 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAEEG: Masked Auto-encoder for EEG Representation Learning
Oct 27, 2022



Decoding information from bio-signals such as EEG, using machine learning has been a challenge due to the small data-sets and difficulty to obtain labels. We propose a reconstruction-based self-supervised learning model, the masked auto-encoder for EEG (MAEEG), for learning EEG representations by learning to reconstruct the masked EEG features using a transformer architecture. We found that MAEEG can learn representations that significantly improve sleep stage classification (~5% accuracy increase) when only a small number of labels are given. We also found that input sample lengths and different ways of masking during reconstruction-based SSL pretraining have a huge effect on downstream model performance. Specifically, learning to reconstruct a larger proportion and more concentrated masked signal results in better performance on sleep classification. Our findings provide insight into how reconstruction-based SSL could help representation learning for EEG.
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020
Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.
Subject-Aware Contrastive Learning for Biosignals
Jun 30, 2020

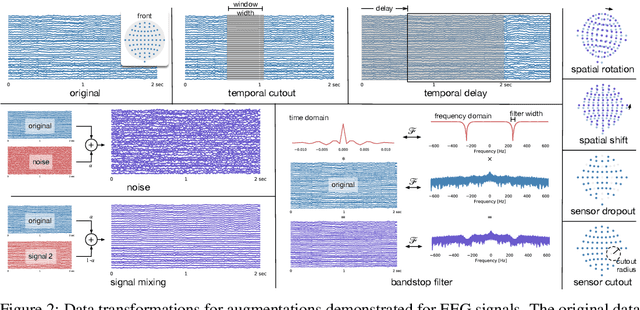

Datasets for biosignals, such as electroencephalogram (EEG) and electrocardiogram (ECG), often have noisy labels and have limited number of subjects (<100). To handle these challenges, we propose a self-supervised approach based on contrastive learning to model biosignals with a reduced reliance on labeled data and with fewer subjects. In this regime of limited labels and subjects, intersubject variability negatively impacts model performance. Thus, we introduce subject-aware learning through (1) a subject-specific