 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Robust Deep Reconstruction for Free-Breathing Cardiac Cine MRI
May 20, 2026Conventional cardiac cine MRI relies on breath-hold Cartesian acquisitions, which are vulnerable to motion artifacts and can be uncomfortable or infeasible, particularly for pediatric and other noncompliant patients who cannot reliably hold their breath. Free-breathing radial acquisitions can alleviate these limitations, but robust reconstruction at high acceleration remains challenging due to prominent streak artifacts. To address these limitations, we propose Cine-DL, a clinically oriented framework that couples targeted k-space preprocessing with fast, model-based deep reconstruction. In this pipeline, raw free-breathing radial data undergo retrospective cardiac binning and respiratory gating to resolve cardiac phases and discard motion-corrupted spokes. We then introduce Streak Optimized Coil Compression (SOC), which explicitly preserves cardiac signals while suppressing peripheral interference that typically drives the streak artifacts. The resulting 2D+t cine series is reconstructed with an unrolled network that alternates a ResNet proximal operator with physics-based data consistency updates solved via conjugate gradient. We further employ a memory-efficient training strategy that reduces peak memory usage. We evaluate Cine-DL on free-breathing volunteer data against established baselines (k-t SENSE and iGRASP) and demonstrate clinical translation via hospital deployment on newly acquired patient data. Our experiments show that Cine-DL consistently improves quantitative metrics and visual fidelity, supporting a practical route toward routine, time-sensitive clinical adoption of free-breathing cine MRI.
Principled Design of Diffusion-based Optimizers for Inverse Problems
May 12, 2026Score-based diffusion models achieve state-of-the-art performance for inverse problems, but their practical deployment is hindered by long inference times and cumbersome hyperparameter tuning. While pretrained diffusion models can be reused across tasks without retraining, inference-time hyperparameters such as the noise schedule and posterior sampling weights typically require ad-hoc adjustment for each problem setup. We propose principled reparameterizations that induce invariances, allowing the same hyperparameters to be reused across multiple problems without re-tuning. In addition, building on the RED-diff framework, which reformulates posterior sampling as an optimization problem, we further develop the OptDiff pipeline. OptDiff provides a simplified tuning framework that facilitates the integration of convex optimization tools to accelerate inference. Experiments on image reconstruction, deblurring, and super-resolution show substantial speedups and improved image quality.
Scale-Agnostic Super-Resolution in MRI using Feature-Based Coordinate Networks
Oct 18, 2022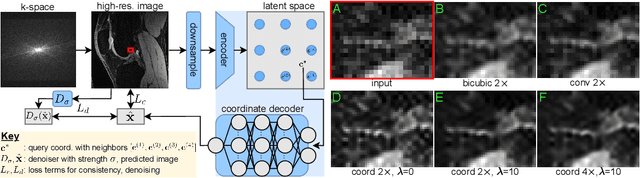
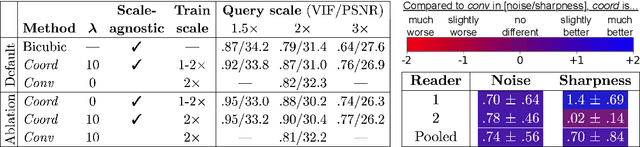
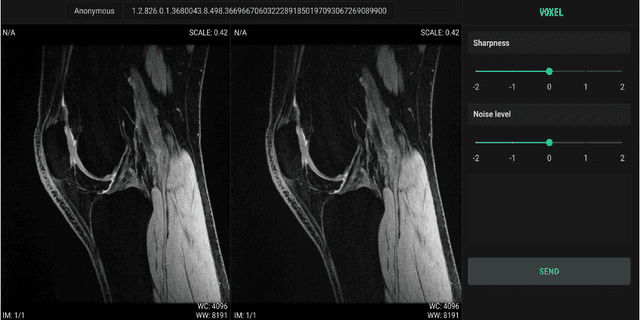
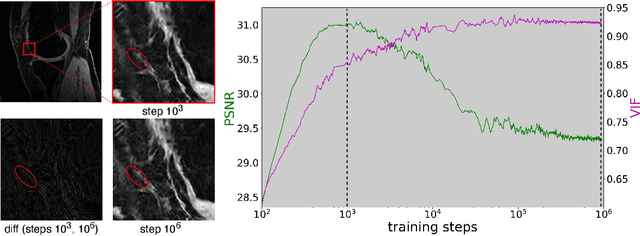
We propose using a coordinate network decoder for the task of super-resolution in MRI. The continuous signal representation of coordinate networks enables this approach to be scale-agnostic, i.e. one can train over a continuous range of scales and subsequently query at arbitrary resolutions. Due to the difficulty of performing super-resolution on inherently noisy data, we analyze network behavior under multiple denoising strategies. Lastly we compare this method to a standard convolutional decoder using both quantitative metrics and a radiologist study implemented in Voxel, our newly developed tool for web-based evaluation of medical images.
