diverse tasks and modalities at test time, regardless of input size and order. We evaluated our approach on a diverse set of transfer experiments on unimodal time series, achieving an average of $\uparrow$5.5% improvement in classification accuracy over the previous state-of-the-art. Furthermore, we demonstrated that our architecture is robust in modality mismatch scenarios, including unpredicted modality dropout or substitution, proving its practical utility in real-world applications. Code will be available soon.
MAST: Masked Augmentation Subspace Training for Generalizable Self-Supervised Priors
Mar 07, 2023Recent Self-Supervised Learning (SSL) methods are able to learn feature representations that are invariant to different data augmentations, which can then be transferred to downstream tasks of interest. However, different downstream tasks require different invariances for their best performance, so the optimal choice of augmentations for SSL depends on the target task. In this paper, we aim to learn self-supervised features that generalize well across a variety of downstream tasks (e.g., object classification, detection and instance segmentation) without knowing any task information beforehand. We do so by Masked Augmentation Subspace Training (or MAST) to encode in the single feature space the priors from different data augmentations in a factorized way. Specifically, we disentangle the feature space into separate subspaces, each induced by a learnable mask that selects relevant feature dimensions to model invariance to a specific augmentation. We show the success of MAST in jointly capturing generalizable priors from different augmentations, using both unique and shared features across the subspaces. We further show that MAST benefits from uncertainty modeling to reweight ambiguous samples from strong augmentations that may cause similarity mismatch in each subspace. Experiments demonstrate that MAST consistently improves generalization on various downstream tasks, while being task-agnostic and efficient during SSL. We also provide interesting insights about how different augmentations are related and how uncertainty reflects learning difficulty.