contrastive loss, and (2) an adversarial training to promote subject-invariance during the self-supervised learning. We also develop a number of time-series data augmentation techniques to be used with the contrastive loss for biosignals. Our method is evaluated on publicly available datasets of two different biosignals with different tasks: EEG decoding and ECG anomaly detection. The embeddings learned using self-supervision yield competitive classification results compared to entirely supervised methods. We show that subject-invariance improves representation quality for these tasks, and observe that subject-specific loss increases performance when fine-tuning with supervised labels.
Complex-Valued Convolutional Neural Networks for MRI Reconstruction
Apr 08, 2020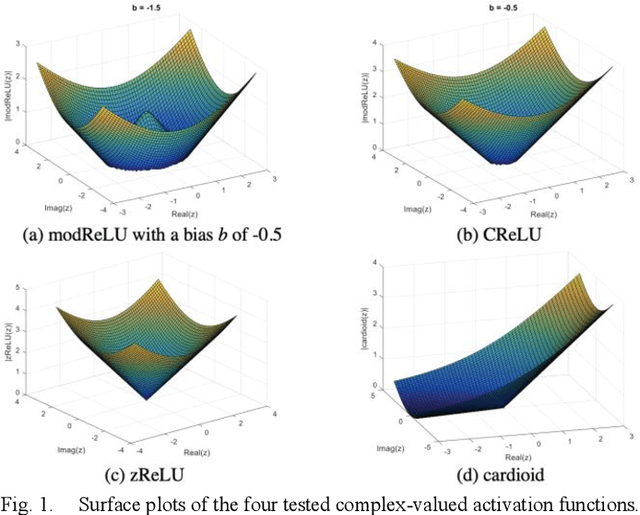
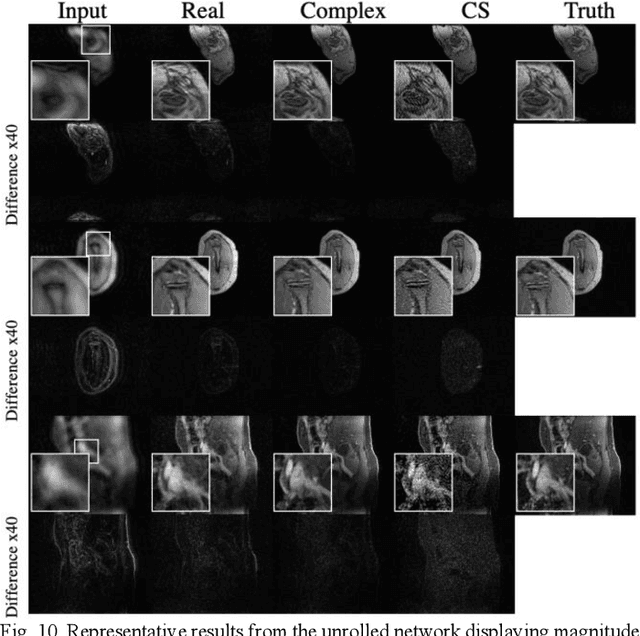

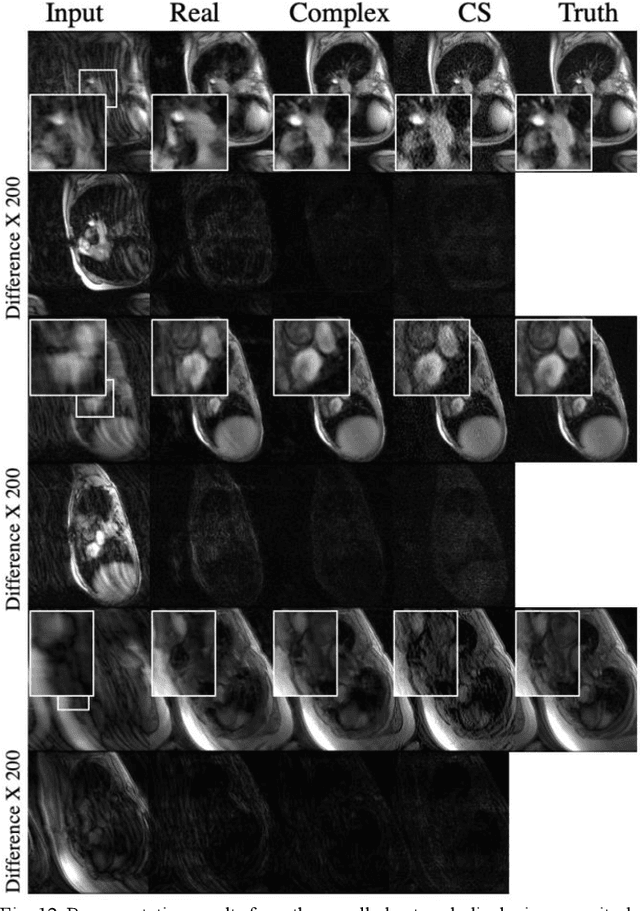
Many real-world signal sources are complex-valued, having real and imaginary components. However, the vast majority of existing deep learning platforms and network architectures do not support the use of complex-valued data. MRI data is inherently complex-valued, so existing approaches discard the richer algebraic structure of the complex data. In this work, we investigate end-to-end complex-valued convolutional neural networks - specifically, for image reconstruction in lieu of two-channel real-valued networks. We apply this to magnetic resonance imaging reconstruction for the purpose of accelerating scan times and determine the performance of various promising complex-valued activation functions. We find that complex-valued CNNs with complex-valued convolutions provide superior reconstructions compared to real-valued convolutions with the same number of trainable parameters, over a variety of network architectures and datasets.