GLEAM: Greedy Learning for Large-Scale Accelerated MRI Reconstruction
Jul 18, 2022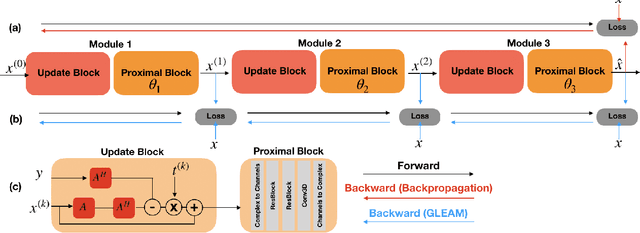
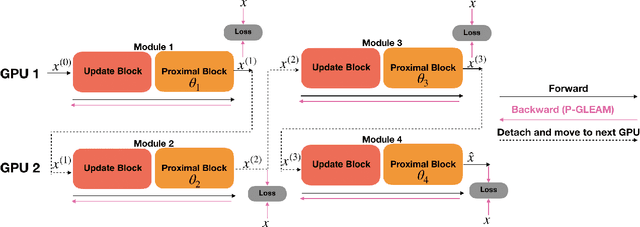
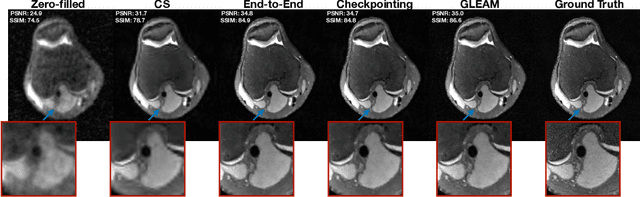
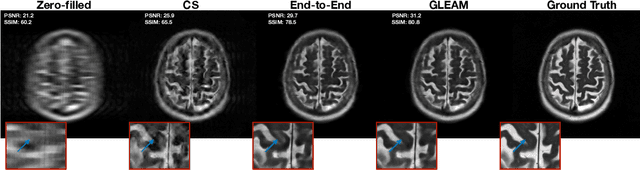
Unrolled neural networks have recently achieved state-of-the-art accelerated MRI reconstruction. These networks unroll iterative optimization algorithms by alternating between physics-based consistency and neural-network based regularization. However, they require several iterations of a large neural network to handle high-dimensional imaging tasks such as 3D MRI. This limits traditional training algorithms based on backpropagation due to prohibitively large memory and compute requirements for calculating gradients and storing intermediate activations. To address this challenge, we propose Greedy LEarning for Accelerated MRI (GLEAM) reconstruction, an efficient training strategy for high-dimensional imaging settings. GLEAM splits the end-to-end network into decoupled network modules. Each module is optimized in a greedy manner with decoupled gradient updates, reducing the memory footprint during training. We show that the decoupled gradient updates can be performed in parallel on multiple graphical processing units (GPUs) to further reduce training time. We present experiments with 2D and 3D datasets including multi-coil knee, brain, and dynamic cardiac cine MRI. We observe that: i) GLEAM generalizes as well as state-of-the-art memory-efficient baselines such as gradient checkpointing and invertible networks with the same memory footprint, but with 1.3x faster training; ii) for the same memory footprint, GLEAM yields 1.1dB PSNR gain in 2D and 1.8 dB in 3D over end-to-end baselines.
