 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAM: Greedy Learning for Large-Scale Accelerated MRI Reconstruction
Jul 18, 2022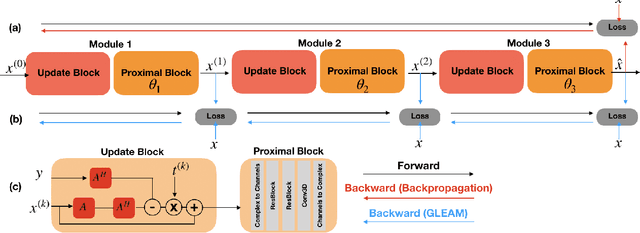
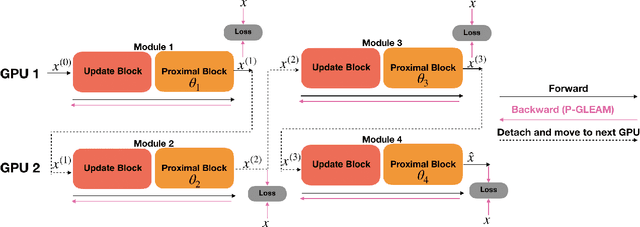
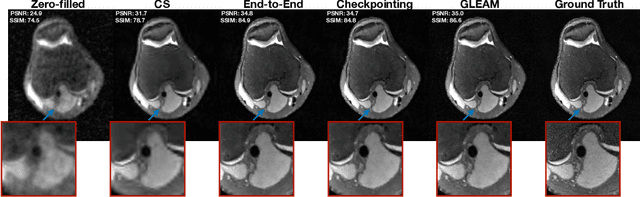
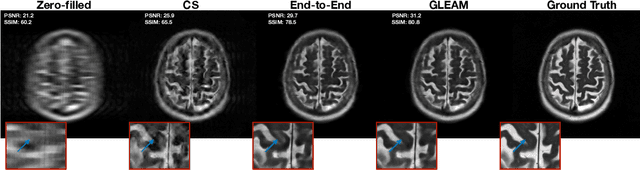
Unrolled neural networks have recently achieved state-of-the-art accelerated MRI reconstruction. These networks unroll iterative optimization algorithms by alternating between physics-based consistency and neural-network based regularization. However, they require several iterations of a large neural network to handle high-dimensional imaging tasks such as 3D MRI. This limits traditional training algorithms based on backpropagation due to prohibitively large memory and compute requirements for calculating gradients and storing intermediate activations. To address this challenge, we propose Greedy LEarning for Accelerated MRI (GLEAM) reconstruction, an efficient training strategy for high-dimensional imaging settings. GLEAM splits the end-to-end network into decoupled network modules. Each module is optimized in a greedy manner with decoupled gradient updates, reducing the memory footprint during training. We show that the decoupled gradient updates can be performed in parallel on multiple graphical processing units (GPUs) to further reduce training time. We present experiments with 2D and 3D datasets including multi-coil knee, brain, and dynamic cardiac cine MRI. We observe that: i) GLEAM generalizes as well as state-of-the-art memory-efficient baselines such as gradient checkpointing and invertible networks with the same memory footprint, but with 1.3x faster training; ii) for the same memory footprint, GLEAM yields 1.1dB PSNR gain in 2D and 1.8 dB in 3D over end-to-end baselines.