Diagnostic Image Quality Assessment and Classification in Medical Imaging: Opportunities and Challenges
Dec 05, 2019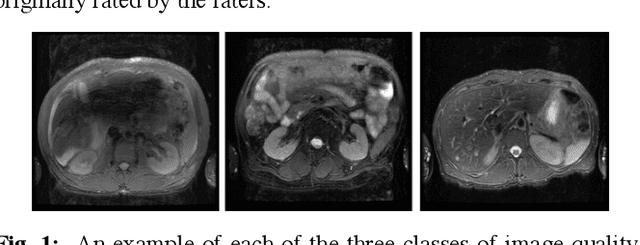
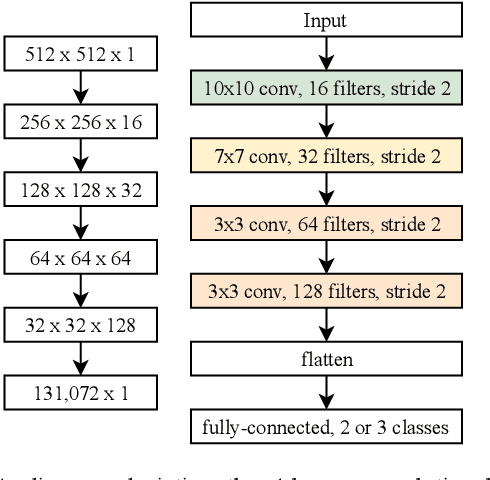
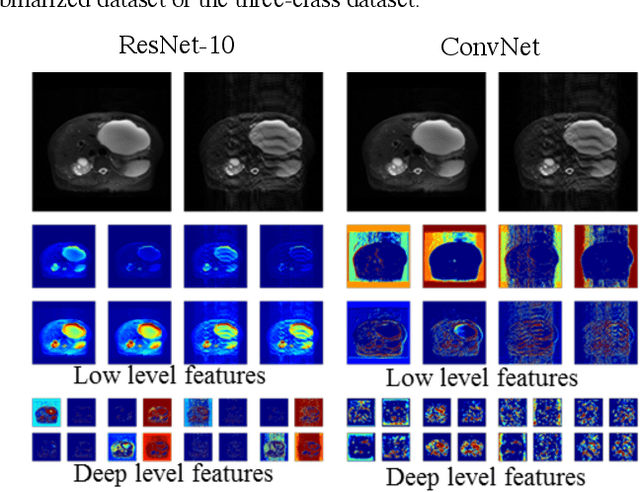
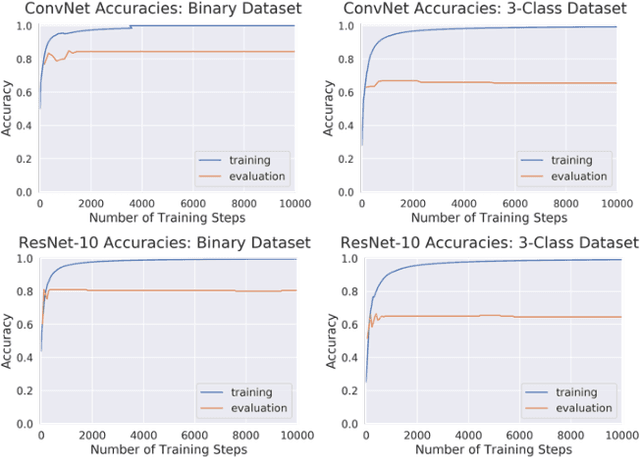
Magnetic Resonance Imaging (MRI) suffers from several artifacts, the most common of which are motion artifacts. These artifacts often yield images that are of non-diagnostic quality. To detect such artifacts, images are prospectively evaluated by experts for their diagnostic quality, which necessitates patient-revisits and rescans whenever non-diagnostic quality scans are encountered. This motivates the need to develop an automated framework capable of accessing medical image quality and detecting diagnostic and non-diagnostic images. In this paper, we explore several convolutional neural network-based frameworks for medical image quality assessment and investigate several challenges therein.