MAEEG: Masked Auto-encoder for EEG Representation Learning
Oct 27, 2022



Decoding information from bio-signals such as EEG, using machine learning has been a challenge due to the small data-sets and difficulty to obtain labels. We propose a reconstruction-based self-supervised learning model, the masked auto-encoder for EEG (MAEEG), for learning EEG representations by learning to reconstruct the masked EEG features using a transformer architecture. We found that MAEEG can learn representations that significantly improve sleep stage classification (~5% accuracy increase) when only a small number of labels are given. We also found that input sample lengths and different ways of masking during reconstruction-based SSL pretraining have a huge effect on downstream model performance. Specifically, learning to reconstruct a larger proportion and more concentrated masked signal results in better performance on sleep classification. Our findings provide insight into how reconstruction-based SSL could help representation learning for EEG.
Towards Multimodal Multitask Scene Understanding Models for Indoor Mobile Agents
Sep 27, 2022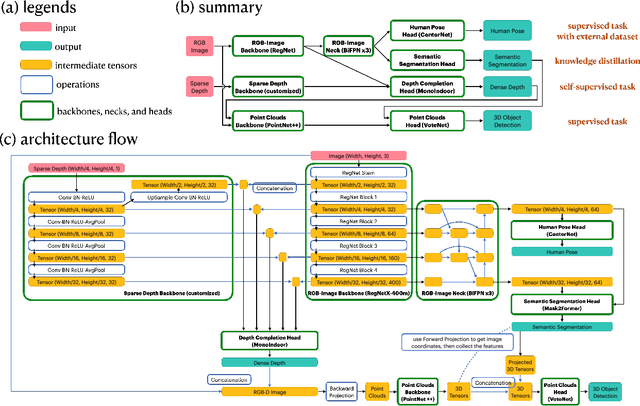
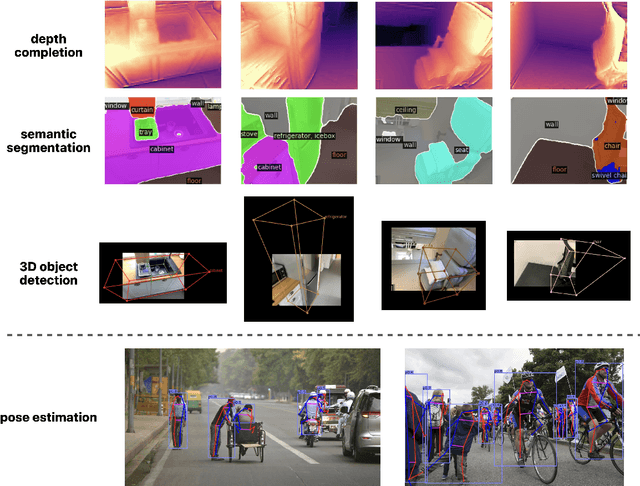
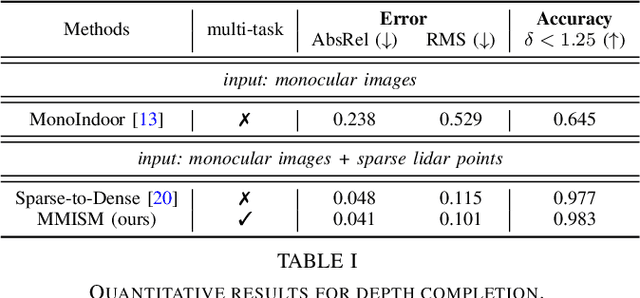
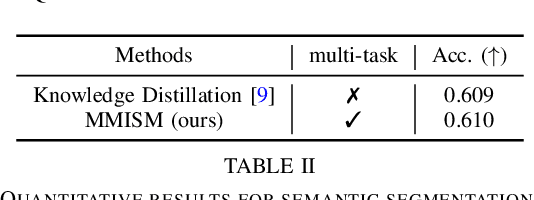
The perception system in personalized mobile agents requires developing indoor scene understanding models, which can understand 3D geometries, capture objectiveness, analyze human behaviors, etc. Nonetheless, this direction has not been well-explored in comparison with models for outdoor environments (e.g., the autonomous driving system that includes pedestrian prediction, car detection, traffic sign recognition, etc.). In this paper, we first discuss the main challenge: insufficient, or even no, labeled data for real-world indoor environments, and