 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Range Tasks Using Short-Context LLMs: Incremental Reasoning With Structured Memories
Dec 25, 2024



Long-range tasks require reasoning over long inputs. Existing solutions either need large compute budgets, training data, access to model weights, or use complex, task-specific approaches. We present PRISM, which alleviates these concerns by processing information as a stream of chunks, maintaining a structured in-context memory specified by a typed hierarchy schema. This approach demonstrates superior performance to baselines on diverse tasks while using at least 4x smaller contexts than long-context models. Moreover, PRISM is token-efficient. By producing short outputs and efficiently leveraging key-value (KV) caches, it achieves up to 54% cost reduction when compared to alternative short-context approaches. The method also scales down to tiny information chunks (e.g., 500 tokens) without increasing the number of tokens encoded or sacrificing quality. Furthermore, we show that it is possible to generate schemas to generalize our approach to new tasks with minimal effort.
MLAN: Language-Based Instruction Tuning Improves Zero-Shot Generalization of Multimodal Large Language Models
Nov 19, 2024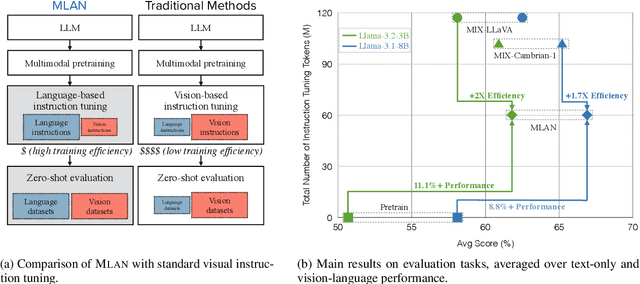
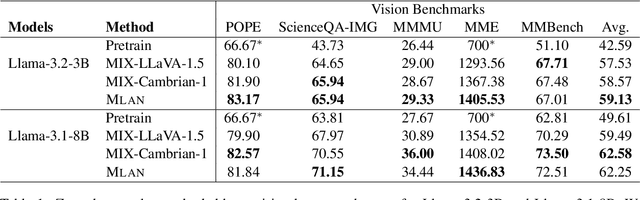
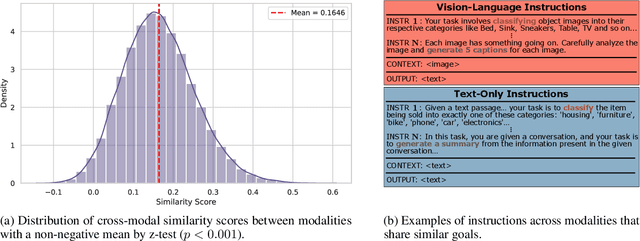
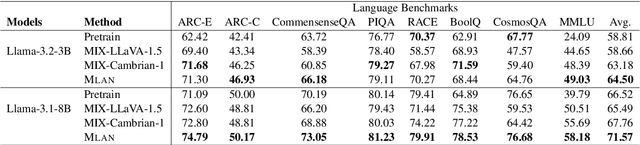
We present a novel instruction tuning recipe to improve the zero-shot task generalization of multimodal large language models. In contrast to existing instruction tuning mechanisms that heavily rely on visual instructions, our approach focuses on language-based instruction tuning, offering a distinct and more training efficient path for multimodal instruction tuning. We evaluate the performance of the proposed approach on 9 unseen datasets across both language and vision modalities. Our results show that our language-only instruction tuning is able to significantly improve the performance of two pretrained multimodal models based on Llama 2 and Vicuna on those unseen datasets. Interestingly, the language instruction following ability also helps unlock the models to follow vision instructions without explicit training. Compared to the state of the art multimodal instruction tuning approaches that are mainly based on visual instructions, our language-based method not only achieves superior performance but also significantly enhances training efficiency. For instance, the language-only instruction tuning produces competitive average performance across the evaluated datasets (with even better performance on language datasets) with significant training efficiency improvements (on average 4x), thanks to the striking reduction in the need for vision data. With a small number of visual instructions, this emerging language instruction following ability transfers well to the unseen vision datasets, outperforming the state of the art with greater training efficiency.