Accelerating cardiac cine MRI beyond compressed sensing using DL-ESPIRiT
Nov 13, 2019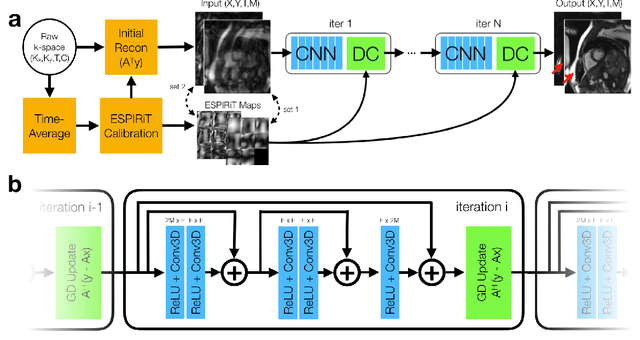
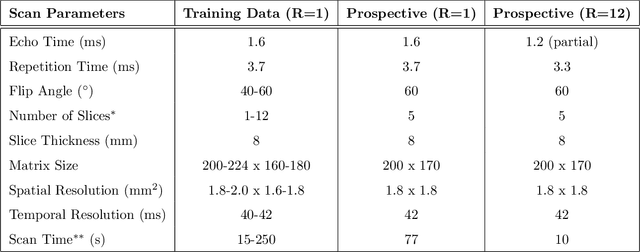
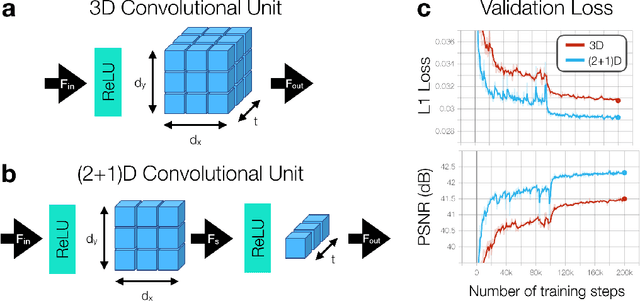
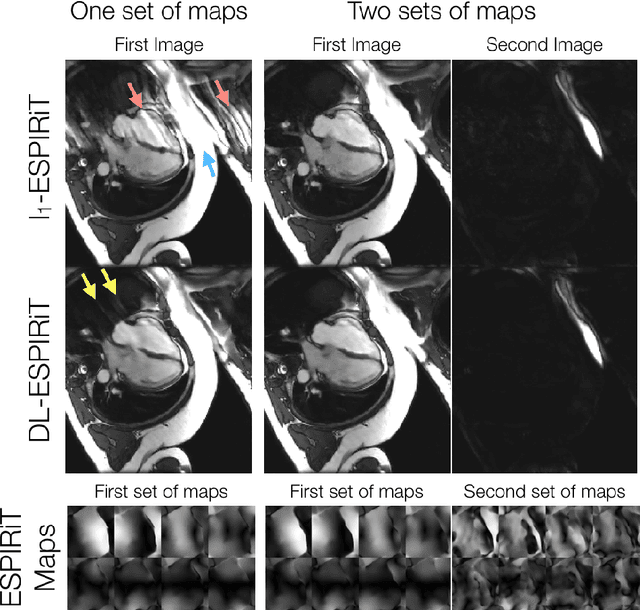
A novel neural network architecture, known as DL-ESPIRiT, is proposed to reconstruct rapidly acquired cardiac MRI data without field-of-view limitations which are present in previously proposed deep learning-based reconstruction frameworks. Additionally, a novel convolutional neural network based on separable 3D convolutions is integrated into DL-ESPIRiT to more efficiently learn spatiotemporal priors for dynamic image reconstruction. The network is trained on fully-sampled 2D cardiac cine datasets collected from eleven healthy volunteers with IRB approval. DL-ESPIRiT is compared against a state-of-the-art parallel imaging and compressed sensing method known as $l_1$-ESPIRiT. The reconstruction accuracy of both methods is evaluated on retrospectively undersampled datasets (R=12) with respect to standard image quality metrics as well as automatic deep learning-based segmentations of left ventricular volumes. Feasibility of this approach is demonstrated in reconstructions of prospectively undersampled data which were acquired in a single heartbeat per slice.