Scale-Equivariant Unrolled Neural Networks for Data-Efficient Accelerated MRI Reconstruction
Apr 21, 2022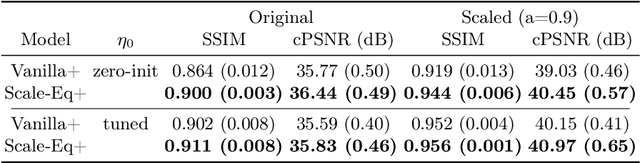
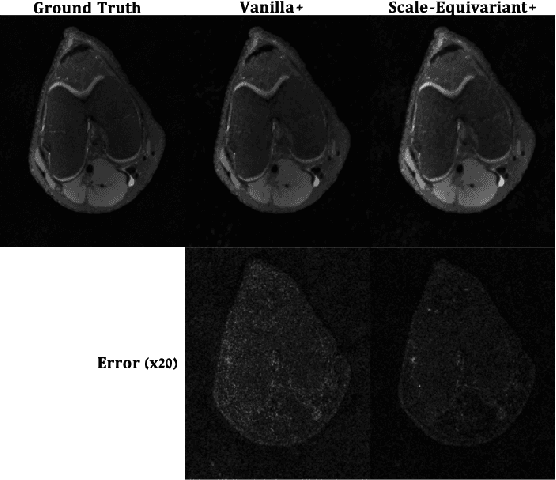
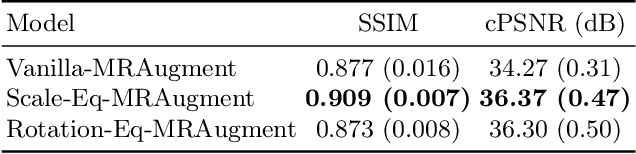
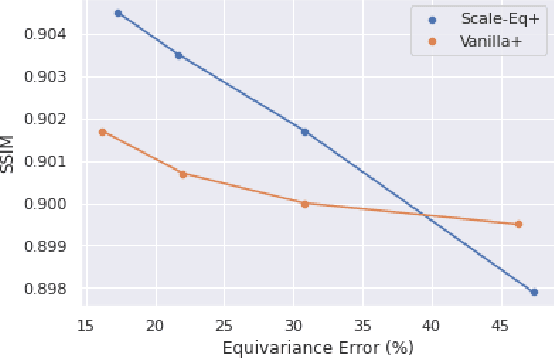
Unrolled neural networks have enabled state-of-the-art reconstruction performance and fast inference times for the accelerated magnetic resonance imaging (MRI) reconstruction task. However, these approaches depend on fully-sampled scans as ground truth data which is either costly or not possible to acquire in many clinical medical imaging applications; hence, reducing dependence on data is desirable. In this work, we propose modeling the proximal operators of unrolled neural networks with scale-equivariant convolutional neural networks in order to improve the data-efficiency and robustness to drifts in scale of the images that might stem from the variability of patient anatomies or change in field-of-view across different MRI scanners. Our approach demonstrates strong improvements over the state-of-the-art unrolled neural networks under the same memory constraints both with and without data augmentations on both in-distribution and out-of-distribution scaled images without significantly increasing the train or inference time.