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Jun 07, 2024
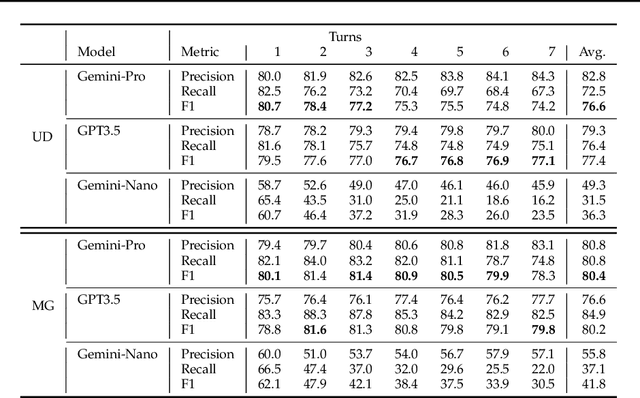
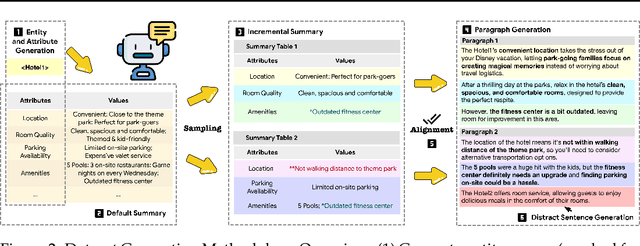
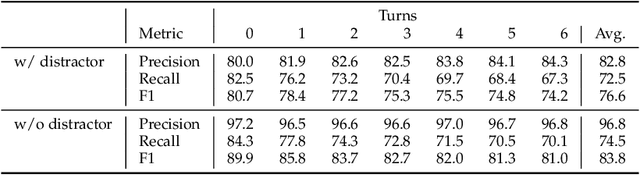
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
CASPR: Automated Evaluation Metric for Contrastive Summarization
Apr 23, 2024



Summarizing comparative opinions about entities (e.g., hotels, phones) from a set of source reviews, often referred to as contrastive summarization, can considerably aid users in decision making. However, reliably measuring the contrastiveness of the output summaries without relying on human evaluations remains an open problem. Prior work has proposed token-overlap based metrics, Distinctiveness Score, to measure contrast which does not take into account the sensitivity to meaning-preserving lexical variations. In this work, we propose an automated evaluation metric CASPR to better measure contrast between a pair of summaries. Our metric is based on a simple and light-weight method that leverages natural language inference (NLI) task to measure contrast by segmenting reviews into single-claim sentences and carefully aggregating NLI scores between them to come up with a summary-level score. We compare CASPR with Distinctiveness Score and a simple yet powerful baseline based on BERTScore. Our results on a prior dataset CoCoTRIP demonstrate that CASPR can more reliably capture the contrastiveness of the summary pairs compared to the baselines.
STRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
Data-Limited Tissue Segmentation using Inpainting-Based Self-Supervised Learning
Oct 14, 2022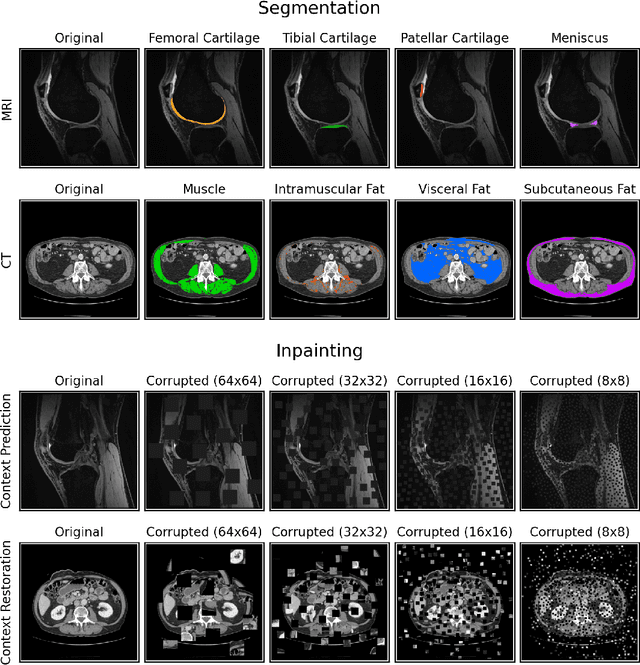
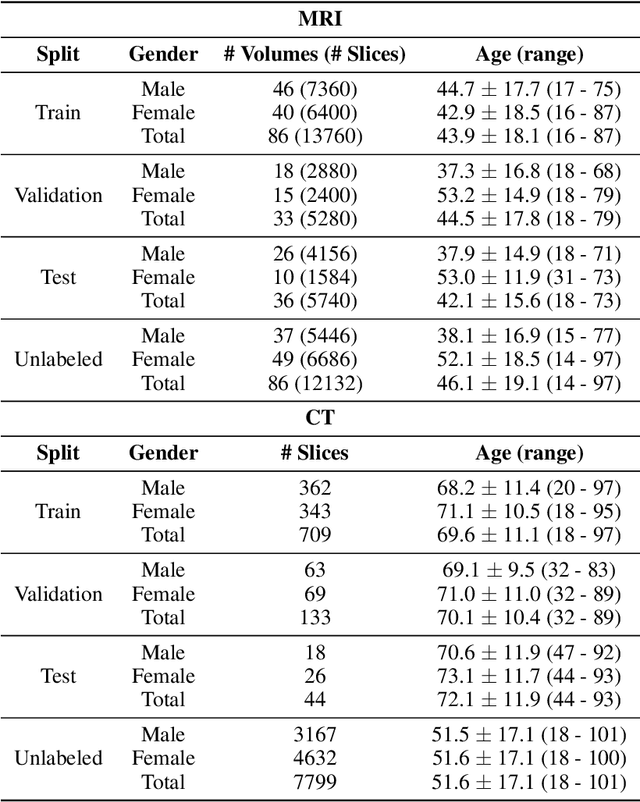
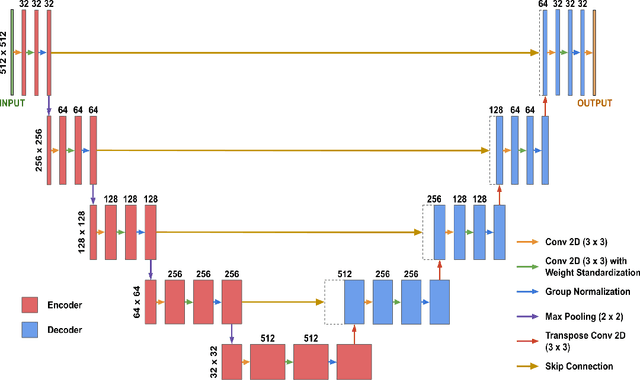
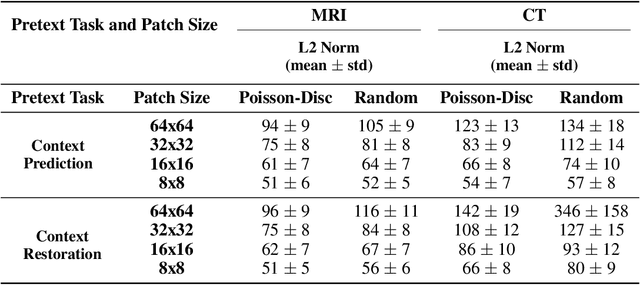
Although supervised learning has enabled high performance for image segmentation, it requires a large amount of labeled training data, which can be difficult to obtain in the medical imaging field. Self-supervised learning (SSL) methods involving pretext tasks have shown promise in overcoming this requirement by first pretraining models using unlabeled data. In this work, we evaluate the efficacy of two SSL methods (inpainting-based pretext tasks of context prediction and context restoration) for CT and MRI image segmentation in label-limited scenarios, and investigate the effect of implementation design choices for SSL on downstream segmentation performance. We demonstrate that optimally trained and easy-to-implement inpainting-based SSL segmentation models can outperform classically supervised methods for MRI and CT tissue segmentation in label-limited scenarios, for both clinically-relevant metrics and the traditional Dice score.