Reconstruction of Undersampled 3D Non-Cartesian Image-Based Navigators for Coronary MRA Using an Unrolled Deep Learning Model
Oct 24, 2019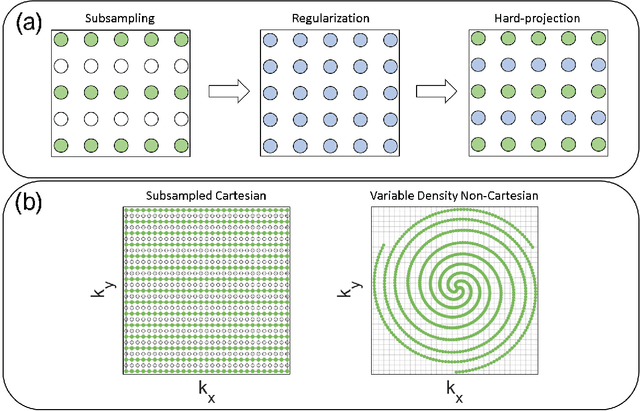

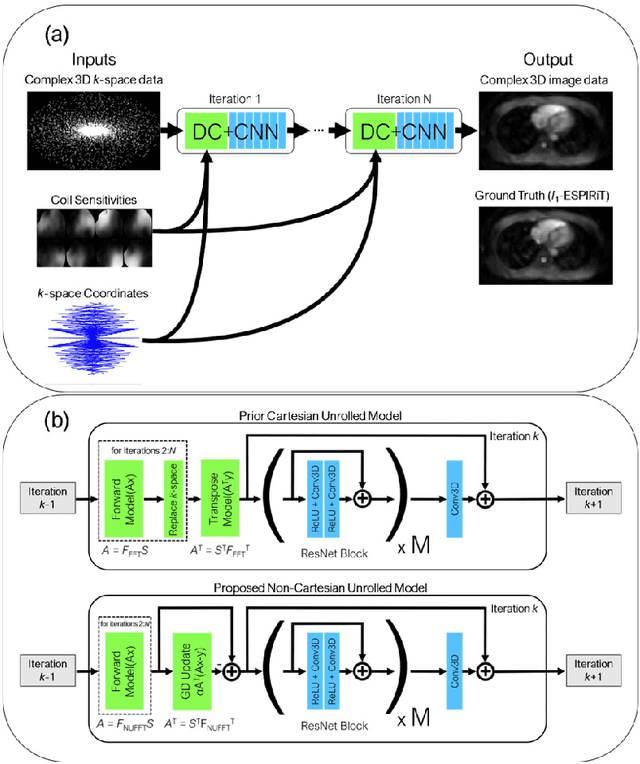
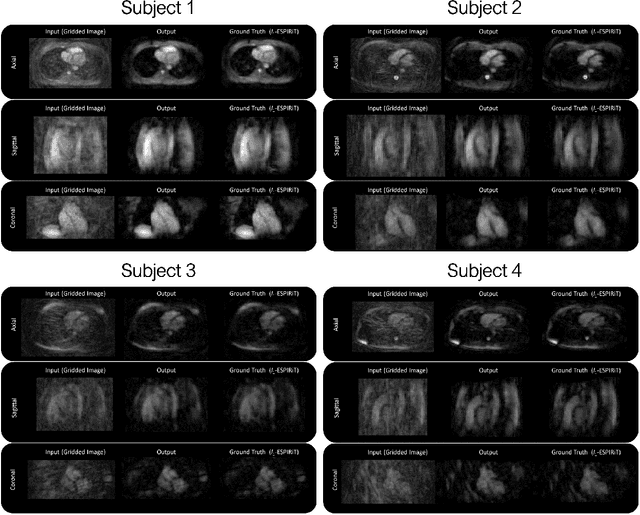
Purpose: To rapidly reconstruct undersampled 3D non-Cartesian image-based navigators (iNAVs) using an unrolled deep learning (DL) model for non-rigid motion correction in coronary magnetic resonance angiography (CMRA). Methods: An unrolled network is trained to reconstruct beat-to-beat 3D iNAVs acquired as part of a CMRA sequence. The unrolled model incorporates a non-uniform FFT operator to perform the data consistency operation, and the regularization term is learned by a convolutional neural network (CNN) based on the proximal gradient descent algorithm. The training set includes 6,000 3D iNAVs acquired from 7 different subjects and 11 scans using a variable-density (VD) cones trajectory. For testing, 3D iNAVs from 4 additional subjects are reconstructed using the unrolled model. To validate reconstruction accuracy, global and localized motion estimates from DL model-based 3D iNAVs are compared with those extracted from 3D iNAVs reconstructed with $\textit{l}_{1}$-ESPIRiT. Then, the high-resolution coronary MRA images motion corrected with autofocusing using the $\textit{l}_{1}$-ESPIRiT and DL model-based 3D iNAVs are assessed for differences. Results: 3D iNAVs reconstructed using the DL model-based approach and conventional $\textit{l}_{1}$-ESPIRiT generate similar global and localized motion estimates and provide equivalent coronary image quality. Reconstruction with the unrolled network completes in a fraction of the