SKM-TEA: A Dataset for Accelerated MRI Reconstruction with Dense Image Labels for Quantitative Clinical Evaluation
Mar 14, 2022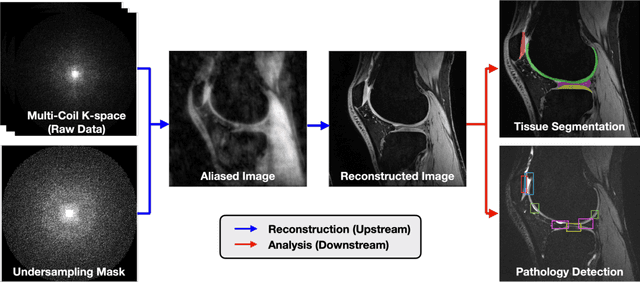
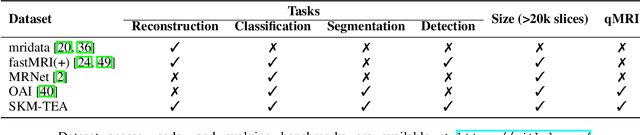
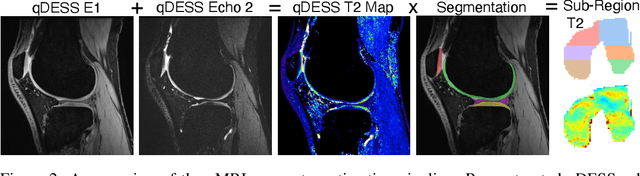
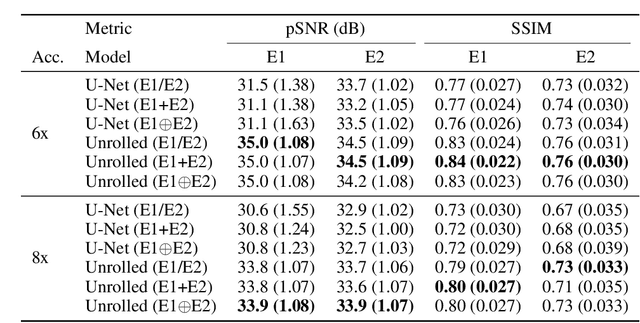
Magnetic resonance imaging (MRI) is a cornerstone of modern medical imaging. However, long image acquisition times, the need for qualitative expert analysis, and the lack of (and difficulty extracting) quantitative indicators that are sensitive to tissue health have curtailed widespread clinical and research studies. While recent machine learning methods for MRI reconstruction and analysis have shown promise for reducing this burden, these techniques are primarily validated with imperfect image quality metrics, which are discordant with clinically-relevant measures that ultimately hamper clinical deployment and clinician trust. To mitigate this challenge, we present the Stanford Knee MRI with Multi-Task Evaluation (SKM-TEA) dataset, a collection of quantitative knee MRI (qMRI) scans that enables end-to-end, clinically-relevant evaluation of MRI reconstruction and analysis tools. This 1.6TB dataset consists of raw-data measurements of ~25,000 slices (155 patients) of anonymized patient MRI scans, the corresponding scanner-generated DICOM images, manual segmentations of four tissues, and bounding box annotations for sixteen clinically relevant pathologies. We provide a framework for using qMRI parameter maps, along with image reconstructions and dense image labels, for measuring the quality of qMRI biomarker estimates extracted from MRI reconstruction, segmentation, and detection techniques. Finally, we use this framework to benchmark state-of-the-art baselines on this dataset. We hope our SKM-TEA dataset and code can enable a broad spectrum of research for modular image reconstruction and image analysis in a clinically informed manner. Dataset access, code, and benchmarks are available at https://github.com/StanfordMIMI/skm-tea.
VORTEX: Physics-Driven Data Augmentations for Consistency Training for Robust Accelerated MRI Reconstruction
Nov 03, 2021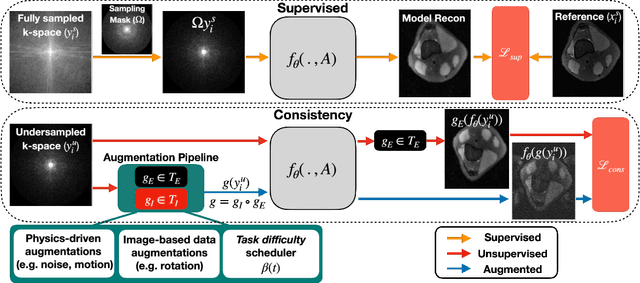
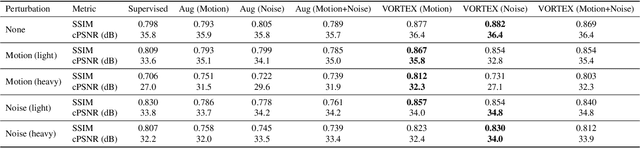
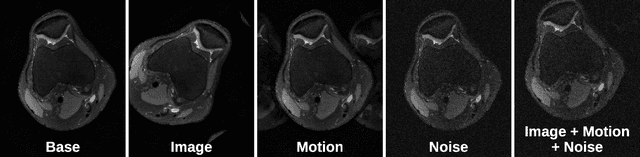
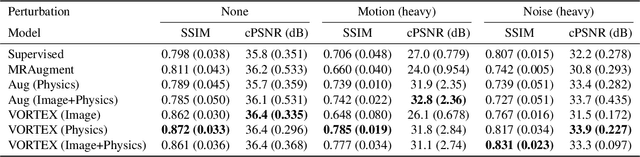
Deep neural networks have enabled improved image quality and fast inference times for various inverse problems, including accelerated magnetic resonance imaging (MRI) reconstruction. However, such models require large amounts of fully-sampled ground truth data, which are difficult to curate and are sensitive to distribution drifts. In this work, we propose applying physics-driven data augmentations for consistency training that leverage our domain knowledge of the forward MRI data acquisition process and MRI physics for improved data efficiency and robustness to clinically-relevant distribution drifts. Our approach, termed VORTEX (1) demonstrates strong improvements over supervised baselines with and without augmentation in robustness to signal-to-noise ratio change and motion corruption in data-limited regimes; (2) considerably outperforms state-of-the-art data augmentation techniques that are purely image-based on both in-distribution and out-of-distribution data; and (3) enables composing heterogeneous image-based and physics-driven augmentations.