Scale-Equivariant Unrolled Neural Networks for Data-Efficient Accelerated MRI Reconstruction
Apr 21, 2022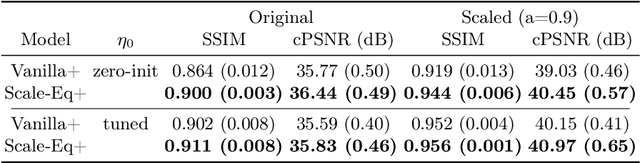
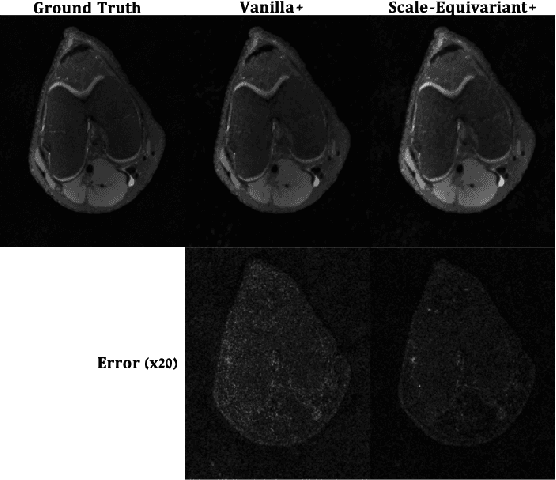
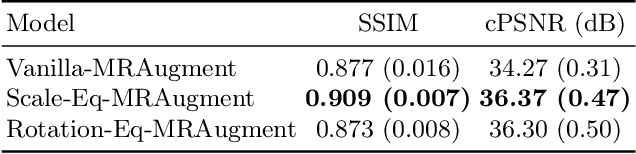
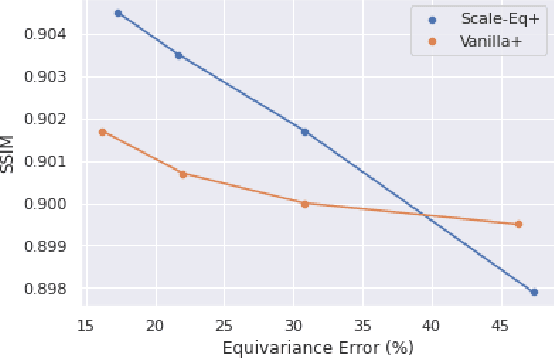
Unrolled neural networks have enabled state-of-the-art reconstruction performance and fast inference times for the accelerated magnetic resonance imaging (MRI) reconstruction task. However, these approaches depend on fully-sampled scans as ground truth data which is either costly or not possible to acquire in many clinical medical imaging applications; hence, reducing dependence on data is desirable. In this work, we propose modeling the proximal operators of unrolled neural networks with scale-equivariant convolutional neural networks in order to improve the data-efficiency and robustness to drifts in scale of the images that might stem from the variability of patient anatomies or change in field-of-view across different MRI scanners. Our approach demonstrates strong improvements over the state-of-the-art unrolled neural networks under the same memory constraints both with and without data augmentations on both in-distribution and out-of-distribution scaled images without significantly increasing the train or inference time.
Data-Efficient Information Extraction from Form-Like Documents
Jan 07, 2022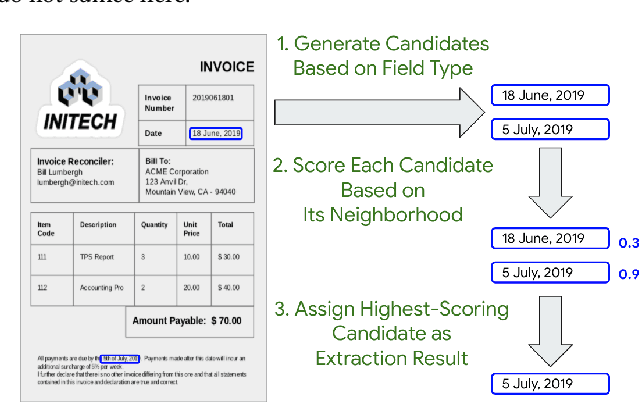
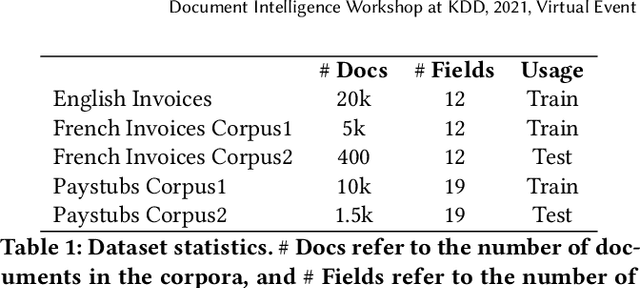
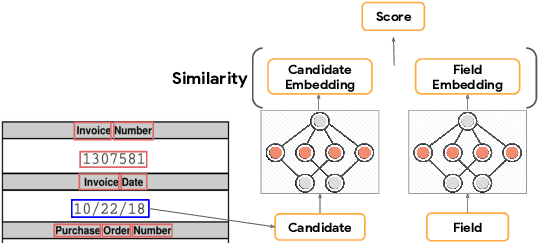
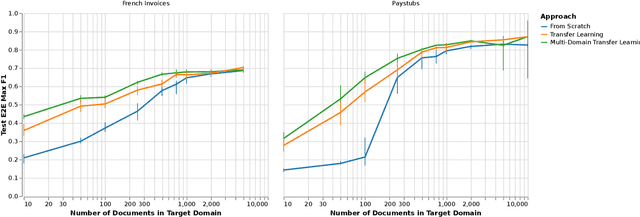
Automating information extraction from form-like documents at scale is a pressing need due to its potential impact on automating business workflows across many industries like financial services, insurance, and healthcare. The key challenge is that form-like documents in these business workflows can be laid out in virtually infinitely many ways; hence, a good solution to this problem should generalize to documents with unseen layouts and languages. A solution to this problem requires a holistic understanding of both the textual segments and the visual cues within a document, which is non-trivial. While the natural language processing and computer vision communities