other challenges such as fusion between heterogeneous sources of information (e.g., RGB images and Lidar point clouds), modeling relationships between a diverse set of outputs (e.g., 3D object locations, depth estimation, and human poses), and computational efficiency. Then, we describe MMISM (Multi-modality input Multi-task output Indoor Scene understanding Model) to tackle the above challenges. MMISM considers RGB images as well as sparse Lidar points as inputs and 3D object detection, depth completion, human pose estimation, and semantic segmentation as output tasks. We show that MMISM performs on par or even better than single-task models; e.g., we improve the baseline 3D object detection results by 11.7% on the benchmark ARKitScenes dataset.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022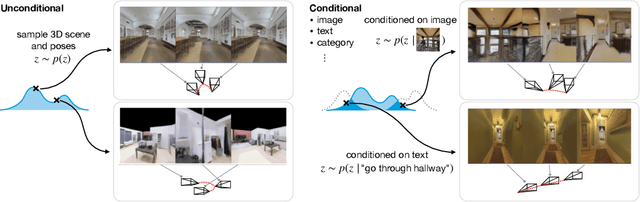
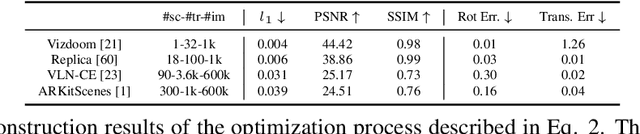
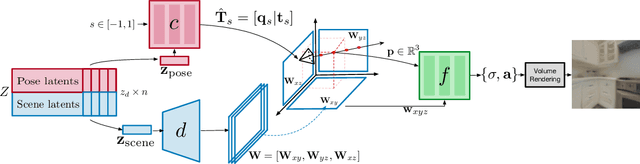

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022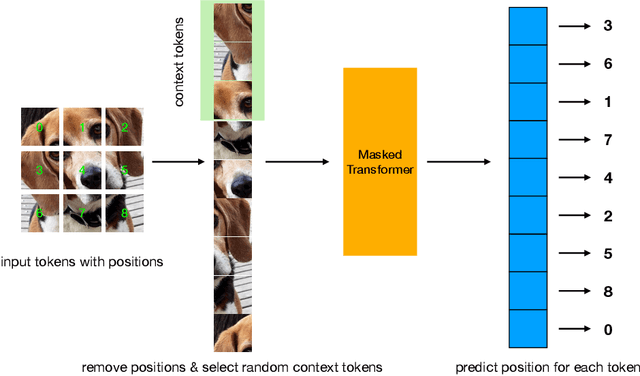


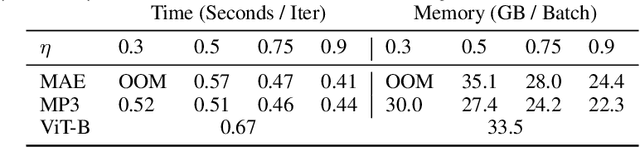
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
Implicit Acceleration and Feature Learning in Infinitely Wide Neural Networks with Bottlenecks
Jul 02, 2021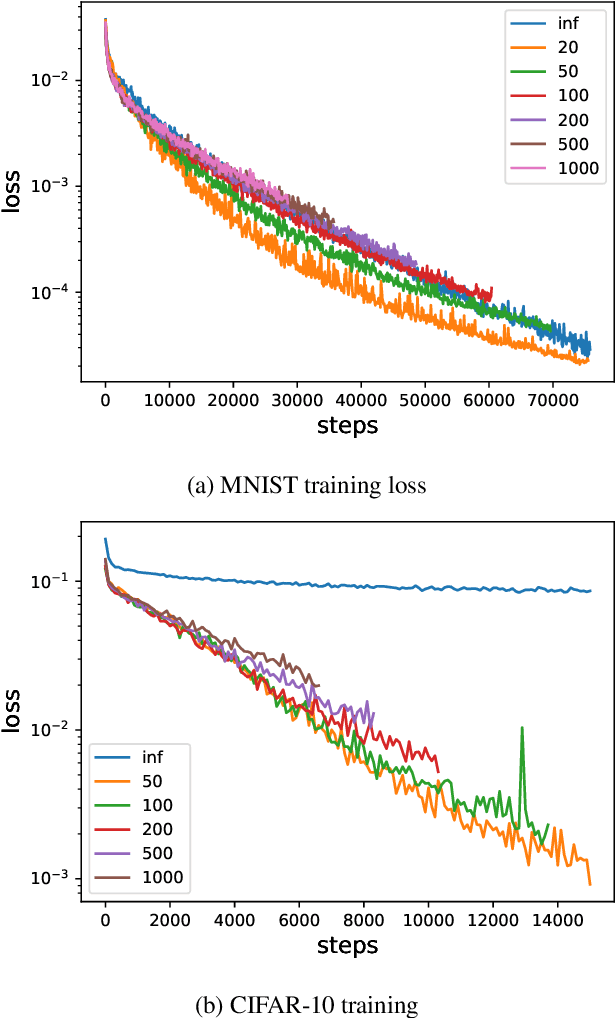
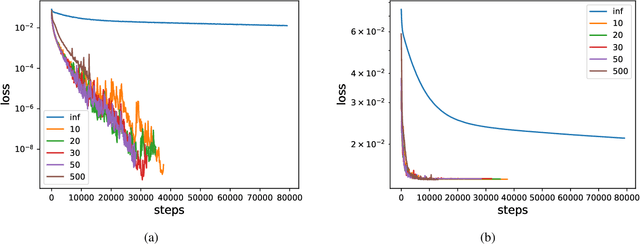
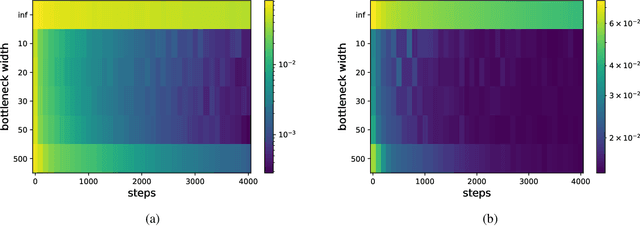
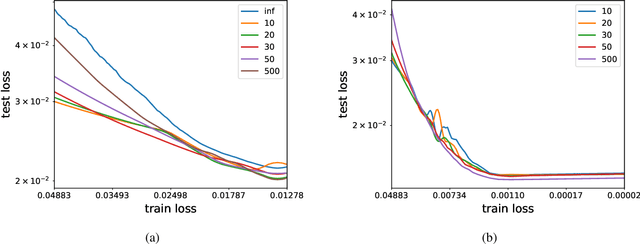
We analyze the learning dynamics of infinitely wide neural networks with a finite sized bottle-neck. Unlike the neural tangent kernel limit, a bottleneck in an otherwise infinite width network al-lows data dependent feature learning in its bottle-neck representation. We empirically show that a single bottleneck in infinite networks dramatically accelerates training when compared to purely in-finite networks, with an improved overall performance. We discuss the acceleration phenomena by drawing similarities to infinitely wide deep linear models, where the acceleration effect of a bottleneck can be understood theoretically.