VORTEX: Physics-Driven Data Augmentations for Consistency Training for Robust Accelerated MRI Reconstruction
Nov 03, 2021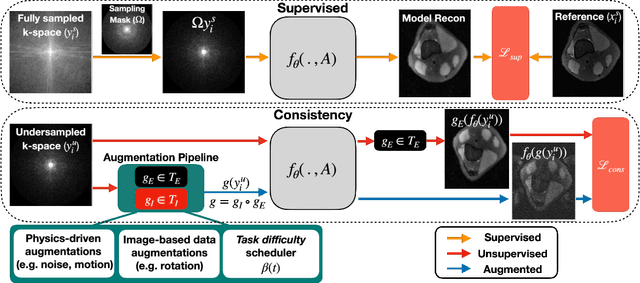
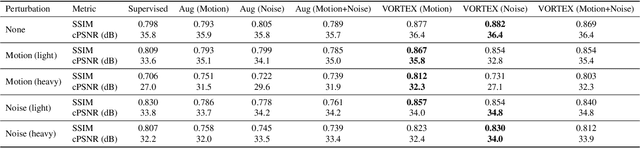
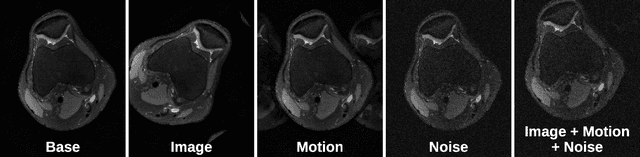
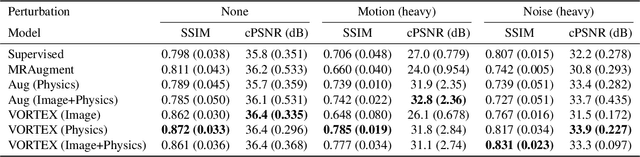
Deep neural networks have enabled improved image quality and fast inference times for various inverse problems, including accelerated magnetic resonance imaging (MRI) reconstruction. However, such models require large amounts of fully-sampled ground truth data, which are difficult to curate and are sensitive to distribution drifts. In this work, we propose applying physics-driven data augmentations for consistency training that leverage our domain knowledge of the forward MRI data acquisition process and MRI physics for improved data efficiency and robustness to clinically-relevant distribution drifts. Our approach, termed VORTEX (1) demonstrates strong improvements over supervised baselines with and without augmentation in robustness to signal-to-noise ratio change and motion corruption in data-limited regimes; (2) considerably outperforms state-of-the-art data augmentation techniques that are purely image-based on both in-distribution and out-of-distribution data; and (3) enables composing heterogeneous image-based and physics-driven augmentations.
Noise2Recon: A Semi-Supervised Framework for Joint MRI Reconstruction and Denoising
Sep 30, 2021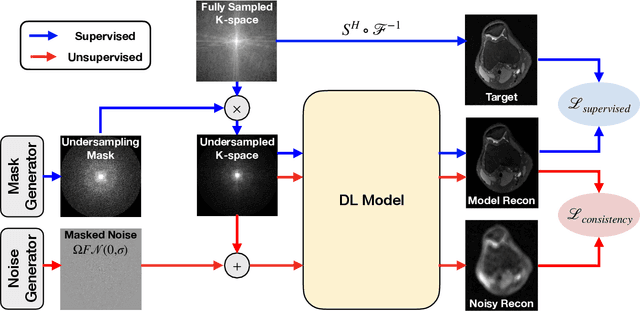
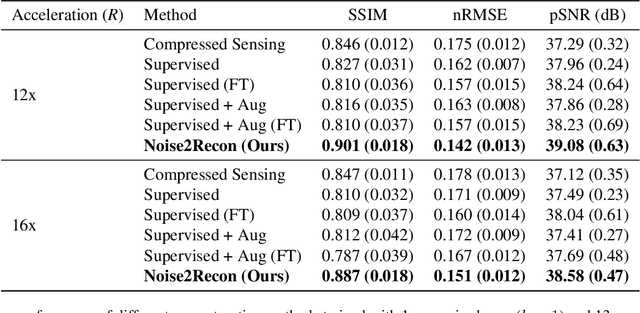
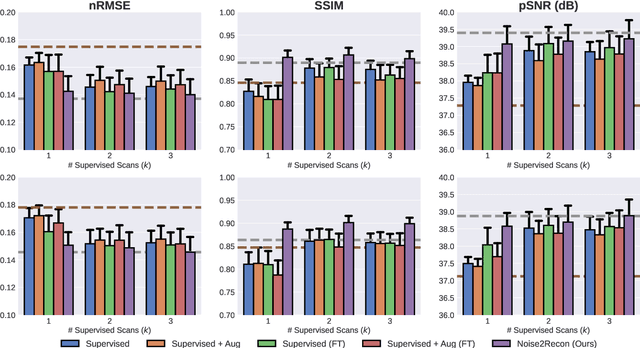

Deep learning (DL) has shown promise for faster, high quality accelerated MRI reconstruction. However, standard supervised DL methods depend on extensive amounts of fully-sampled ground-truth data and are sensitive to out-of-distribution (OOD) shifts, in particular for low signal-to-noise ratio (SNR) acquisitions. To alleviate this challenge, we propose a semi-supervised, consistency-based framework (termed Noise2Recon) for joint MR reconstruction and denoising. Our method enables the usage of a limited number of fully-sampled and a large number of undersampled-only scans. We compare our method to augmentation-based supervised techniques and fine-tuned denoisers. Results demonstrate that even with minimal ground-truth data, Noise2Recon (1) achieves high performance on in-distribution (low-noise) scans and (2) improves generalizability to OOD, noisy scans.