time compared to CPU and GPU implementations of $\textit{l}_{1}$-ESPIRiT (20x and 3x speed increases, respectively). Conclusion: We have developed a deep neural network architecture to reconstruct undersampled 3D non-Cartesian VD cones iNAVs. Our approach decreases reconstruction time for 3D iNAVs, while preserving the accuracy of non-rigid motion information offered by them for correction.
Compressed Sensing: From Research to Clinical Practice with Data-Driven Learning
Mar 19, 2019

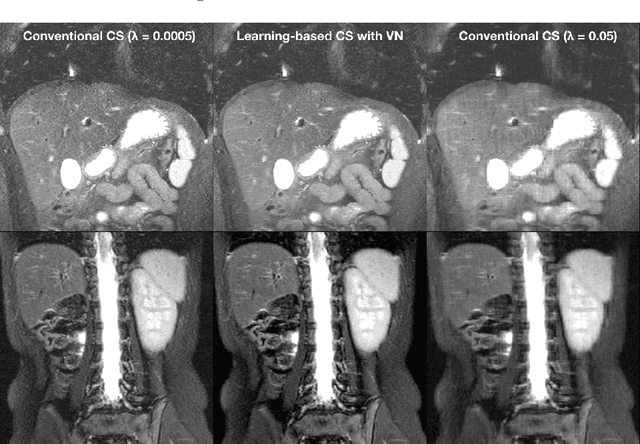
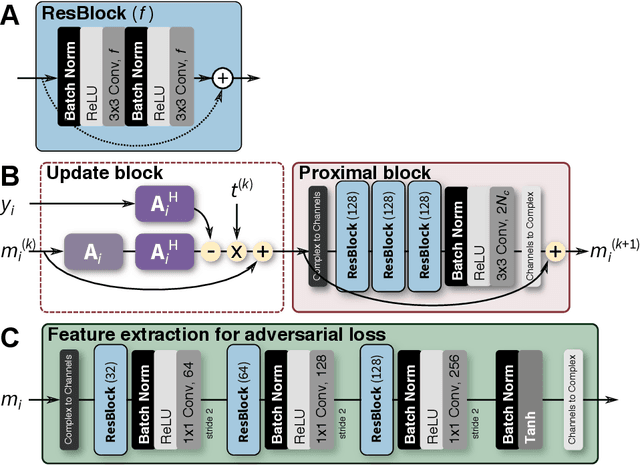
Compressed sensing in MRI enables high subsampling factors while maintaining diagnostic image quality. This technique enables shortened scan durations and/or improved image resolution. Further, compressed sensing can increase the diagnostic information and value from each scan performed. Overall, compressed sensing has significant clinical impact in improving the diagnostic quality and patient experience for imaging exams. However, a number of challenges exist when moving compressed sensing from research to the clinic. These challenges include hand-crafted image priors, sensitive tuning parameters, and long reconstruction times. Data-driven learning provides a solution to address these challenges. As a result, compressed sensing can have greater clinical impact. In this tutorial, we will review the compressed sensing formulation and outline steps needed to transform this formulation to a deep learning framework. Supplementary open source code in python will be used to demonstrate this approach with open databases. Further, we will discuss considerations in applying data-driven compressed sensing in the clinical setting.