Noise2Recon: A Semi-Supervised Framework for Joint MRI Reconstruction and Denoising
Sep 30, 2021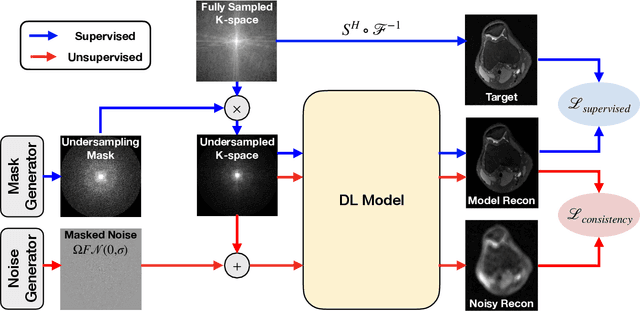
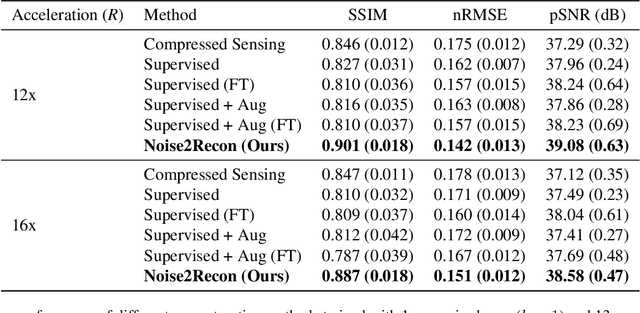
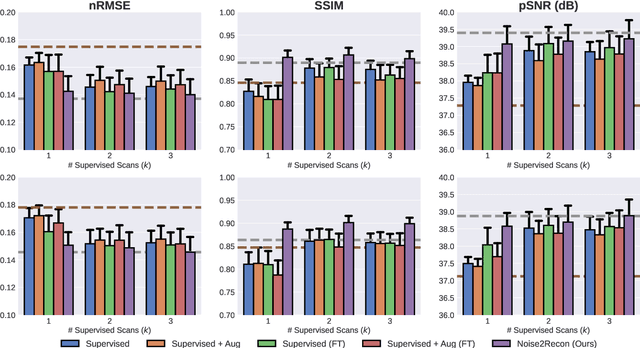

Deep learning (DL) has shown promise for faster, high quality accelerated MRI reconstruction. However, standard supervised DL methods depend on extensive amounts of fully-sampled ground-truth data and are sensitive to out-of-distribution (OOD) shifts, in particular for low signal-to-noise ratio (SNR) acquisitions. To alleviate this challenge, we propose a semi-supervised, consistency-based framework (termed Noise2Recon) for joint MR reconstruction and denoising. Our method enables the usage of a limited number of fully-sampled and a large number of undersampled-only scans. We compare our method to augmentation-based supervised techniques and fine-tuned denoisers. Results demonstrate that even with minimal ground-truth data, Noise2Recon (1) achieves high performance on in-distribution (low-noise) scans and (2) improves generalizability to OOD, noisy scans.