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020
Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.
Diagnostic Image Quality Assessment and Classification in Medical Imaging: Opportunities and Challenges
Dec 05, 2019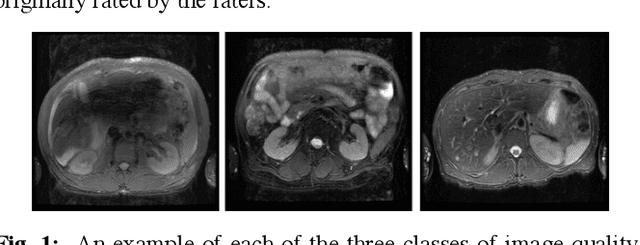
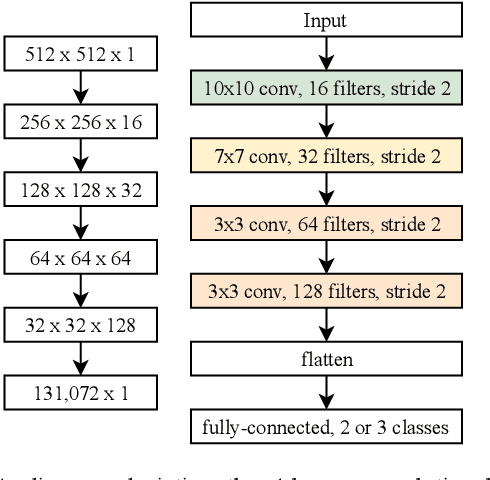
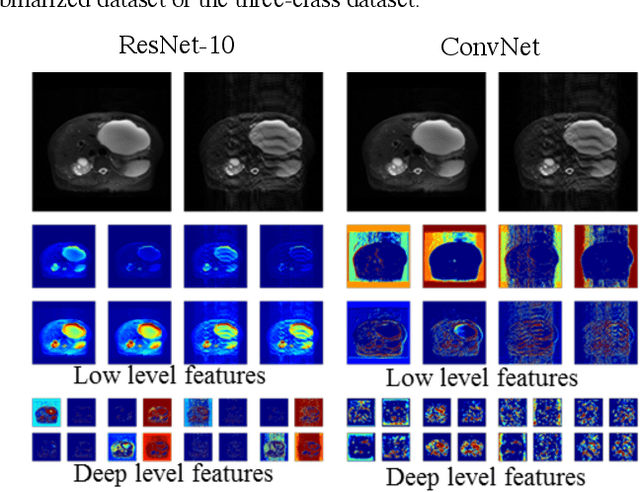
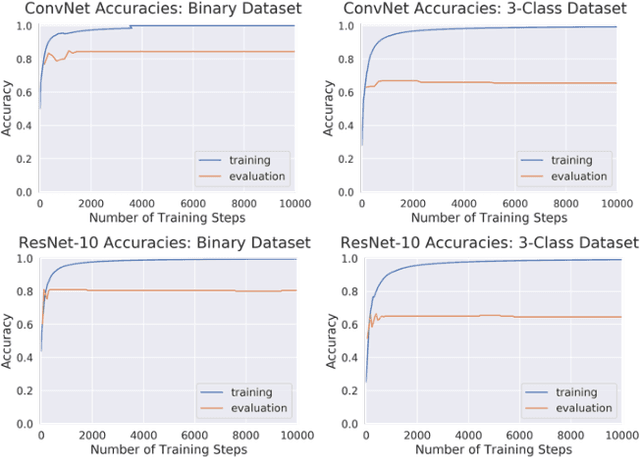
Magnetic Resonance Imaging (MRI) suffers from several artifacts, the most common of which are motion artifacts. These artifacts often yield images that are of non-diagnostic quality. To detect such artifacts, images are prospectively evaluated by experts for their diagnostic quality, which necessitates patient-revisits and rescans whenever non-diagnostic quality scans are encountered. This motivates the need to develop an automated framework capable of accessing medical image quality and detecting diagnostic and non-diagnostic images. In this paper, we explore several convolutional neural network-based frameworks for medical image quality assessment and investigate several challenges therein.