Highly Scalable Image Reconstruction using Deep Neural Networks with Bandpass Filtering
May 08, 2018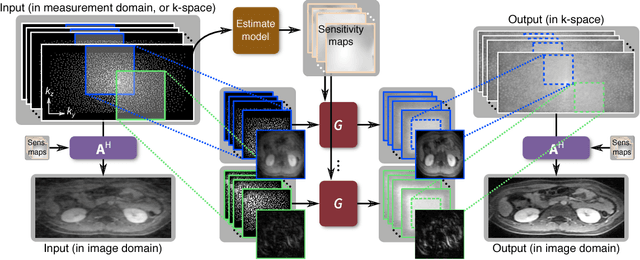
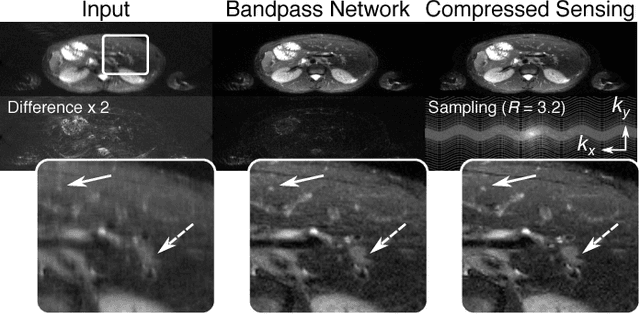
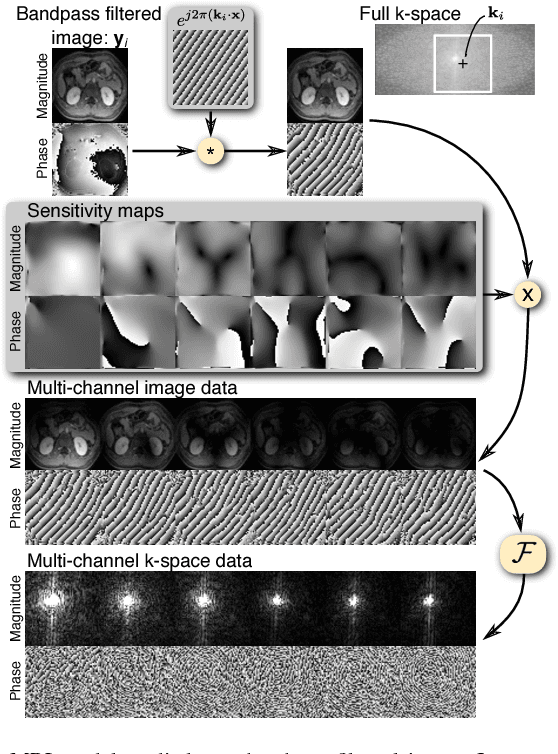
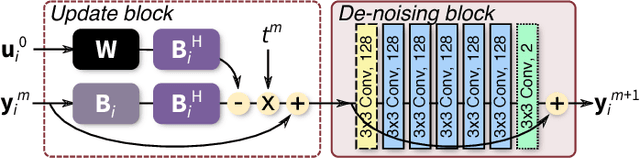
To increase the flexibility and scalability of deep neural networks for image reconstruction, a framework is proposed based on bandpass filtering. For many applications, sensing measurements are performed indirectly. For example, in magnetic resonance imaging, data are sampled in the frequency domain. The introduction of bandpass filtering enables leveraging known imaging physics while ensuring that the final reconstruction is consistent with actual measurements to maintain reconstruction accuracy. We demonstrate this flexible architecture for reconstructing subsampled datasets of MRI scans. The resulting high subsampling rates increase the speed of MRI acquisitions and enable the visualization rapid hemodynamics.
