 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAM: Greedy Learning for Large-Scale Accelerated MRI Reconstruction
Paper and Code
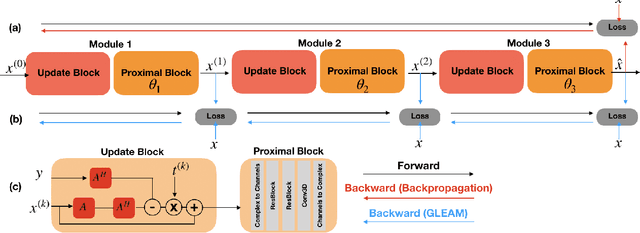
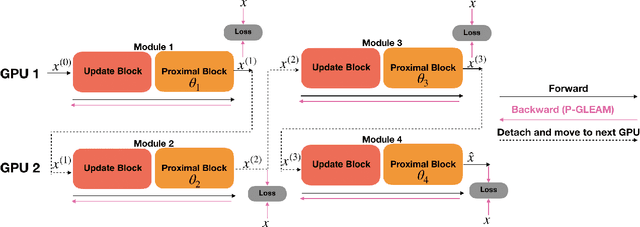
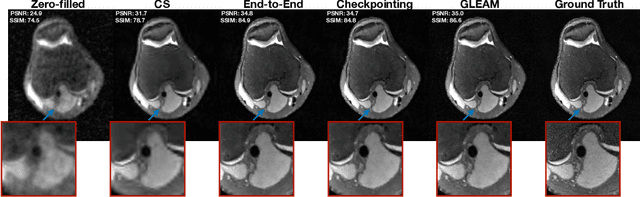
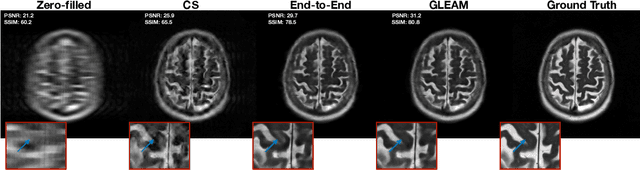
Unrolled neural networks have recently achieved state-of-the-art accelerated MRI reconstruction. These networks unroll iterative optimization algorithms by alternating between physics-based consistency and neural-network based regularization. However, they require several iterations of a large neural network to handle high-dimensional imaging tasks such as 3D MRI. This limits traditional training algorithms based on backpropagation due to prohibitively large memory and compute requirements for calculating gradients and storing intermediate activations. To address this challenge, we propose Greedy LEarning for Accelerated MRI (GLEAM) reconstruction, an efficient training strategy for high-dimensional imaging settings. GLEAM splits the end-to-end network into decoupled network modules. Each module is optimized in a greedy manner with decoupled gradient updates, reducing the memory footprint during training. We show that the decoupled gradient updates can be performed in parallel on multiple graphical processing units (GPUs) to further reduce training time. We present experiments with 2D and 3D datasets including multi-coil knee, brain, and dynamic cardiac cine MRI. We observe that: i) GLEAM generalizes as well as state-of-the-art memory-efficient baselines such as gradient checkpointing and invertible networks with the same memory footprint, but with 1.3x faster training; ii) for the same memory footprint, GLEAM yields 1.1dB PSNR gain in 2D and 1.8 dB in 3D over end-to-end baselines.