are starting to tackle this problem, there has not been much focus on (1) data-efficiency, and (2) ability to generalize across different document types and languages. In this paper, we show that when we have only a small number of labeled documents for training (~50), a straightforward transfer learning approach from a considerably structurally-different larger labeled corpus yields up to a 27 F1 point improvement over simply training on the small corpus in the target domain. We improve on this with a simple multi-domain transfer learning approach, that is currently in production use, and show that this yields up to a further 8 F1 point improvement. We make the case that data efficiency is critical to enable information extraction systems to scale to handle hundreds of different document-types, and learning good representations is critical to accomplishing this.
VORTEX: Physics-Driven Data Augmentations for Consistency Training for Robust Accelerated MRI Reconstruction
Nov 03, 2021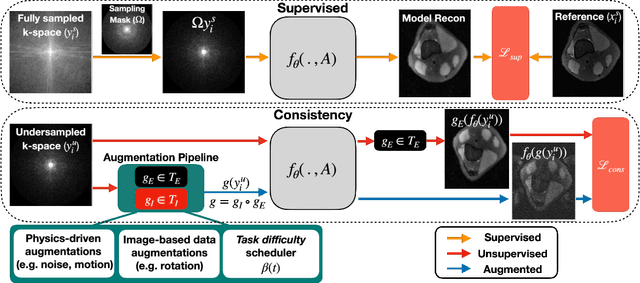
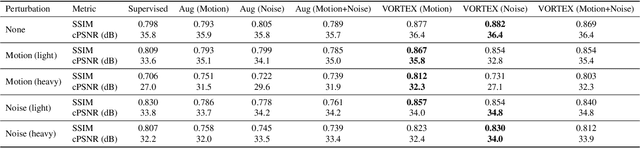
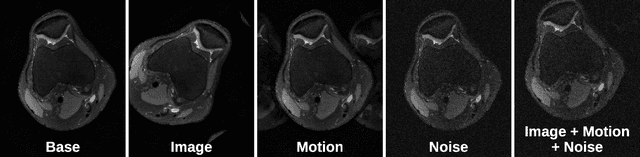
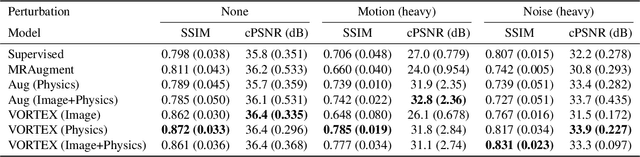
Deep neural networks have enabled improved image quality and fast inference times for various inverse problems, including accelerated magnetic resonance imaging (MRI) reconstruction. However, such models require large amounts of fully-sampled ground truth data, which are difficult to curate and are sensitive to distribution drifts. In this work, we propose applying physics-driven data augmentations for consistency training that leverage our domain knowledge of the forward MRI data acquisition process and MRI physics for improved data efficiency and robustness to clinically-relevant distribution drifts. Our approach, termed VORTEX (1) demonstrates strong improvements over supervised baselines with and without augmentation in robustness to signal-to-noise ratio change and motion corruption in data-limited regimes; (2) considerably outperforms state-of-the-art data augmentation techniques that are purely image-based on both in-distribution and out-of-distribution data; and (3) enables composing heterogeneous image-based and physics-driven augmentations.