Deep Generative Adversarial Networks for Compressed Sensing Automates MRI
May 31, 2017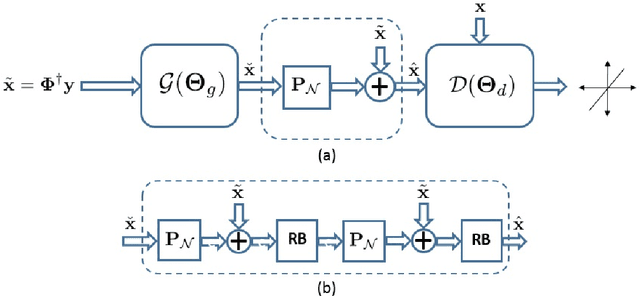
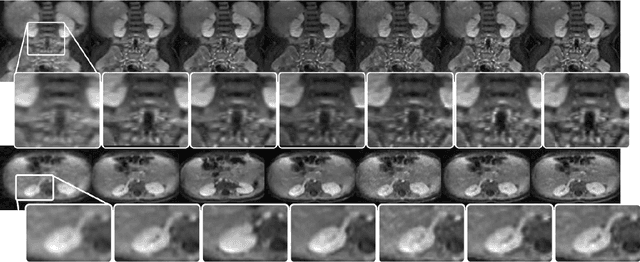
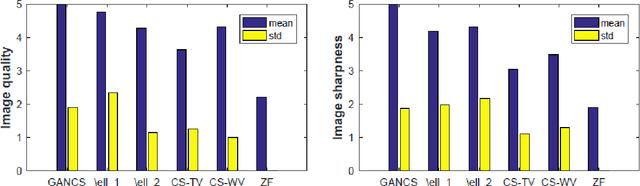
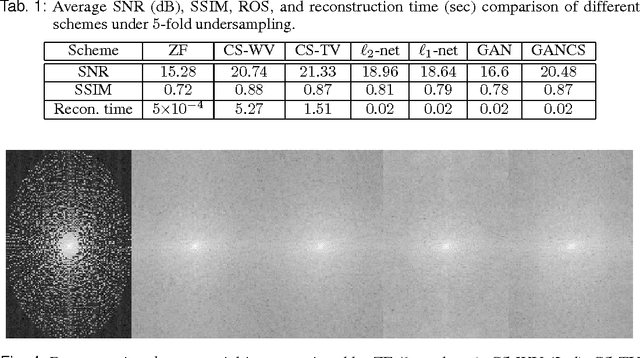
Magnetic resonance image (MRI) reconstruction is a severely ill-posed linear inverse task demanding time and resource intensive computations that can substantially trade off {\it accuracy} for {\it speed} in real-time imaging. In addition, state-of-the-art compressed sensing (CS) analytics are not cognizant of the image {\it diagnostic quality}. To cope with these challenges we put forth a novel CS framework that permeates benefits from generative adversarial networks (GAN) to train a (low-dimensional) manifold of diagnostic-quality MR images from historical patients. Leveraging a mixture of least-squares (LS) GANs and pixel-wise $\ell_1$ cost, a deep residual network with skip connections is trained as the generator that learns to remove the {\it aliasing} artifacts by projecting onto the manifold. LSGAN learns the texture details, while $\ell_1$ controls the high-frequency noise. A multilayer convolutional neural network is then jointly trained based on diagnostic quality images to discriminate the projection quality. The test phase performs feed-forward propagation over the generator network that demands a very low computational overhead. Extensive evaluations are performed on a large contrast-enhanced MR dataset of pediatric patients. In particular, images rated based on expert radiologists corroborate that GANCS retrieves high contrast images with detailed texture relative to conventional CS, and pixel-wise schemes. In addition, it offers reconstruction under a few milliseconds, two orders of magnitude faster than state-of-the-art CS-MRI schemes.