Degrees of Freedom Analysis of Unrolled Neural Networks
Jun 10, 2019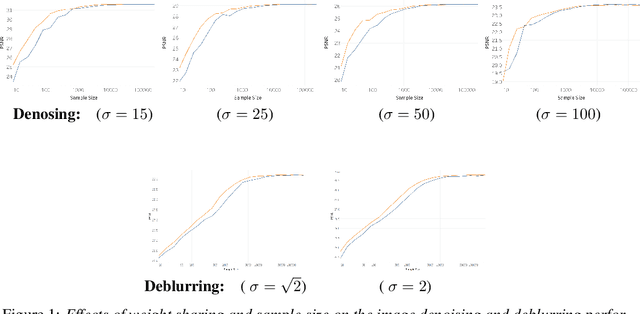
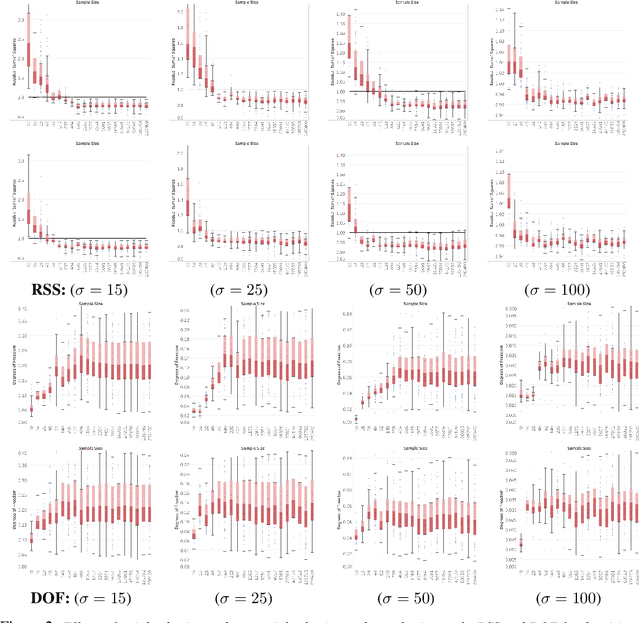
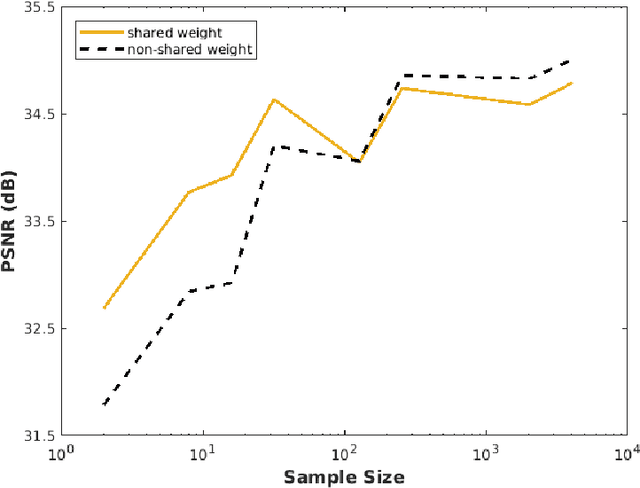
Unrolled neural networks emerged recently as an effective model for learning inverse maps appearing in image restoration tasks. However, their generalization risk (i.e., test mean-squared-error) and its link to network design and train sample size remains mysterious. Leveraging the Stein's Unbiased Risk Estimator (SURE), this paper analyzes the generalization risk with its bias and variance components for recurrent unrolled networks. We particularly investigate the degrees-of-freedom (DOF) component of SURE, trace of the end-to-end network Jacobian, to quantify the prediction variance. We prove that DOF is well-approximated by the weighted \textit{path sparsity} of the network under incoherence conditions on the trained weights. Empirically, we examine the SURE components as a function of train sample size for both recurrent and non-recurrent (with many more parameters) unrolled networks. Our key observations indicate that: 1) DOF increases with train sample size and converges to the generalization risk for both recurrent and non-recurrent schemes; 2) recurrent network converges significantly faster (with less train samples) compared with non-recurrent scheme, hence recurrence serves as a regularization for low sample size regimes.